Boosting Zero-Shot Crosslingual Performance using LLM-Based Augmentations with Effective Data Selection

0

Sign in to get full access
Overview
- The paper explores techniques to improve the performance of large language models (LLMs) in zero-shot crosslingual tasks, where the model is evaluated on a language it was not trained on.
- The researchers propose using data augmentation techniques based on LLMs to generate synthetic data, along with an effective data selection method to choose the most useful augmented examples.
- The goal is to boost the zero-shot crosslingual performance of LLMs without requiring additional labeled data in the target language.
Plain English Explanation
The paper is focused on making large language models (LLMs) better at handling tasks in languages they haven't been trained on directly. This is called "zero-shot crosslingual" performance, where the model has to work with a language it hasn't seen before.
The researchers tried two main things to improve this zero-shot performance:
-
Data Augmentation: They used the LLM itself to generate new, synthetic training examples in the target language. This helps expose the model to more linguistic diversity during training.
-
Data Selection: They developed a method to carefully select which of the synthetic examples are most useful for improving the model's crosslingual abilities. This ensures the training data is as relevant and helpful as possible.
The goal is to get the LLM to perform well on tasks in languages it hasn't been explicitly trained on, without requiring lots of additional labeled data in those languages. This could make these models more useful for a wider range of real-world applications.
Technical Explanation
The paper proposes a two-step approach to boost the zero-shot crosslingual performance of LLMs:
-
LLM-Based Data Augmentation: The researchers leverage the language understanding capabilities of LLMs to generate synthetic training data in the target language. They use prompt engineering techniques to instruct the LLM to produce pseudolabeled examples that match the task and domain of interest.
-
Effective Data Selection: To ensure the augmented data is most useful for improving zero-shot crosslingual performance, the authors develop a data selection method. This involves evaluating the quality and diversity of the synthetic examples and choosing a subset that provides the greatest benefit when combined with the original training data.
The authors evaluate their approach on several crosslingual benchmark tasks, including XNLI and PAWS-X. They demonstrate significant improvements in zero-shot crosslingual performance compared to baseline methods that do not use their data augmentation and selection techniques.
Critical Analysis
The paper presents a promising approach to boosting the zero-shot crosslingual capabilities of LLMs. However, the authors acknowledge several limitations and areas for future work:
- The effectiveness of the data augmentation and selection methods may depend on the specific task and language pair, so further experimentation is needed to understand the generalizability of the approach.
- The authors only evaluate on relatively high-resource language pairs, and it's unclear how well the techniques would perform for truly low-resource languages with limited training data.
- The computational and memory overhead of the data augmentation process could be prohibitive for some real-world applications, so further optimizations may be necessary.
Additionally, while the authors demonstrate improved performance on the evaluated benchmark tasks, it's important to consider how well these improvements would translate to real-world applications with unique challenges and requirements. Careful consideration of the model's limitations and potential biases is crucial when deploying such systems.
Conclusion
This paper presents an innovative approach to boosting the zero-shot crosslingual performance of large language models. By leveraging LLM-based data augmentation and effective data selection techniques, the researchers are able to significantly improve the models' ability to handle tasks in languages they haven't been explicitly trained on.
This work has the potential to make LLMs more useful and accessible for a wider range of real-world applications that require crosslingual capabilities, reducing the need for expensive labeled data collection and manual model fine-tuning. As the research in this area continues to evolve, it will be important to carefully consider the limitations and potential biases of these techniques to ensure they are deployed responsibly and equitably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boosting Zero-Shot Crosslingual Performance using LLM-Based Augmentations with Effective Data Selection
Barah Fazili, Ashish Sunil Agrawal, Preethi Jyothi
Large language models (LLMs) are very proficient text generators. We leverage this capability of LLMs to generate task-specific data via zero-shot prompting and promote cross-lingual transfer for low-resource target languages. Given task-specific data in a source language and a teacher model trained on this data, we propose using this teacher to label LLM generations and employ a set of simple data selection strategies that use the teacher's label probabilities. Our data selection strategies help us identify a representative subset of diverse generations that help boost zero-shot accuracies while being efficient, in comparison to using all the LLM generations (without any subset selection). We also highlight other important design choices that affect cross-lingual performance such as the use of translations of source data and what labels are best to use for the LLM generations. We observe significant performance gains across sentiment analysis and natural language inference tasks (of up to a maximum of 7.13 absolute points and 1.5 absolute points on average) across a number of target languages (Hindi, Marathi, Urdu, Swahili) and domains.
Read more7/16/2024

0
Bridging the Language Gap: Enhancing Multilingual Prompt-Based Code Generation in LLMs via Zero-Shot Cross-Lingual Transfer
Mingda Li, Abhijit Mishra, Utkarsh Mujumdar
The use of Large Language Models (LLMs) for program code generation has gained substantial attention, but their biases and limitations with non-English prompts challenge global inclusivity. This paper investigates the complexities of multilingual prompt-based code generation. Our evaluations of LLMs, including CodeLLaMa and CodeGemma, reveal significant disparities in code quality for non-English prompts; we also demonstrate the inadequacy of simple approaches like prompt translation, bootstrapped data augmentation, and fine-tuning. To address this, we propose a zero-shot cross-lingual approach using a neural projection technique, integrating a cross-lingual encoder like LASER artetxe2019massively to map multilingual embeddings from it into the LLM's token space. This method requires training only on English data and scales effectively to other languages. Results on a translated and quality-checked MBPP dataset show substantial improvements in code quality. This research promotes a more inclusive code generation landscape by empowering LLMs with multilingual capabilities to support the diverse linguistic spectrum in programming.
Read more8/20/2024
0
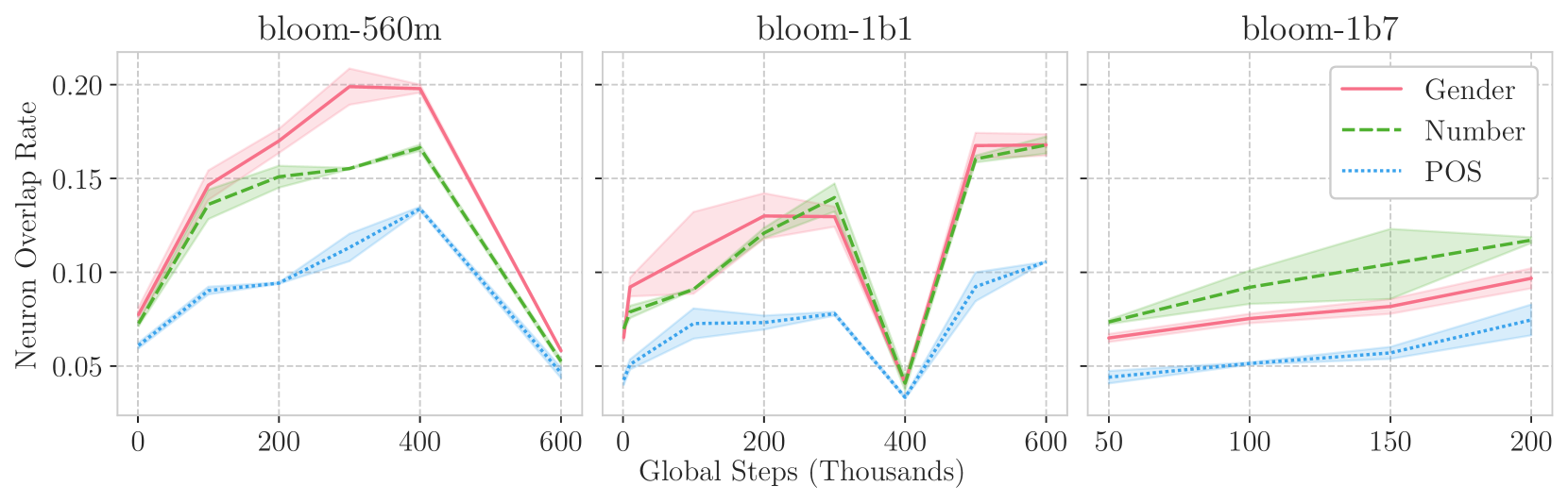
Probing the Emergence of Cross-lingual Alignment during LLM Training
Hetong Wang, Pasquale Minervini, Edoardo M. Ponti
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
Read more6/21/2024
0
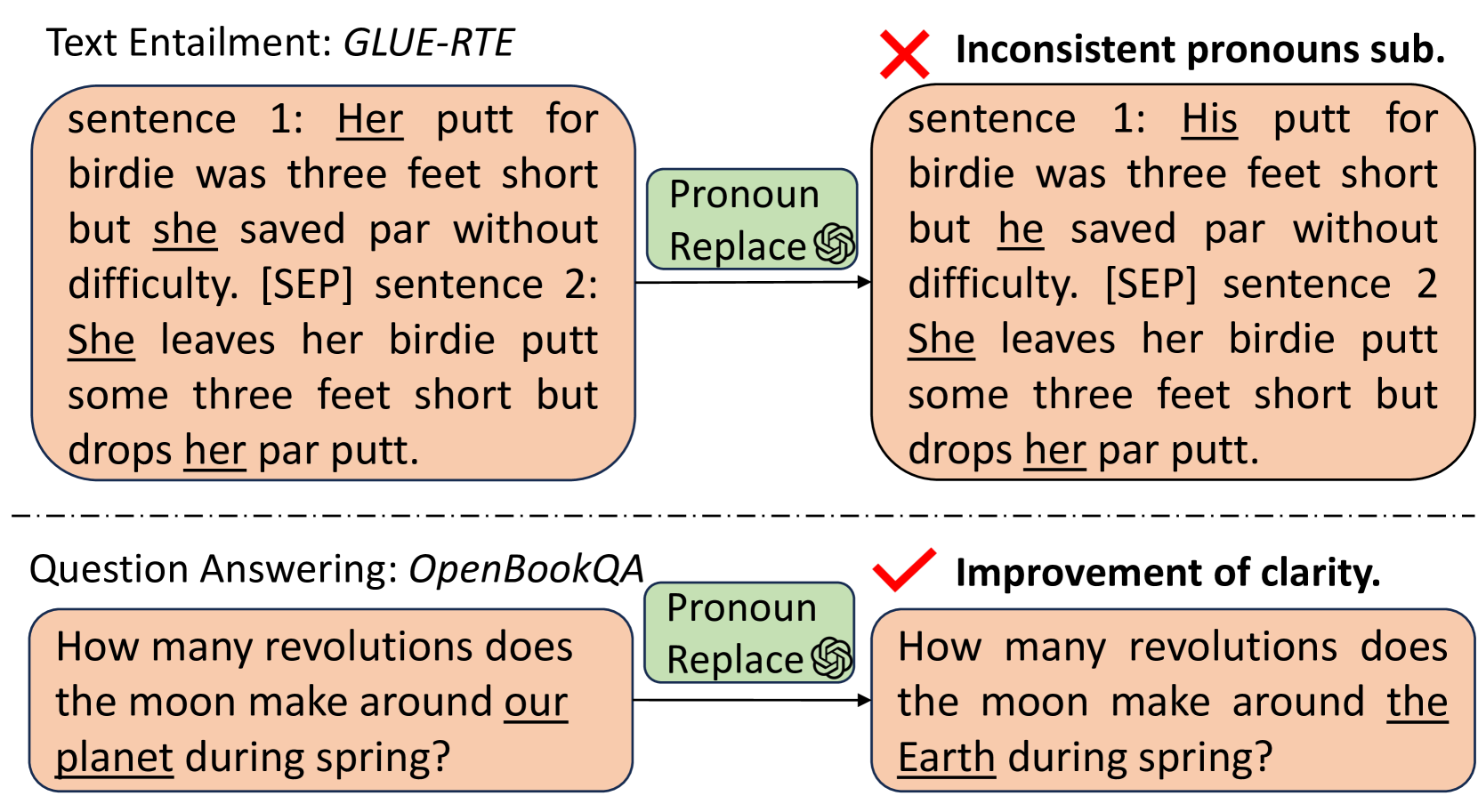
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Read more4/30/2024