Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition

0

Sign in to get full access
Overview
- Dyn-Adapter is a novel approach to disentangled representation learning for efficient visual recognition.
- It aims to achieve parameter-efficient transfer learning by dynamically adapting a pretrained model to new tasks.
- The key ideas include using a dynamic neural network architecture and disentangled representation learning.
Plain English Explanation
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition is a research paper that introduces a new method for making machine learning models more efficient when applied to new tasks.
The core idea is to create a model that can dynamically adapt its internal structure to work well on different tasks, without requiring a lot of additional training data or parameters. This is done by learning a "disentangled" representation, where the model's knowledge is split into different components that can be selectively activated as needed.
For example, imagine a model trained to recognize different animals. Instead of having to retrain the entire model from scratch to also recognize different vehicles, the Dyn-Adapter approach would allow the model to simply activate the relevant "vehicle recognition" components while leaving the "animal recognition" components intact. This makes the model much more efficient and flexible.
The paper demonstrates how this Dyn-Adapter approach can lead to significant improvements in performance and parameter efficiency compared to standard fine-tuning techniques when applied to visual recognition tasks. By dynamically adapting the model's internal structure, it is able to achieve high accuracy with a much smaller number of trainable parameters.
Technical Explanation
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition proposes a novel approach to enable parameter-efficient transfer learning for visual recognition tasks.
The key components of the Dyn-Adapter framework include:
-
Dynamic Neural Network Architecture: The model consists of a backbone network (e.g. a Vision Transformer) and a set of dynamically activated adapter modules. These adapter modules can be selectively activated to adapt the model to different tasks, without requiring full retraining of the backbone.
-
Disentangled Representation Learning: The model is trained to learn a disentangled representation, where the knowledge is split into distinct components corresponding to different visual concepts or tasks. This allows the adapter modules to selectively activate the relevant parts of the representation for a given task.
-
Efficient Task-Specific Adaptation: During fine-tuning on a new task, only the adapter modules and a small number of task-specific parameters need to be updated, leaving the backbone network frozen. This results in significant parameter and memory efficiency compared to full model finetuning.
The authors evaluate Dyn-Adapter on several standard visual recognition benchmarks, including ImageNet, CIFAR-100, and VisDA-C. The results demonstrate that Dyn-Adapter can match or outperform traditional finetuning approaches while using significantly fewer trainable parameters.
Critical Analysis
The Dyn-Adapter paper presents a promising approach to enable parameter-efficient transfer learning for visual recognition tasks. The key strengths of the method include:
- Improved Efficiency: By only updating a small number of adapter modules and task-specific parameters, Dyn-Adapter achieves significant parameter and memory savings compared to full model finetuning.
- Disentangled Representation: The ability to learn a disentangled representation that can be selectively activated is a powerful concept that could have broader applications.
- Flexibility: The dynamic neural network architecture allows the model to be efficiently adapted to a wide range of tasks, without requiring full retraining.
However, some potential limitations and areas for further research include:
- Scalability: The paper only evaluates Dyn-Adapter on relatively small-scale datasets. Its performance and efficiency on larger, more complex tasks remains to be seen.
- Interpretability: While the disentangled representation is a key feature, the paper does not provide a detailed analysis of what these learned representations actually capture.
- Robustness: The paper does not explore the robustness of Dyn-Adapter to dataset shift or other distributional changes, which is an important consideration for real-world deployment.
Overall, Dyn-Adapter represents an interesting and promising direction in the quest for more efficient and flexible machine learning models. Further research to address the above limitations could help unlock the full potential of this approach.
Conclusion
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition introduces a novel framework for parameter-efficient transfer learning in visual recognition tasks. By leveraging a dynamic neural network architecture and disentangled representation learning, the model can be efficiently adapted to new tasks with a fraction of the parameters required for traditional finetuning.
The key contributions of this work include demonstrating significant improvements in efficiency and performance compared to standard finetuning techniques. This could have important implications for deploying machine learning models in resource-constrained environments or when data is limited.
While the paper highlights the promise of the Dyn-Adapter approach, further research is needed to fully understand its scalability, interpretability, and robustness. Nonetheless, this work represents an important step forward in the ongoing quest to develop more flexible and efficient deep learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition
Yurong Zhang, Honghao Chen, Xinyu Zhang, Xiangxiang Chu, Li Song
Parameter-efficient transfer learning (PETL) is a promising task, aiming to adapt the large-scale pre-trained model to downstream tasks with a relatively modest cost. However, current PETL methods struggle in compressing computational complexity and bear a heavy inference burden due to the complete forward process. This paper presents an efficient visual recognition paradigm, called Dynamic Adapter (Dyn-Adapter), that boosts PETL efficiency by subtly disentangling features in multiple levels. Our approach is simple: first, we devise a dynamic architecture with balanced early heads for multi-level feature extraction, along with adaptive training strategy. Second, we introduce a bidirectional sparsity strategy driven by the pursuit of powerful generalization ability. These qualities enable us to fine-tune efficiently and effectively: we reduce FLOPs during inference by 50%, while maintaining or even yielding higher recognition accuracy. Extensive experiments on diverse datasets and pretrained backbones demonstrate the potential of Dyn-Adapter serving as a general efficiency booster for PETL in vision recognition tasks.
Read more7/24/2024

0
Parameter-Efficient and Memory-Efficient Tuning for Vision Transformer: A Disentangled Approach
Taolin Zhang, Jiawang Bai, Zhihe Lu, Dongze Lian, Genping Wang, Xinchao Wang, Shu-Tao Xia
Recent works on parameter-efficient transfer learning (PETL) show the potential to adapt a pre-trained Vision Transformer to downstream recognition tasks with only a few learnable parameters. However, since they usually insert new structures into the pre-trained model, entire intermediate features of that model are changed and thus need to be stored to be involved in back-propagation, resulting in memory-heavy training. We solve this problem from a novel disentangled perspective, i.e., dividing PETL into two aspects: task-specific learning and pre-trained knowledge utilization. Specifically, we synthesize the task-specific query with a learnable and lightweight module, which is independent of the pre-trained model. The synthesized query equipped with task-specific knowledge serves to extract the useful features for downstream tasks from the intermediate representations of the pre-trained model in a query-only manner. Built upon these features, a customized classification head is proposed to make the prediction for the input sample. lightweight architecture and avoids the use of heavy intermediate features for running gradient descent, it demonstrates limited memory usage in training. Extensive experiments manifest that our method achieves state-of-the-art performance under memory constraints, showcasing its applicability in real-world situations.
Read more7/16/2024
🔄
0
Conv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets
Hao Chen, Ran Tao, Han Zhang, Yidong Wang, Xiang Li, Wei Ye, Jindong Wang, Guosheng Hu, Marios Savvides
While parameter efficient tuning (PET) methods have shown great potential with transformer architecture on Natural Language Processing (NLP) tasks, their effectiveness with large-scale ConvNets is still under-studied on Computer Vision (CV) tasks. This paper proposes Conv-Adapter, a PET module designed for ConvNets. Conv-Adapter is light-weight, domain-transferable, and architecture-agnostic with generalized performance on different tasks. When transferring on downstream tasks, Conv-Adapter learns tasks-specific feature modulation to the intermediate representations of backbones while keeping the pre-trained parameters frozen. By introducing only a tiny amount of learnable parameters, e.g., only 3.5% full fine-tuning parameters of ResNet50. It can also be applied for transformer-based backbones. Conv-Adapter outperforms previous PET baseline methods and achieves comparable or surpasses the performance of full fine-tuning on 23 classification tasks of various domains. It also presents superior performance on the few-shot classification with an average margin of 3.39%. Beyond classification, Conv-Adapter can generalize to detection and segmentation tasks with more than 50% reduction of parameters but comparable performance to the traditional full fine-tuning.
Read more4/15/2024
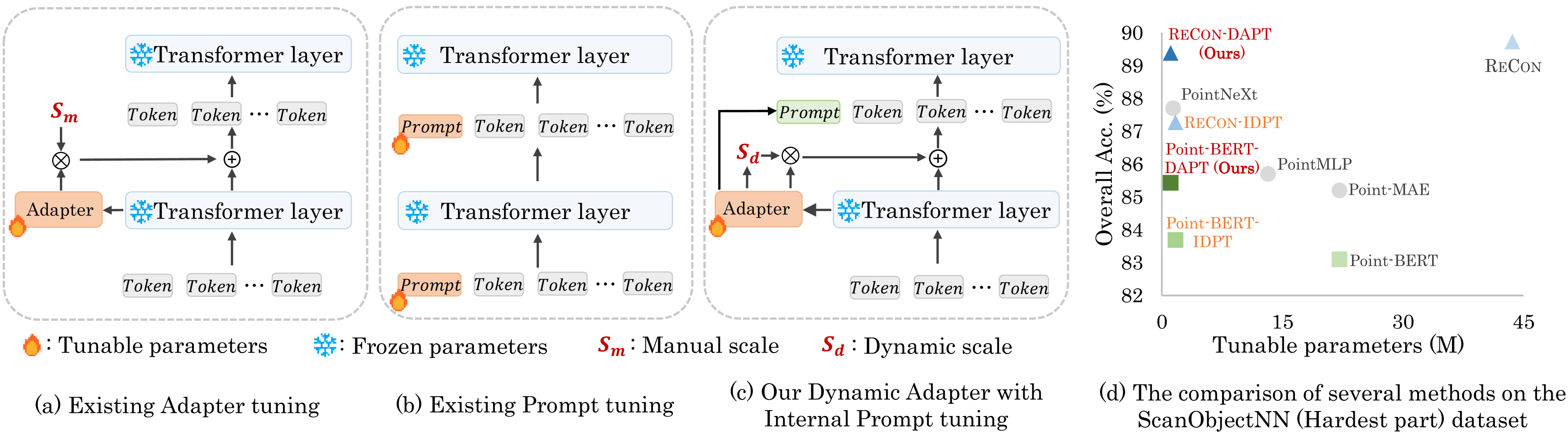
0
Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis
Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, Xiang Bai
Point cloud analysis has achieved outstanding performance by transferring point cloud pre-trained models. However, existing methods for model adaptation usually update all model parameters, i.e., full fine-tuning paradigm, which is inefficient as it relies on high computational costs (e.g., training GPU memory) and massive storage space. In this paper, we aim to study parameter-efficient transfer learning for point cloud analysis with an ideal trade-off between task performance and parameter efficiency. To achieve this goal, we freeze the parameters of the default pre-trained models and then propose the Dynamic Adapter, which generates a dynamic scale for each token, considering the token significance to the downstream task. We further seamlessly integrate Dynamic Adapter with Prompt Tuning (DAPT) by constructing Internal Prompts, capturing the instance-specific features for interaction. Extensive experiments conducted on five challenging datasets demonstrate that the proposed DAPT achieves superior performance compared to the full fine-tuning counterparts while significantly reducing the trainable parameters and training GPU memory by 95% and 35%, respectively. Code is available at https://github.com/LMD0311/DAPT.
Read more4/8/2024