Why Not Transform Chat Large Language Models to Non-English?

0
💬
Sign in to get full access
Overview
- The scarcity of non-English data limits the development of non-English large language models (LLMs).
- Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method.
- Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g., GPT-4.
- Chat LLMs are further optimized for advanced abilities, e.g., multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety.
- Transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation?
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform a variety of language-related tasks. However, the majority of these models have been developed using English data, which limits their ability to work with other languages.
One solution to this problem is to take an existing English-based LLM and transform it to work with a different language, such as Thai. This is a more efficient approach than building a brand-new model from scratch for each language.
Previous methods have taken a base LLM and used a technique called knowledge distillation to teach it new abilities, using data generated by even more powerful LLMs like GPT-4. However, these methods have focused on transforming "base" LLMs, which are not as advanced as the "chat" LLMs that have been further optimized for tasks like multi-turn conversations and aligning with human preferences.
Transforming a chat LLM presents two key challenges: [1] How can we effectively transfer the advanced abilities of the chat LLM without access to the supervised data used to train those abilities? [2] How can we prevent the original knowledge of the LLM from being forgotten during the transformation process?
Technical Explanation
The researchers introduce a framework called TransLLM to address these challenges. For the first issue, TransLLM breaks down the transfer problem into common sub-tasks, using translation as a bridge between the English and non-English models. The performance of these sub-tasks is further enhanced using publicly available data.
For the second issue, TransLLM uses two synergistic components: low-rank adaptation and recovery knowledge distillation (KD). Low-rank adaptation allows the model to be trained while maintaining the original LLM parameters. Recovery KD then utilizes data generated by the chat LLM itself to recover the original knowledge from these frozen parameters.
In experiments, the researchers transformed the LLaMA-2-chat-7B model to the Thai language. Their method, using only single-turn data, outperformed strong baselines and even ChatGPT on a multi-turn benchmark called MT-bench. Furthermore, their method, without any safety data, rejected more harmful queries on a safety benchmark called AdvBench than both ChatGPT and GPT-4.
Critical Analysis
The researchers acknowledge that their method relies on the availability of some single-turn data in the target language, which may not always be the case. Additionally, they note that their approach focuses on transforming a chat LLM, but it may not be as effective for transforming other types of LLMs, such as those optimized for specific tasks like question answering or language generation.
While the researchers demonstrate impressive results on the MT-bench and AdvBench benchmarks, it would be valuable to see the model's performance on a wider range of tasks and in real-world applications to better understand its capabilities and limitations.
Conclusion
This research presents a promising framework, called TransLLM, for transforming English-centric chat LLMs to work with non-English languages. By addressing the challenges of transferring advanced abilities and preventing catastrophic forgetting, the researchers have developed a method that outperforms strong baselines and even some of the most advanced language models currently available.
This work could have significant implications for making powerful language models more accessible to users around the world, regardless of their primary language. As the field of natural language processing continues to evolve, techniques like those introduced in this paper will be crucial for building truly multilingual and inclusive AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Why Not Transform Chat Large Language Models to Non-English?
Xiang Geng, Ming Zhu, Jiahuan Li, Zhejian Lai, Wei Zou, Shuaijie She, Jiaxin Guo, Xiaofeng Zhao, Yinglu Li, Yuang Li, Chang Su, Yanqing Zhao, Xinglin Lyu, Min Zhang, Jiajun Chen, Hao Yang, Shujian Huang
The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
Read more6/3/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024

0
Quo Vadis ChatGPT? From Large Language Models to Large Knowledge Models
Venkat Venkatasubramanian, Arijit Chakraborty
The startling success of ChatGPT and other large language models (LLMs) using transformer-based generative neural network architecture in applications such as natural language processing and image synthesis has many researchers excited about potential opportunities in process systems engineering (PSE). The almost human-like performance of LLMs in these areas is indeed very impressive, surprising, and a major breakthrough. Their capabilities are very useful in certain tasks, such as writing first drafts of documents, code writing assistance, text summarization, etc. However, their success is limited in highly scientific domains as they cannot yet reason, plan, or explain due to their lack of in-depth domain knowledge. This is a problem in domains such as chemical engineering as they are governed by fundamental laws of physics and chemistry (and biology), constitutive relations, and highly technical knowledge about materials, processes, and systems. Although purely data-driven machine learning has its immediate uses, the long-term success of AI in scientific and engineering domains would depend on developing hybrid AI systems that use first principles and technical knowledge effectively. We call these hybrid AI systems Large Knowledge Models (LKMs), as they will not be limited to only NLP-based techniques or NLP-like applications. In this paper, we discuss the challenges and opportunities in developing such systems in chemical engineering.
Read more5/31/2024
0
Dynamic data sampler for cross-language transfer learning in large language models
Yudong Li, Yuhao Feng, Wen Zhou, Zhe Zhao, Linlin Shen, Cheng Hou, Xianxu Hou
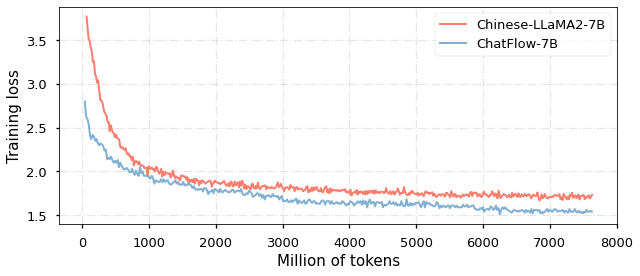
Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
Read more5/20/2024