Conv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets
2208.07463
0
0
🔄
Abstract
While parameter efficient tuning (PET) methods have shown great potential with transformer architecture on Natural Language Processing (NLP) tasks, their effectiveness with large-scale ConvNets is still under-studied on Computer Vision (CV) tasks. This paper proposes Conv-Adapter, a PET module designed for ConvNets. Conv-Adapter is light-weight, domain-transferable, and architecture-agnostic with generalized performance on different tasks. When transferring on downstream tasks, Conv-Adapter learns tasks-specific feature modulation to the intermediate representations of backbones while keeping the pre-trained parameters frozen. By introducing only a tiny amount of learnable parameters, e.g., only 3.5% full fine-tuning parameters of ResNet50. It can also be applied for transformer-based backbones. Conv-Adapter outperforms previous PET baseline methods and achieves comparable or surpasses the performance of full fine-tuning on 23 classification tasks of various domains. It also presents superior performance on the few-shot classification with an average margin of 3.39%. Beyond classification, Conv-Adapter can generalize to detection and segmentation tasks with more than 50% reduction of parameters but comparable performance to the traditional full fine-tuning.
Create account to get full access
Overview
- This paper proposes a new parameter-efficient tuning (PET) method called Conv-Adapter for convolutional neural networks (ConvNets) in computer vision tasks.
- Conv-Adapter is a lightweight, domain-transferable, and architecture-agnostic module that can be applied to both ConvNet and transformer-based backbones.
- By introducing only a small number of learnable parameters, Conv-Adapter can achieve comparable or even better performance than full fine-tuning on various classification, detection, and segmentation tasks.
Plain English Explanation
Transformer models like BERT have shown great success in natural language processing (NLP) tasks. Researchers have been exploring ways to apply similar parameter-efficient tuning (PET) techniques to computer vision (CV) tasks using convolutional neural networks (ConvNets).
The key idea behind Conv-Adapter is to learn task-specific feature modulation of the intermediate representations in a ConvNet backbone, while keeping the pre-trained parameters frozen. This allows the model to adapt to different tasks without needing to retrain the entire network from scratch. Conv-Adapter is designed to be lightweight, meaning it only adds a small number of trainable parameters (e.g., 3.5% of the full fine-tuning parameters for ResNet50).
Conv-Adapter can be applied to various ConvNet and transformer-based backbones, making it a versatile and architecture-agnostic solution. The authors show that Conv-Adapter outperforms previous PET methods and achieves comparable or even better performance than full fine-tuning on a wide range of classification, detection, and segmentation tasks.
One key advantage of Conv-Adapter is its ability to perform well on few-shot learning tasks, where the model needs to learn from a small number of examples. The authors report an average improvement of 3.39% over full fine-tuning in few-shot classification tasks.
Technical Explanation
The paper introduces Conv-Adapter, a new PET module designed for ConvNet architectures. Conv-Adapter learns task-specific feature modulation of the intermediate representations in the backbone network, while keeping the pre-trained parameters frozen.
The architecture of Conv-Adapter consists of a lightweight, fully connected neural network that takes the feature maps from the backbone as input and outputs a set of scaling and shifting parameters. These parameters are then applied to the intermediate feature maps, allowing the model to adapt to the specific task at hand.
The authors evaluate Conv-Adapter on a wide range of computer vision tasks, including image classification, object detection, and semantic segmentation. They compare its performance to both full fine-tuning and previous PET methods, such as LoRA and Adapter Tuning.
The results show that Conv-Adapter outperforms these previous PET methods and achieves comparable or even better performance than full fine-tuning, while only introducing a small number of trainable parameters (e.g., 3.5% of the full fine-tuning parameters for ResNet50). This makes Conv-Adapter a highly parameter-efficient solution for adapting ConvNet models to different tasks.
Critical Analysis
The paper presents a compelling approach to parameter-efficient fine-tuning of ConvNet models for computer vision tasks. The authors have conducted a comprehensive evaluation of Conv-Adapter across a diverse set of tasks and backbones, demonstrating its versatility and strong performance.
One potential limitation is that the paper does not provide a detailed analysis of the computational and memory efficiency of Conv-Adapter compared to full fine-tuning. While the authors report the percentage of trainable parameters, more information on the actual runtime and memory usage would be helpful to fully assess the practical benefits of this approach.
Additionally, the paper does not explore the transferability of Conv-Adapter across different domains or the ability to fine-tune on few-shot tasks in a more realistic setting (e.g., with a larger number of classes and fewer examples per class). Further research in these areas could provide additional insights into the strengths and limitations of Conv-Adapter.
Overall, the paper presents a promising direction for improving the parameter efficiency of fine-tuning ConvNet models, which could have significant implications for deploying AI models in resource-constrained environments. Readers are encouraged to critically evaluate the research and consider its potential applications and future developments.
Conclusion
This paper introduces Conv-Adapter, a novel parameter-efficient tuning (PET) module for adapting convolutional neural networks (ConvNets) to a variety of computer vision tasks. Conv-Adapter achieves strong performance by learning task-specific feature modulation of the backbone's intermediate representations, while only adding a small number of trainable parameters.
The comprehensive evaluation showcases Conv-Adapter's versatility, as it outperforms previous PET methods and matches or surpasses the performance of full fine-tuning across a wide range of classification, detection, and segmentation tasks. Its ability to perform well on few-shot learning tasks is particularly noteworthy, demonstrating its potential for applications in low-resource settings.
Overall, Conv-Adapter represents an important step forward in making fine-tuning of ConvNet models more parameter-efficient, which could have significant implications for the deployment of AI systems in real-world scenarios with limited computational resources. As the field of computer vision continues to evolve, research like this will play a crucial role in making AI models more accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Minglei Li, Peng Ye, Yongqi Huang, Lin Zhang, Tao Chen, Tong He, Jiayuan Fan, Wanli Ouyang
0
0
Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
6/7/2024
🌿
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
0
0
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
5/10/2024
🖼️
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
Raman Dutt, Linus Ericsson, Pedro Sanchez, Sotirios A. Tsaftaris, Timothy Hospedales
0
0
Foundation models have significantly advanced medical image analysis through the pre-train fine-tune paradigm. Among various fine-tuning algorithms, Parameter-Efficient Fine-Tuning (PEFT) is increasingly utilized for knowledge transfer across diverse tasks, including vision-language and text-to-image generation. However, its application in medical image analysis is relatively unexplored due to the lack of a structured benchmark for evaluating PEFT methods. This study fills this gap by evaluating 17 distinct PEFT algorithms across convolutional and transformer-based networks on image classification and text-to-image generation tasks using six medical datasets of varying size, modality, and complexity. Through a battery of over 700 controlled experiments, our findings demonstrate PEFT's effectiveness, particularly in low data regimes common in medical imaging, with performance gains of up to 22% in discriminative and generative tasks. These recommendations can assist the community in incorporating PEFT into their workflows and facilitate fair comparisons of future PEFT methods, ensuring alignment with advancements in other areas of machine learning and AI.
6/11/2024
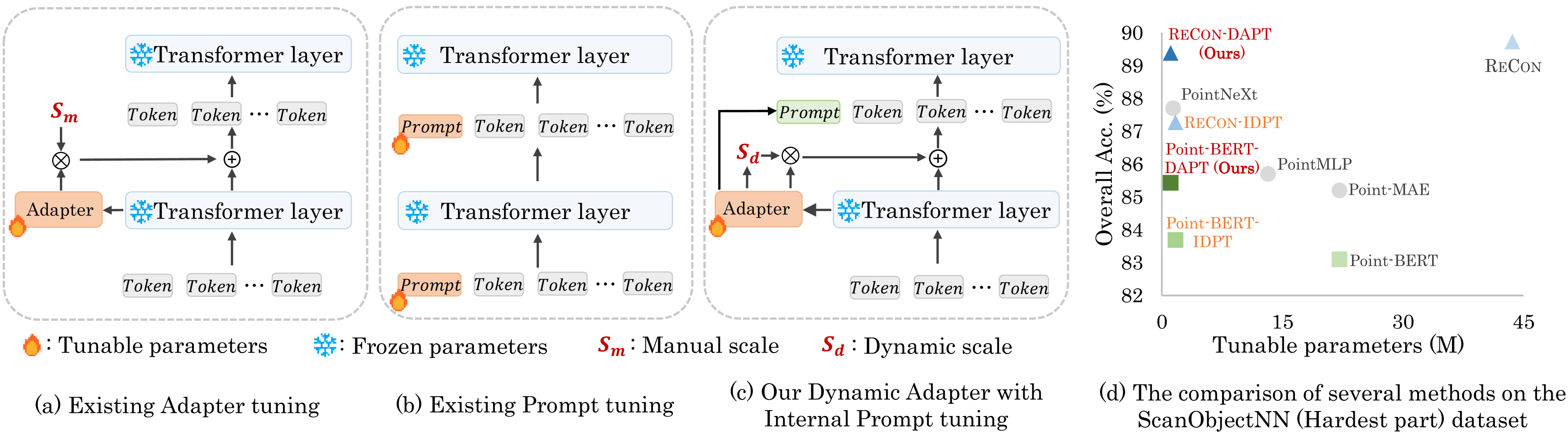
Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis
Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, Xiang Bai
0
0
Point cloud analysis has achieved outstanding performance by transferring point cloud pre-trained models. However, existing methods for model adaptation usually update all model parameters, i.e., full fine-tuning paradigm, which is inefficient as it relies on high computational costs (e.g., training GPU memory) and massive storage space. In this paper, we aim to study parameter-efficient transfer learning for point cloud analysis with an ideal trade-off between task performance and parameter efficiency. To achieve this goal, we freeze the parameters of the default pre-trained models and then propose the Dynamic Adapter, which generates a dynamic scale for each token, considering the token significance to the downstream task. We further seamlessly integrate Dynamic Adapter with Prompt Tuning (DAPT) by constructing Internal Prompts, capturing the instance-specific features for interaction. Extensive experiments conducted on five challenging datasets demonstrate that the proposed DAPT achieves superior performance compared to the full fine-tuning counterparts while significantly reducing the trainable parameters and training GPU memory by 95% and 35%, respectively. Code is available at https://github.com/LMD0311/DAPT.
4/8/2024