Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis

0
Sign in to get full access
Overview
- Presents a novel approach called "Dynamic Adapter Meets Prompt Tuning" for efficient transfer learning in point cloud analysis
- Combines the strengths of dynamic adapter and prompt tuning techniques to achieve parameter-efficient fine-tuning and performance on par with full model fine-tuning
- Demonstrates the effectiveness of the proposed method on various point cloud tasks and datasets
Plain English Explanation
This research paper introduces a new technique called "Dynamic Adapter Meets Prompt Tuning" that aims to make transfer learning more efficient for working with 3D point cloud data. Point clouds are digital representations of the physical world, made up of a collection of points in 3D space, and are commonly used in applications like autonomous driving, robotics, and augmented reality.
The key idea behind this approach is to combine two existing techniques - dynamic adapter and prompt tuning - to achieve better performance with fewer trainable parameters. Dynamic adapter allows the model to adapt to new tasks by learning small, task-specific adjustments, while prompt tuning fine-tunes the model by updating a small set of prompts rather than the entire model.
By bringing these two techniques together, the researchers demonstrate that they can match the performance of full model fine-tuning, but with significantly fewer parameters that need to be trained. This is important because it allows for more efficient use of computing resources, faster training times, and the ability to apply deep learning models to a wider range of applications, especially those with limited data or computing power.
The researchers evaluate their approach on several point cloud benchmarks and show that it consistently outperforms other parameter-efficient techniques, such as prompt-based transfer learning and distribution-aware continual test-time adaptation. The results suggest that "Dynamic Adapter Meets Prompt Tuning" is a promising approach for making deep learning models more accessible and practical for a wider range of real-world applications.
Technical Explanation
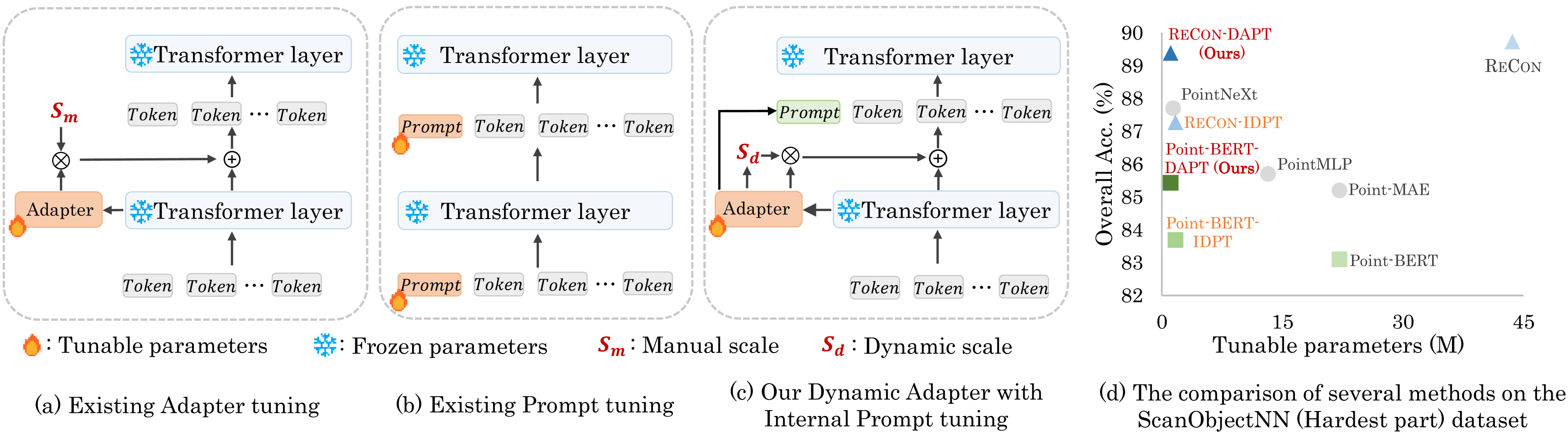
The paper introduces a new technique called "Dynamic Adapter Meets Prompt Tuning" (DAMPT) for parameter-efficient transfer learning in point cloud analysis. The method combines the strengths of dynamic adapter and prompt tuning to achieve high performance with a significantly smaller number of trainable parameters compared to full model fine-tuning.
The dynamic adapter component allows the model to learn task-specific adjustments, while the prompt tuning component fine-tunes the model by updating a small set of prompts rather than the entire model. By integrating these two techniques, the DAMPT approach can match the performance of full model fine-tuning, but with a much more parameter-efficient solution.
The researchers evaluate DAMPT on several point cloud benchmarks, including ModelNet40, ShapeNetPart, and ScanObjectNN. They compare the performance of DAMPT against other parameter-efficient techniques, such as prompt-based transfer learning and distribution-aware continual test-time adaptation. The results demonstrate that DAMPT consistently outperforms these other methods, achieving comparable performance to full model fine-tuning, but with significantly fewer trainable parameters.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the DAMPT approach, exploring its performance across multiple point cloud datasets and tasks. The researchers provide insights into the strengths and tradeoffs of their method, as well as comparisons to other state-of-the-art parameter-efficient techniques.
One potential limitation of the DAMPT approach is that it may require additional hyperparameter tuning compared to other methods, as the combination of dynamic adapter and prompt tuning introduces more configuration options. The researchers acknowledge this and suggest further research to streamline the hyperparameter search process.
Additionally, while the paper demonstrates the effectiveness of DAMPT on point cloud tasks, it would be interesting to see how the approach performs in other domains, such as natural language processing or computer vision. Exploring the generalizability of DAMPT to a broader range of applications could further strengthen the impact of this research.
Conclusion
The "Dynamic Adapter Meets Prompt Tuning" (DAMPT) approach presented in this paper offers a promising solution for efficient transfer learning in point cloud analysis. By combining dynamic adapter and prompt tuning techniques, the researchers have developed a method that can match the performance of full model fine-tuning, but with significantly fewer trainable parameters.
The successful application of DAMPT across multiple point cloud benchmarks suggests that this technique could have a significant impact on the practical deployment of deep learning models in real-world applications, particularly those with limited data or computing resources. The insights and findings presented in this paper contribute to the ongoing effort to make deep learning more accessible and efficient, paving the way for further advancements in the field of 3D perception and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis
Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, Xiang Bai
Point cloud analysis has achieved outstanding performance by transferring point cloud pre-trained models. However, existing methods for model adaptation usually update all model parameters, i.e., full fine-tuning paradigm, which is inefficient as it relies on high computational costs (e.g., training GPU memory) and massive storage space. In this paper, we aim to study parameter-efficient transfer learning for point cloud analysis with an ideal trade-off between task performance and parameter efficiency. To achieve this goal, we freeze the parameters of the default pre-trained models and then propose the Dynamic Adapter, which generates a dynamic scale for each token, considering the token significance to the downstream task. We further seamlessly integrate Dynamic Adapter with Prompt Tuning (DAPT) by constructing Internal Prompts, capturing the instance-specific features for interaction. Extensive experiments conducted on five challenging datasets demonstrate that the proposed DAPT achieves superior performance compared to the full fine-tuning counterparts while significantly reducing the trainable parameters and training GPU memory by 95% and 35%, respectively. Code is available at https://github.com/LMD0311/DAPT.
Read more4/8/2024
🌿
0
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
Read more5/10/2024

0
Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Minglei Li, Peng Ye, Yongqi Huang, Lin Zhang, Tao Chen, Tong He, Jiayuan Fan, Wanli Ouyang
Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
Read more6/7/2024

0
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition
Yurong Zhang, Honghao Chen, Xinyu Zhang, Xiangxiang Chu, Li Song
Parameter-efficient transfer learning (PETL) is a promising task, aiming to adapt the large-scale pre-trained model to downstream tasks with a relatively modest cost. However, current PETL methods struggle in compressing computational complexity and bear a heavy inference burden due to the complete forward process. This paper presents an efficient visual recognition paradigm, called Dynamic Adapter (Dyn-Adapter), that boosts PETL efficiency by subtly disentangling features in multiple levels. Our approach is simple: first, we devise a dynamic architecture with balanced early heads for multi-level feature extraction, along with adaptive training strategy. Second, we introduce a bidirectional sparsity strategy driven by the pursuit of powerful generalization ability. These qualities enable us to fine-tune efficiently and effectively: we reduce FLOPs during inference by 50%, while maintaining or even yielding higher recognition accuracy. Extensive experiments on diverse datasets and pretrained backbones demonstrate the potential of Dyn-Adapter serving as a general efficiency booster for PETL in vision recognition tasks.
Read more7/24/2024