Entity Disambiguation via Fusion Entity Decoding
2404.01626
0
0

Abstract
Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores a novel approach called "Fusion Entity Decoding" for the task of entity disambiguation, which involves identifying the correct entity that a textual mention refers to.
- The method leverages multiple entity embedding models and fuses their outputs to improve the overall performance of entity disambiguation.
- The paper presents experiments on several benchmark datasets, demonstrating the effectiveness of the proposed approach compared to existing methods.
Plain English Explanation
Entity disambiguation is an important task in natural language processing that allows computers to understand the specific individuals, organizations, or things that are being referred to in text. This is challenging because the same name can refer to multiple different entities, and context is often needed to determine the correct one.
The researchers in this paper developed a new technique called "Fusion Entity Decoding" to address this challenge. The key idea is to combine the outputs of multiple pre-trained entity embedding models, which capture different aspects of entity representations. By fusing these diverse sources of information, the model can make more accurate predictions about which entity is being referenced.
Imagine you're reading an article that mentions "Washington." Without additional context, it's unclear if this refers to the U.S. president, the state, the city, or something else. Fusion Entity Decoding would leverage multiple models trained on different types of data to narrow down the most likely intended meaning based on the surrounding text.
The researchers show that their approach outperforms previous methods on standard benchmarks for entity disambiguation. This suggests the fusion of diverse entity representations can be a powerful technique for improving natural language understanding capabilities.
Technical Explanation
The paper proposes a novel entity disambiguation framework called "Fusion Entity Decoding" (FED). The key innovation is the fusion of multiple pre-trained entity embedding models, rather than relying on a single representation.
The overall FED architecture consists of three main components:
-
Entity Encoding: This module takes a textual mention and encodes it into a vector representation using pre-trained language models like BERT.
-
Entity Retrieval: An index of entity embeddings is used to retrieve the top-k candidate entities that are most similar to the mention encoding.
-
Fusion Decoding: The outputs of multiple entity embedding models are combined using an attention-based fusion mechanism. This fused representation is then used to score and rank the candidate entities.
The intuition is that different entity embedding models may capture complementary aspects of entities, such as semantic, syntactic, and world knowledge features. By fusing these diverse representations, the model can make more informed decisions about the correct entity referent.
The authors evaluate FED on several benchmark entity disambiguation datasets, including AIDA-CoNLL, MSNBC, and AQUAINT. The results show consistent improvements over strong baselines like entity linking and entity typing models.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the FED approach, considering multiple datasets and baselines. The fusion mechanism seems like a sensible way to leverage the strengths of different entity representations.
One potential limitation is that the paper does not provide a deeper analysis of the types of entities or contexts where FED excels compared to other methods. Understanding the specific strengths and weaknesses of the approach could help guide future research.
Additionally, the fusion mechanism is relatively simple (attention-based), and exploring more sophisticated fusion techniques may lead to further performance gains. The authors acknowledge this as an area for future work.
Overall, the Fusion Entity Decoding method appears to be a promising contribution to the field of entity disambiguation, with the potential for broader applications in natural language understanding tasks.
Conclusion
This paper introduces Fusion Entity Decoding, a novel approach to entity disambiguation that combines multiple pre-trained entity representations to improve identification of the correct entity referent. The experiments demonstrate the effectiveness of this fusion-based technique compared to existing methods.
The key insight is that leveraging diverse sources of entity knowledge can lead to more accurate disambiguation decisions. This suggests that continued advancements in entity representation and fusion techniques could have significant impacts on natural language processing capabilities.
Related Papers
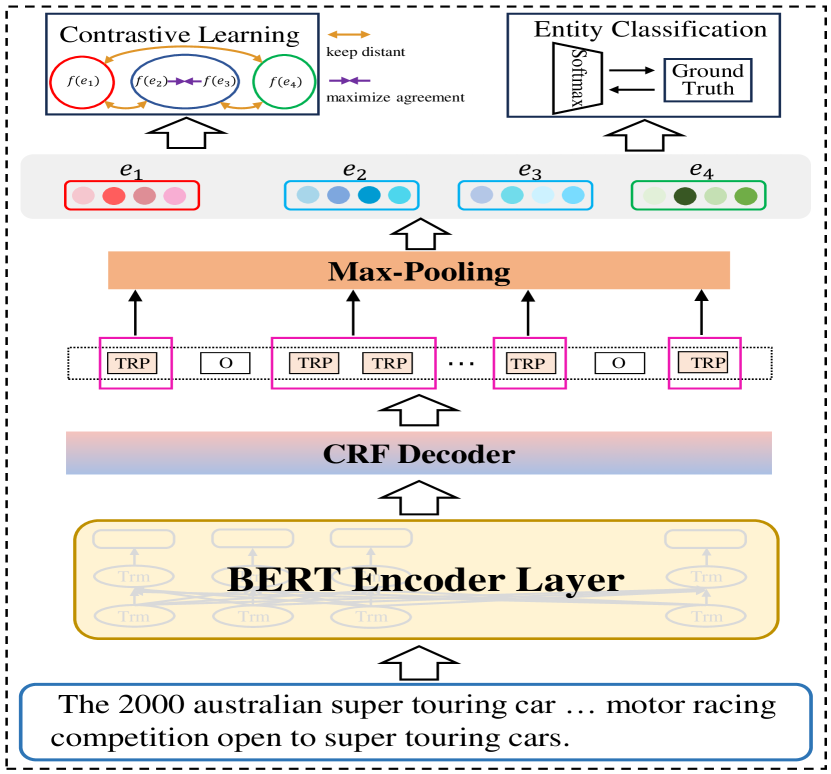
Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning
Peipei Liu, Gaosheng Wang, Ying Tong, Jian Liang, Zhenquan Ding, Hongsong Zhu
0
0
Few-shot named entity recognition can identify new types of named entities based on a few labeled examples. Previous methods employing token-level or span-level metric learning suffer from the computational burden and a large number of negative sample spans. In this paper, we propose the Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning (MsFNER), which splits the general NER into two stages: entity-span detection and entity classification. There are 3 processes for introducing MsFNER: training, finetuning, and inference. In the training process, we train and get the best entity-span detection model and the entity classification model separately on the source domain using meta-learning, where we create a contrastive learning module to enhance entity representations for entity classification. During finetuning, we finetune the both models on the support dataset of target domain. In the inference process, for the unlabeled data, we first detect the entity-spans, then the entity-spans are jointly determined by the entity classification model and the KNN. We conduct experiments on the open FewNERD dataset and the results demonstrate the advance of MsFNER.
4/11/2024
Information Retrieval with Entity Linking
Dahlia Shehata
0
0
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
4/16/2024

How to Evaluate Entity Resolution Systems: An Entity-Centric Framework with Application to Inventor Name Disambiguation
Olivier Binette, Youngsoo Baek, Siddharth Engineer, Christina Jones, Abel Dasylva, Jerome P. Reiter
0
0
Entity resolution (record linkage, microclustering) systems are notoriously difficult to evaluate. Looking for a needle in a haystack, traditional evaluation methods use sophisticated, application-specific sampling schemes to find matching pairs of records among an immense number of non-matches. We propose an alternative that facilitates the creation of representative, reusable benchmark data sets without necessitating complex sampling schemes. These benchmark data sets can then be used for model training and a variety of evaluation tasks. Specifically, we propose an entity-centric data labeling methodology that integrates with a unified framework for monitoring summary statistics, estimating key performance metrics such as cluster and pairwise precision and recall, and analyzing root causes for errors. We validate the framework in an application to inventor name disambiguation and through simulation studies. Software: https://github.com/OlivierBinette/er-evaluation/
4/9/2024
🔎
Leveraging Contextual Information for Effective Entity Salience Detection
Rajarshi Bhowmik, Marco Ponza, Atharva Tendle, Anant Gupta, Rebecca Jiang, Xingyu Lu, Qian Zhao, Daniel Preotiuc-Pietro
0
0
In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
4/4/2024