Dynamic data sampler for cross-language transfer learning in large language models

0
Sign in to get full access
Overview
- Introduces a dynamic data sampling technique for cross-language transfer learning in large language models
- Aims to improve performance on downstream tasks in low-resource languages by leveraging abundant data from high-resource languages
- Proposes a novel method for dynamically sampling data from multiple languages during training to encourage the model to learn universal representations
Plain English Explanation
The paper presents a technique called dynamic data sampling that can help large language models perform better on tasks in low-resource languages. Large language models are trained on massive amounts of text data, mostly in high-resource languages like English. This can make it challenging for the models to perform well on tasks in low-resource languages, where there is much less available training data.
The key idea behind the dynamic data sampling approach is to actively balance the training data from different languages during the model's training process. Instead of just feeding the model a fixed amount of data from each language, the technique dynamically adjusts the sampling probabilities to focus more on the low-resource languages. This encourages the model to learn universal representations that can transfer effectively to these underrepresented languages.
By using this dynamic sampling method, the researchers aim to leverage the abundant data from high-resource languages to boost the model's performance on downstream tasks in low-resource languages. This could be particularly useful for applications like machine translation, question answering, and other cross-lingual natural language processing tasks.
Technical Explanation
The paper introduces a dynamic data sampler for training large language models in a cross-lingual setting. The core of the approach is to dynamically adjust the sampling probabilities for each language during the training process, rather than using a fixed sampling strategy.
Specifically, the method works as follows:
- Initialize the sampling probability for each language proportional to the amount of available training data.
- During training, periodically update the sampling probabilities based on the current performance of the model on each language.
- Increase the sampling probability for languages where the model is performing poorly, and decrease the probability for languages where the model is performing well.
This dynamic sampling encourages the model to focus more on the low-resource languages, helping it learn universal representations that transfer better across languages. The authors hypothesize that this will lead to improved performance on downstream tasks in low-resource languages.
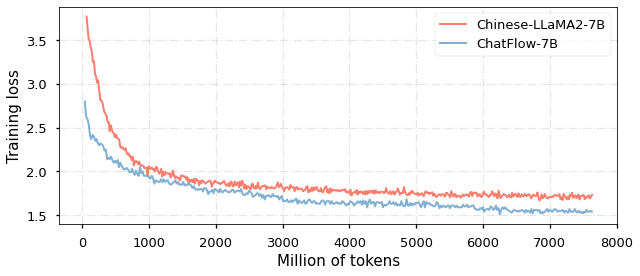
The paper evaluates the dynamic data sampler on several benchmark datasets for cross-lingual understanding and generation tasks. The results demonstrate that the proposed approach outperforms static sampling baselines, particularly for low-resource target languages. The authors also provide insights into the training dynamics and the learned representations.
Critical Analysis
The dynamic data sampling approach presented in this paper is a novel and promising technique for improving the cross-lingual performance of large language models. By actively balancing the training data from different languages, the method encourages the model to learn more universal representations that can transfer better to low-resource languages.
One potential limitation of the approach is that it relies on having some initial performance data for each language to guide the dynamic sampling. In real-world scenarios, there may be cases where little or no performance data is available for certain low-resource languages, making it challenging to apply the technique effectively.
Additionally, the paper does not explore the long-term implications of the dynamic sampling strategy. It would be valuable to investigate whether the learned representations remain stable and continue to transfer well as the model is fine-tuned or used in different contexts over time.
Further research could also look into ways to integrate the dynamic sampling approach with other cross-lingual techniques, such as multilingual prompting or specialized architectures, to potentially achieve even greater performance gains on low-resource language tasks.
Conclusion
The dynamic data sampling method presented in this paper is a promising approach for improving the cross-lingual performance of large language models. By actively balancing the training data from different languages, the technique encourages the model to learn more universal representations that can transfer effectively to low-resource languages.
The results demonstrate the effectiveness of this approach, particularly for downstream tasks in underrepresented languages. While there are some potential limitations and areas for further research, the dynamic data sampler represents an important step forward in addressing the challenge of cross-lingual language modeling.
As large language models continue to play a growing role in a wide range of applications, techniques like this that can improve their performance on low-resource languages will become increasingly valuable for ensuring equitable and inclusive access to these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic data sampler for cross-language transfer learning in large language models
Yudong Li, Yuhao Feng, Wen Zhou, Zhe Zhao, Linlin Shen, Cheng Hou, Xianxu Hou
Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
Read more5/20/2024
0
Why Not Transform Chat Large Language Models to Non-English?
Xiang Geng, Ming Zhu, Jiahuan Li, Zhejian Lai, Wei Zou, Shuaijie She, Jiaxin Guo, Xiaofeng Zhao, Yinglu Li, Yuang Li, Chang Su, Yanqing Zhao, Xinglin Lyu, Min Zhang, Jiajun Chen, Hao Yang, Shujian Huang
The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
Read more6/3/2024
💬
0
Large Language Models are Good Multi-lingual Learners : When LLMs Meet Cross-lingual Prompts
Teng Wang, Zhenqi He, Wing-Yin Yu, Xiaojin Fu, Xiongwei Han
With the advent of Large Language Models (LLMs), generating rule-based data for real-world applications has become more accessible. Due to the inherent ambiguity of natural language and the complexity of rule sets, especially in long contexts, LLMs often struggle to follow all specified rules, frequently omitting at least one. To enhance the reasoning and understanding of LLMs on long and complex contexts, we propose a novel prompting strategy Multi-Lingual Prompt, namely MLPrompt, which automatically translates the error-prone rule that an LLM struggles to follow into another language, thus drawing greater attention to it. Experimental results on public datasets across various tasks have shown MLPrompt can outperform state-of-the-art prompting methods such as Chain of Thought, Tree of Thought, and Self-Consistency. Additionally, we introduce a framework integrating MLPrompt with an auto-checking mechanism for structured data generation, with a specific case study in text-to-MIP instances. Further, we extend the proposed framework for text-to-SQL to demonstrate its generation ability towards structured data synthesis.
Read more9/18/2024

0
Boosting Zero-Shot Crosslingual Performance using LLM-Based Augmentations with Effective Data Selection
Barah Fazili, Ashish Sunil Agrawal, Preethi Jyothi
Large language models (LLMs) are very proficient text generators. We leverage this capability of LLMs to generate task-specific data via zero-shot prompting and promote cross-lingual transfer for low-resource target languages. Given task-specific data in a source language and a teacher model trained on this data, we propose using this teacher to label LLM generations and employ a set of simple data selection strategies that use the teacher's label probabilities. Our data selection strategies help us identify a representative subset of diverse generations that help boost zero-shot accuracies while being efficient, in comparison to using all the LLM generations (without any subset selection). We also highlight other important design choices that affect cross-lingual performance such as the use of translations of source data and what labels are best to use for the LLM generations. We observe significant performance gains across sentiment analysis and natural language inference tasks (of up to a maximum of 7.13 absolute points and 1.5 absolute points on average) across a number of target languages (Hindi, Marathi, Urdu, Swahili) and domains.
Read more7/16/2024