Dynamic and Adaptive Feature Generation with LLM
2406.03505
0
0
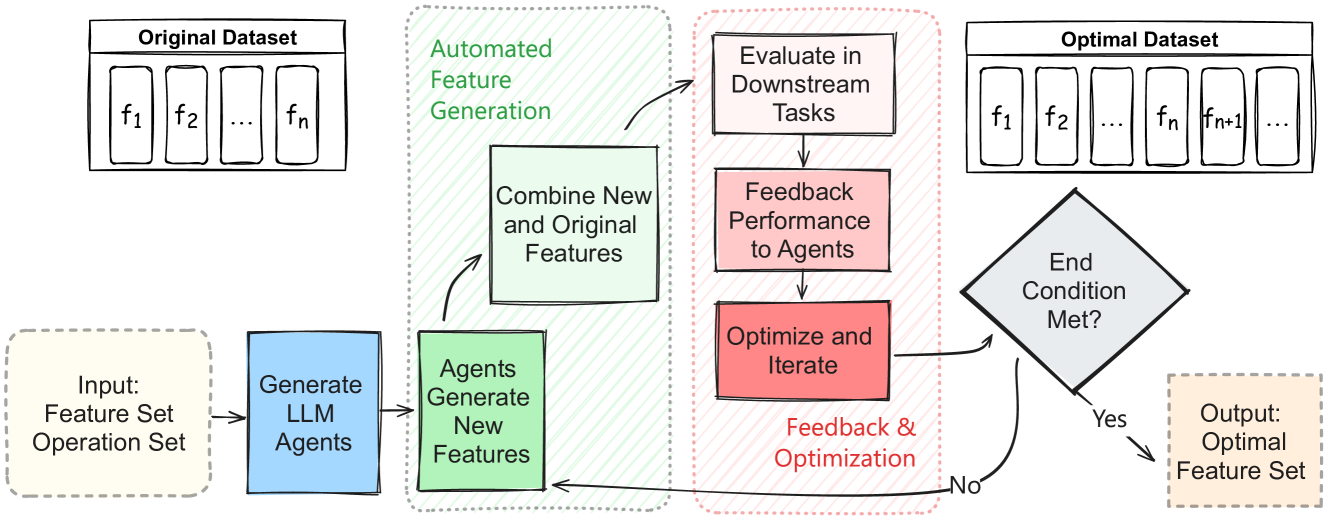
Abstract
The representation of feature space is a crucial environment where data points get vectorized and embedded for upcoming modeling. Thus the efficacy of machine learning (ML) algorithms is closely related to the quality of feature engineering. As one of the most important techniques, feature generation transforms raw data into an optimized feature space conducive to model training and further refines the space. Despite the advancements in automated feature engineering and feature generation, current methodologies often suffer from three fundamental issues: lack of explainability, limited applicability, and inflexible strategy. These shortcomings frequently hinder and limit the deployment of ML models across varied scenarios. Our research introduces a novel approach adopting large language models (LLMs) and feature-generating prompts to address these challenges. We propose a dynamic and adaptive feature generation method that enhances the interpretability of the feature generation process. Our approach broadens the applicability across various data types and tasks and draws advantages over strategic flexibility. A broad range of experiments showcases that our approach is significantly superior to existing methods.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for dynamically generating and adapting features in machine learning tasks.
- The researchers investigate techniques for LLMs to automatically engineer new features from input data, which can enhance the performance of downstream models.
- The paper builds on previous work exploring the use of LLMs for automated feature engineering, as well as research on leveraging knowledge graphs for interpretable feature generation.
Plain English Explanation
The researchers in this paper are looking at how large language models (LLMs) can be used to automatically create and adjust new features from input data. Features are the characteristics of the data that machine learning models use to make predictions. Typically, engineers have to manually engineer these features, which can be time-consuming and require domain expertise.
The key idea is that LLMs, like GPT-3, can analyze the input data and dynamically generate new features that might be useful for downstream machine learning tasks. This could make it easier to build effective models, even for problems where the right features aren't obvious. The paper builds on previous work showing that LLMs can be used for automated feature engineering and generating interpretable features.
The goal is to make machine learning more accessible by reducing the need for manual feature engineering, which can be a bottleneck. If LLMs can handle this automatically, it could help large language models automatically engineer features and enhance algorithm selection for a variety of applications, potentially even game generation.
Technical Explanation
The paper proposes a framework for using LLMs to dynamically generate and adapt features for machine learning tasks. The approach involves using an LLM to analyze the input data and automatically construct new features that could be useful for the target prediction problem.
The researchers experimented with different LLM-based feature generation techniques, including:
- Extracting relevant concepts, entities, and relationships from the input data
- Generating novel feature combinations and transformations
- Adapting the feature set based on feedback from the downstream model performance
They evaluated the LLM-generated features on a range of benchmark datasets and found that they could outperform manually engineered features, as well as features generated by other automated techniques.
The key technical insights from the paper include:
- LLMs can effectively capture complex semantic and contextual information from raw input data
- Dynamic feature generation can adapt the feature set to the specific problem and data at hand
- Integrating the LLM-based feature generation with the downstream model training can provide further performance gains
Critical Analysis
The paper presents a promising approach for leveraging LLMs to automate the feature engineering process, which could make machine learning more accessible and effective across a variety of domains. However, the research also raises some important caveats and areas for further exploration.
One limitation is that the performance of the LLM-generated features still depends on the quality and coverage of the language model, which can be biased or limited in certain areas. The paper acknowledges that further work is needed to ensure the features are unbiased and generalizable.
Additionally, the dynamic feature generation process adds computational complexity, and the interpretability of the resulting features may be a challenge. The paper suggests incorporating interpretable feature generation techniques to address this, but more research is needed.
Another potential issue is the reliance on specific LLM architectures and training procedures, which may limit the generalizability of the approach. Exploring the use of different large language models for this task could yield further insights.
Overall, the research represents an exciting step forward in automating feature engineering, but additional work is needed to fully address the challenges and limitations identified in the paper.
Conclusion
This paper presents a novel approach for using large language models (LLMs) to dynamically generate and adapt features for machine learning tasks. The key idea is that LLMs can analyze input data and automatically construct new features that could be useful for downstream prediction problems, reducing the need for manual feature engineering.
The researchers experimented with various LLM-based feature generation techniques and found that the automatically generated features could outperform manually engineered features and other automated approaches. This work builds on previous research exploring the use of LLMs for automated feature engineering and interpretable feature generation.
The findings suggest that integrating LLM-based feature generation with machine learning models could make the development of effective predictive systems more accessible, by reducing the need for time-consuming manual feature engineering. This could have important implications across a wide range of applications, from algorithm selection to game generation.
However, the research also highlights several important challenges and limitations that require further exploration, such as ensuring the generated features are unbiased and interpretable. Overall, this work represents an important step forward in automating feature engineering using large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
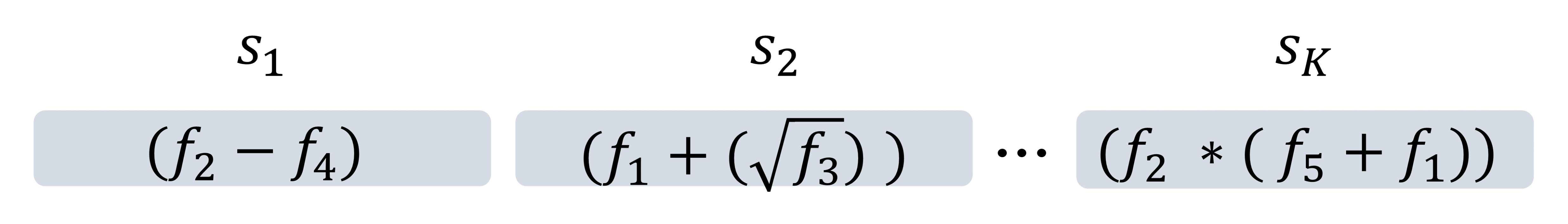
Evolutionary Large Language Model for Automated Feature Transformation
Nanxu Gong, Chandan K. Reddy, Wangyang Ying, Yanjie Fu
0
0
Feature transformation aims to reconstruct the feature space of raw features to enhance the performance of downstream models. However, the exponential growth in the combinations of features and operations poses a challenge, making it difficult for existing methods to efficiently explore a wide space. Additionally, their optimization is solely driven by the accuracy of downstream models in specific domains, neglecting the acquisition of general feature knowledge. To fill this research gap, we propose an evolutionary LLM framework for automated feature transformation. This framework consists of two parts: 1) constructing a multi-population database through an RL data collector while utilizing evolutionary algorithm strategies for database maintenance, and 2) utilizing the ability of Large Language Model (LLM) in sequence understanding, we employ few-shot prompts to guide LLM in generating superior samples based on feature transformation sequence distinction. Leveraging the multi-population database initially provides a wide search scope to discover excellent populations. Through culling and evolution, the high-quality populations are afforded greater opportunities, thereby furthering the pursuit of optimal individuals. Through the integration of LLMs with evolutionary algorithms, we achieve efficient exploration within a vast space, while harnessing feature knowledge to propel optimization, thus realizing a more adaptable search paradigm. Finally, we empirically demonstrate the effectiveness and generality of our proposed method.
5/28/2024

Leveraging Knowlegde Graphs for Interpretable Feature Generation
Mohamed Bouadi, Arta Alavi, Salima Benbernou, Mourad Ouziri
0
0
The quality of Machine Learning (ML) models strongly depends on the input data, as such Feature Engineering (FE) is often required in ML. In addition, with the proliferation of ML-powered systems, especially in critical contexts, the need for interpretability and explainability becomes increasingly important. Since manual FE is time-consuming and requires case specific knowledge, we propose KRAFT, an AutoFE framework that leverages a knowledge graph to guide the generation of interpretable features. Our hybrid AI approach combines a neural generator to transform raw features through a series of transformations and a knowledge-based reasoner to evaluate features interpretability using Description Logics (DL). The generator is trained through Deep Reinforcement Learning (DRL) to maximize the prediction accuracy and the interpretability of the generated features. Extensive experiments on real datasets demonstrate that KRAFT significantly improves accuracy while ensuring a high level of interpretability.
6/4/2024
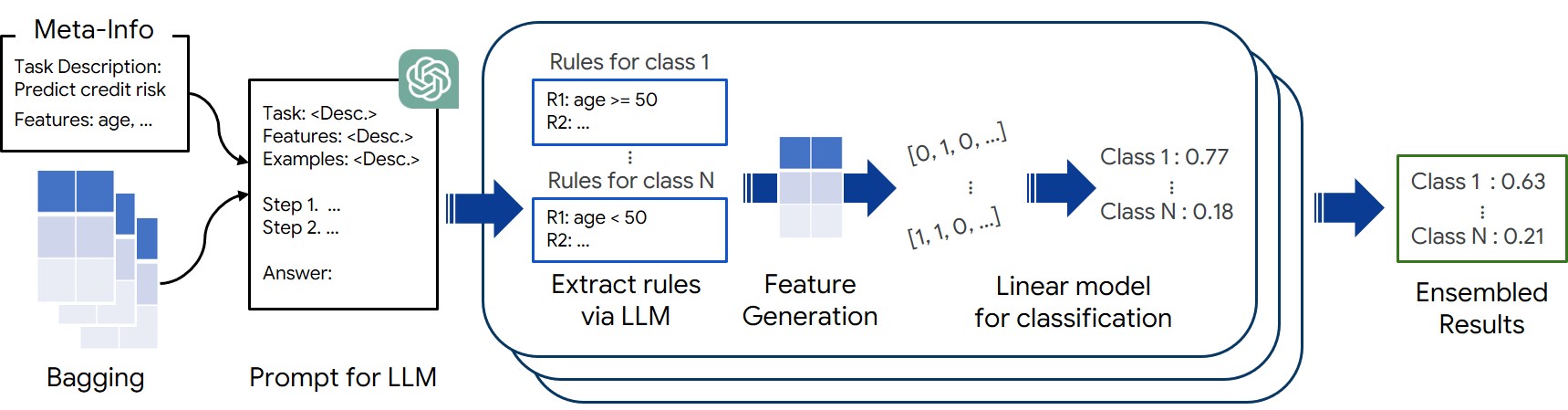
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, Tomas Pfister
0
0
Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
5/7/2024
✨
Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, Jinwoo Shin
0
0
Learning effective representations from raw data is crucial for the success of deep learning methods. However, in the tabular domain, practitioners often prefer augmenting raw column features over using learned representations, as conventional tree-based algorithms frequently outperform competing approaches. As a result, feature engineering methods that automatically generate candidate features have been widely used. While these approaches are often effective, there remains ambiguity in defining the space over which to search for candidate features. Moreover, they often rely solely on validation scores to select good features, neglecting valuable feedback from past experiments that could inform the planning of future experiments. To address the shortcomings, we propose a new tabular learning framework based on large language models (LLMs), coined Optimizing Column feature generator with decision Tree reasoning (OCTree). Our key idea is to leverage LLMs' reasoning capabilities to find good feature generation rules without manually specifying the search space and provide language-based reasoning information highlighting past experiments as feedback for iterative rule improvements. Here, we choose a decision tree as reasoning as it can be interpreted in natural language, effectively conveying knowledge of past experiments (i.e., the prediction models trained with the generated features) to the LLM. Our empirical results demonstrate that this simple framework consistently enhances the performance of various prediction models across diverse tabular benchmarks, outperforming competing automatic feature engineering methods.
6/14/2024