Dynamically Expanding Capacity of Autonomous Driving with Near-Miss Focused Training Framework
2406.02865
0
0
🏋️
Abstract
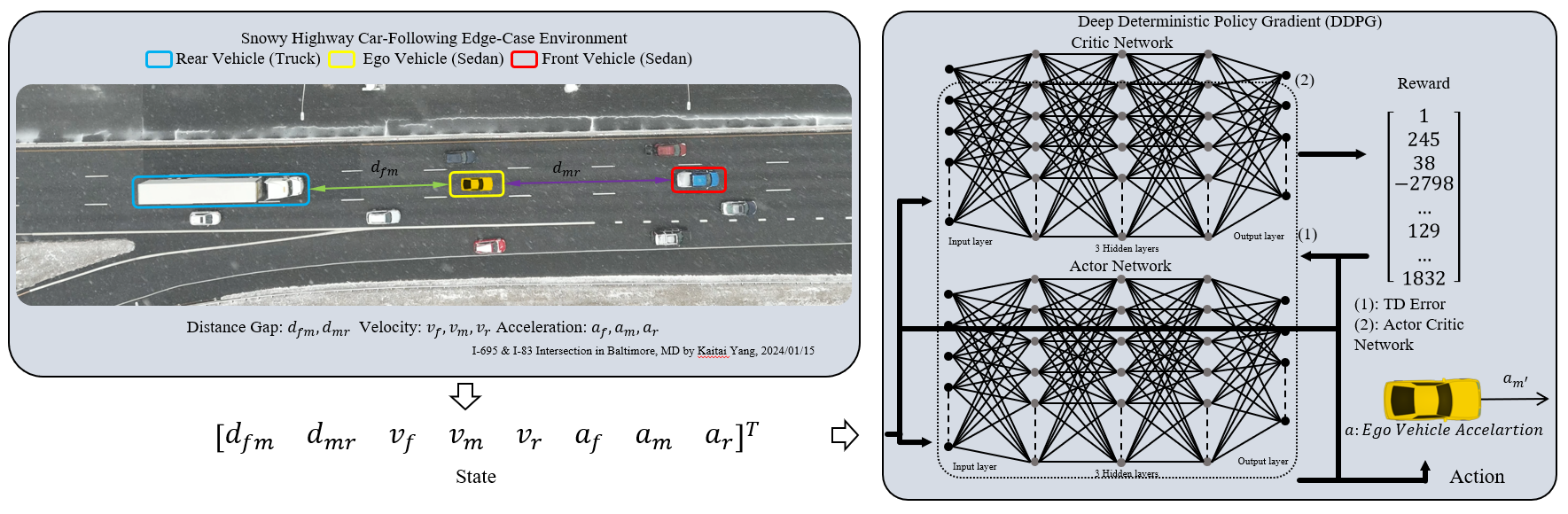
The long-tail distribution of real driving data poses challenges for training and testing autonomous vehicles (AV), where rare yet crucial safety-critical scenarios are infrequent. And virtual simulation offers a low-cost and efficient solution. This paper proposes a near-miss focused training framework for AV. Utilizing the driving scenario information provided by sensors in the simulator, we design novel reward functions, which enable background vehicles (BV) to generate near-miss scenarios and ensure gradients exist not only in collision-free scenes but also in collision scenarios. And then leveraging the Robust Adversarial Reinforcement Learning (RARL) framework for simultaneous training of AV and BV to gradually enhance AV and BV capabilities, as well as generating near-miss scenarios tailored to different levels of AV capabilities. Results from three testing strategies indicate that the proposed method generates scenarios closer to near-miss, thus enhancing the capabilities of both AVs and BVs throughout training.
Create account to get full access
Overview
- Autonomous vehicles (AVs) face challenges in training and testing due to the infrequency of rare yet crucial safety-critical scenarios in real-world driving data
- Virtual simulation offers a low-cost and efficient solution to address this issue
- This paper proposes a near-miss focused training framework for AVs using the Robust Adversarial Reinforcement Learning (RARL) framework
Plain English Explanation
Training and testing autonomous vehicles (AVs) can be difficult because the rare but important safety-critical situations that can happen while driving don't occur very often in real-world data. However, using virtual simulation can help solve this problem in a cost-effective way.
This research paper suggests a new way to train AVs by focusing on "near-miss" scenarios - situations where a collision was narrowly avoided. By designing special reward functions in the simulator, the background vehicles (BVs) are encouraged to generate these near-miss scenarios. Then, using the RARL framework, the AV and BVs are trained together, gradually improving their capabilities and generating even more tailored near-miss situations.
The key idea is to expose the AV to these tricky near-miss scenarios during training, which can help improve its safety and performance in real-world driving situations that may be rare but crucial.
Technical Explanation
The paper proposes a near-miss focused training framework for AVs using virtual simulation. Specifically, the authors leverage the sensor data provided by the simulator to design novel reward functions that incentivize the background vehicles (BVs) to generate near-miss scenarios. This ensures that the AV is trained not only on collision-free scenes but also on collision scenarios.
The authors then use the Robust Adversarial Reinforcement Learning (RARL) framework to simultaneously train the AV and BVs. This allows the capabilities of both the AV and BVs to be gradually enhanced, while also generating near-miss scenarios tailored to different levels of AV capabilities.
The paper evaluates the proposed method using three testing strategies, which show that the generated scenarios are indeed closer to near-miss situations, thereby enhancing the capabilities of both the AVs and BVs throughout the training process.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of rare yet crucial safety-critical scenarios in AV training and testing. By leveraging virtual simulation and the RARL framework, the authors are able to generate near-miss scenarios that can help improve the safety and performance of AVs.
However, the paper does not discuss potential limitations or areas for further research. For example, it would be interesting to understand how the proposed method performs in more complex, real-world-like driving environments, or how it compares to other approaches for generating diverse and challenging scenarios, such as language model integration or uncertainty-aware DRL.
Additionally, while the paper demonstrates the effectiveness of the proposed method, it would be valuable to explore the underlying reasons for its success, such as the specific design choices for the reward functions or the RARL training process. This could lead to further refinements and improvements to the approach.
Conclusion
This paper presents a novel near-miss focused training framework for autonomous vehicles (AVs) using virtual simulation and the Robust Adversarial Reinforcement Learning (RARL) framework. By designing reward functions that incentivize the generation of near-miss scenarios and leveraging the RARL approach, the authors are able to enhance the capabilities of both the AV and the background vehicles (BVs) throughout the training process.
The results indicate that this method can generate scenarios that are closer to near-miss situations, which can in turn improve the safety and performance of AVs in real-world driving conditions. This is a significant contribution to the field of autonomous vehicle development, as it addresses a key challenge in training and testing AVs for rare yet crucial safety-critical scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Deep Reinforcement Learning for Advanced Longitudinal Control and Collision Avoidance in High-Risk Driving Scenarios
Dianwei Chen, Yaobang Gong, Xianfeng Yang
0
0
Existing Advanced Driver Assistance Systems primarily focus on the vehicle directly ahead, often overlooking potential risks from following vehicles. This oversight can lead to ineffective handling of high risk situations, such as high speed, closely spaced, multi vehicle scenarios where emergency braking by one vehicle might trigger a pile up collision. To overcome these limitations, this study introduces a novel deep reinforcement learning based algorithm for longitudinal control and collision avoidance. This proposed algorithm effectively considers the behavior of both leading and following vehicles. Its implementation in simulated high risk scenarios, which involve emergency braking in dense traffic where traditional systems typically fail, has demonstrated the algorithm ability to prevent potential pile up collisions, including those involving heavy duty vehicles.
5/1/2024
🏅
Diagnosing and Predicting Autonomous Vehicle Operational Safety Using Multiple Simulation Modalities and a Virtual Environment
Joe Beck, Shean Huff, Subhadeep Chakraborty
0
0
Even as technology and performance gains are made in the sphere of automated driving, safety concerns remain. Vehicle simulation has long been seen as a tool to overcome the cost associated with a massive amount of on-road testing for development and discovery of safety critical edge-cases. However, purely software-based vehicle models may leave a large realism gap between their real-world counterparts in terms of dynamic response, and highly realistic vehicle-in-the-loop (VIL) simulations that encapsulate a virtual world around a physical vehicle may still be quite expensive to produce and similarly time intensive as on-road testing. In this work, we demonstrate an AV simulation test bed that combines the realism of vehicle-in-the-loop (VIL) simulation with the ease of implementation of model-in-the-loop (MIL) simulation. The setup demonstrated in this work allows for response diagnosis for the VIL simulations. By observing causal links between virtual weather and lighting conditions that surround the virtual depiction of our vehicle, the vision-based perception model and controller of Openpilot, and the dynamic response of our physical vehicle under test, we can draw conclusions regarding how the perceived environment contributed to vehicle response. Conversely, we also demonstrate response prediction for the MIL setup, where the need for a physical vehicle is not required to draw richer conclusions around the impact of environmental conditions on AV performance than could be obtained with VIL simulation alone. These combine for a simulation setup with accurate real-world implications for edge-case discovery that is both cost effective and time efficient to implement.
5/14/2024

TrACT: A Training Dynamics Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Junrui Zhang, Mozhgan Pourkeshavarz, Amir Rasouli
0
0
As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.
5/1/2024

New!Deep Reinforcement Learning for Adverse Garage Scenario Generation
Kai Li
0
0
Autonomous vehicles need to travel over 11 billion miles to ensure their safety. Therefore, the importance of simulation testing before real-world testing is self-evident. In recent years, the release of 3D simulators for autonomous driving, represented by Carla and CarSim, marks the transition of autonomous driving simulation testing environments from simple 2D overhead views to complex 3D models. During simulation testing, experimenters need to build static scenes and dynamic traffic flows, pedestrian flows, and other experimental elements to construct experimental scenarios. When building static scenes in 3D simulators, experimenters often need to manually construct 3D models, set parameters and attributes, which is time-consuming and labor-intensive. This thesis proposes an automated program generation framework. Based on deep reinforcement learning, this framework can generate different 2D ground script codes, on which 3D model files and map model files are built. The generated 3D ground scenes are displayed in the Carla simulator, where experimenters can use this scene for navigation algorithm simulation testing.
7/2/2024