Dynamically Modulating Visual Place Recognition Sequence Length For Minimum Acceptable Performance Scenarios

0

Sign in to get full access
Overview
- This paper presents a novel approach to dynamically modulating the sequence length used in visual place recognition (VPR) to achieve minimum acceptable performance under various scenarios.
- The researchers propose a system that can adaptively adjust the sequence length of VPR based on factors like computational constraints, environmental conditions, and desired performance levels.
- The goal is to enable efficient VPR in diverse real-world settings by optimizing the balance between accuracy, computational cost, and other practical considerations.
Plain English Explanation
Visual place recognition (VPR) is a crucial technology for applications like autonomous navigation, where robots or vehicles need to identify their location based on camera images. Traditionally, VPR systems have relied on analyzing long sequences of images to achieve high accuracy. However, this can be computationally expensive and impractical in certain scenarios, such as when resources are limited or the environment is rapidly changing.
The researchers in this paper recognized the need for a more flexible and adaptive VPR approach. They developed a system that can dynamically adjust the length of the image sequence used for place recognition, based on factors like the available computing power, the complexity of the environment, and the required level of performance.
For example, in a scenario with limited computing resources, the system might choose to use a shorter sequence of images, sacrificing some accuracy to reduce the computational burden. Conversely, in a complex environment with many potential places to recognize, the system might use a longer sequence to ensure reliable identification.
By dynamically modulating the sequence length, the researchers aim to find the optimal balance between accuracy, efficiency, and other practical concerns in a wide range of real-world VPR applications. This could enable more robust and versatile navigation capabilities for autonomous systems, such as self-driving cars or mobile robots, by allowing them to adapt to changing conditions and constraints.
Technical Explanation
The researchers propose a novel approach called "Dynamically Modulating Visual Place Recognition Sequence Length for Minimum Acceptable Performance Scenarios" (DMVPR-MAPS). The core idea is to develop a system that can adaptively adjust the length of the image sequence used for VPR based on various factors, such as:
- Computational Constraints: The system can reduce the sequence length to minimize the computational resources required for VPR when resources are limited, while still maintaining a minimum acceptable level of performance.
- Environmental Complexity: In complex environments with many potential places to recognize, the system can increase the sequence length to improve accuracy and robustness.
- Desired Performance Level: Users can specify a target level of VPR performance (e.g., accuracy, recall, or F1-score), and the system will dynamically adjust the sequence length to meet that requirement.
The researchers developed a neural network-based architecture that takes as input the current environment, computational constraints, and desired performance level, and outputs the optimal sequence length for VPR. This adaptive approach allows the system to balance the trade-offs between accuracy, efficiency, and other practical considerations in diverse real-world scenarios.
The paper includes extensive experiments evaluating the DMVPR-MAPS system on various datasets and benchmarks, demonstrating its ability to outperform fixed-length VPR approaches in terms of both performance and computational efficiency.
Critical Analysis
The DMVPR-MAPS approach presented in this paper addresses an important challenge in the field of visual place recognition, namely, the need to balance accuracy, computational cost, and other practical constraints in diverse real-world scenarios. The researchers' idea of dynamically adjusting the sequence length used for VPR is a promising solution that could have significant implications for autonomous systems and robotics applications.
One potential limitation of the proposed system is the reliance on accurate estimation of the current environmental complexity and computational constraints. If these inputs are not reliable or change rapidly, the system may not be able to adapt quickly enough to maintain the desired performance level. The authors acknowledge this challenge and suggest areas for further research, such as incorporating additional contextual information or using reinforcement learning techniques to improve the system's adaptability.
Another aspect that could be explored further is the potential impact of the DMVPR-MAPS approach on energy consumption and battery life, particularly in mobile or embedded systems. While the system aims to optimize computational efficiency, the dynamic adjustment of sequence length may have implications for power usage that should be investigated.
Overall, the DMVPR-MAPS system represents a significant advance in the field of visual place recognition, with the potential to enable more robust and versatile navigation capabilities for autonomous systems. The researchers' work serves as a valuable contribution to the ongoing efforts to develop adaptive and resource-efficient perception algorithms for real-world applications.
Conclusion
The paper "Dynamically Modulating Visual Place Recognition Sequence Length For Minimum Acceptable Performance Scenarios" presents a novel approach to visual place recognition that can dynamically adjust the length of the image sequence used for recognition based on factors such as computational constraints, environmental complexity, and desired performance levels. This adaptive system aims to strike an optimal balance between accuracy, efficiency, and other practical considerations in diverse real-world scenarios.
The proposed DMVPR-MAPS architecture demonstrates the ability to outperform fixed-length VPR approaches, highlighting the importance of developing flexible and context-aware perception algorithms for autonomous systems. While the system has some potential limitations, the researchers' work represents a significant contribution to the field and opens up new avenues for further research and development in this area.
As autonomous technologies continue to advance, the ability to adaptively optimize perception and decision-making processes will be crucial for enabling robust and versatile real-world applications. The DMVPR-MAPS approach showcased in this paper provides a promising direction for achieving this goal, with the potential to have a meaningful impact on the future of autonomous navigation and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamically Modulating Visual Place Recognition Sequence Length For Minimum Acceptable Performance Scenarios
Connor Malone, Ankit Vora, Thierry Peynot, Michael Milford
Mobile robots and autonomous vehicles are often required to function in environments where critical position estimates from sensors such as GPS become uncertain or unreliable. Single image visual place recognition (VPR) provides an alternative for localization but often requires techniques such as sequence matching to improve robustness, which incurs additional computation and latency costs. Even then, the sequence length required to localize at an acceptable performance level varies widely; and simply setting overly long fixed sequence lengths creates unnecessary latency, computational overhead, and can even degrade performance. In these scenarios it is often more desirable to meet or exceed a set target performance at minimal expense. In this paper we present an approach which uses a calibration set of data to fit a model that modulates sequence length for VPR as needed to exceed a target localization performance. We make use of a coarse position prior, which could be provided by any other localization system, and capture the variation in appearance across this region. We use the correlation between appearance variation and sequence length to curate VPR features and fit a multilayer perceptron (MLP) for selecting the optimal length. We demonstrate that this method is effective at modulating sequence length to maximize the number of sections in a dataset which meet or exceed a target performance whilst minimizing the median length used. We show applicability across several datasets and reveal key phenomena like generalization capabilities, the benefits of curating features and the utility of non-state-of-the-art feature extractors with nuanced properties.
Read more7/2/2024

0
Structured Pruning for Efficient Visual Place Recognition
Oliver Grainge, Michael Milford, Indu Bodala, Sarvapali D. Ramchurn, Shoaib Ehsan
Visual Place Recognition (VPR) is fundamental for the global re-localization of robots and devices, enabling them to recognize previously visited locations based on visual inputs. This capability is crucial for maintaining accurate mapping and localization over large areas. Given that VPR methods need to operate in real-time on embedded systems, it is critical to optimize these systems for minimal resource consumption. While the most efficient VPR approaches employ standard convolutional backbones with fixed descriptor dimensions, these often lead to redundancy in the embedding space as well as in the network architecture. Our work introduces a novel structured pruning method, to not only streamline common VPR architectures but also to strategically remove redundancies within the feature embedding space. This dual focus significantly enhances the efficiency of the system, reducing both map and model memory requirements and decreasing feature extraction and retrieval latencies. Our approach has reduced memory usage and latency by 21% and 16%, respectively, across models, while minimally impacting recall@1 accuracy by less than 1%. This significant improvement enhances real-time applications on edge devices with negligible accuracy loss.
Read more9/14/2024
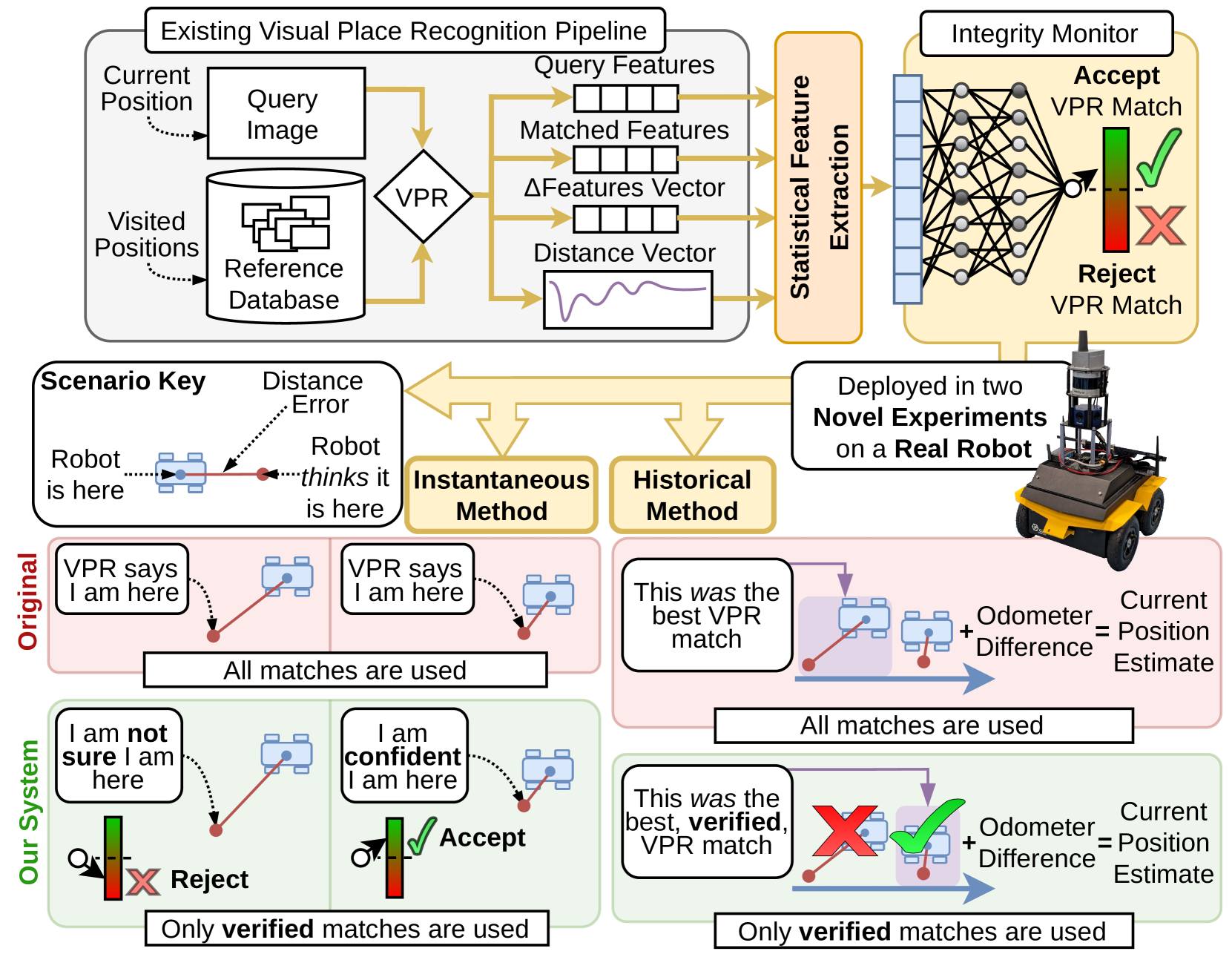
0
Improving Visual Place Recognition Based Robot Navigation Through Verification of Localization Estimates
Owen Claxton, Connor Malone, Helen Carson, Jason Ford, Gabe Bolton, Iman Shames, Michael Milford
Visual Place Recognition (VPR) systems often have imperfect performance, which affects robot navigation decisions. This research introduces a novel Multi-Layer Perceptron (MLP) integrity monitor for VPR which demonstrates improved performance and generalizability over the previous state-of-the-art SVM approach, removing per-environment training and reducing manual tuning requirements. We test our proposed system in extensive real-world experiments, where we also present two real-time integrity-based VPR verification methods: an instantaneous rejection method for a robot navigating to a goal zone (Experiment 1); and a historical method that takes a best, verified, match from its recent trajectory and uses an odometer to extrapolate forwards to a current position estimate (Experiment 2). Noteworthy results for Experiment 1 include a decrease in aggregate mean along-track goal error from ~9.8m to ~3.1m in missions the robot pursued to completion, and an increase in the aggregate rate of successful mission completion from ~41% to ~55%. Experiment 2 showed a decrease in aggregate mean along-track localization error from ~2.0m to ~0.5m, and an increase in the aggregate precision of localization attempts from ~97% to ~99%. Overall, our results demonstrate the practical usefulness of a VPR integrity monitor in real-world robotics to improve VPR localization and consequent navigation performance.
Read more7/12/2024

0
LVLM-empowered Multi-modal Representation Learning for Visual Place Recognition
Teng Wang, Lingquan Meng, Lei Cheng, Changyin Sun
Visual place recognition (VPR) remains challenging due to significant viewpoint changes and appearance variations. Mainstream works tackle these challenges by developing various feature aggregation methods to transform deep features into robust and compact global representations. Unfortunately, satisfactory results cannot be achieved under challenging conditions. We start from a new perspective and attempt to build a discriminative global representations by fusing image data and text descriptions of the the visual scene. The motivation is twofold: (1) Current Large Vision-Language Models (LVLMs) demonstrate extraordinary emergent capability in visual instruction following, and thus provide an efficient and flexible manner in generating text descriptions of images; (2) The text descriptions, which provide high-level scene understanding, show strong robustness against environment variations. Although promising, leveraging LVLMs to build multi-modal VPR solutions remains challenging in efficient multi-modal fusion. Furthermore, LVLMs will inevitably produces some inaccurate descriptions, making it even harder. To tackle these challenges, we propose a novel multi-modal VPR solution. It first adapts pre-trained visual and language foundation models to VPR for extracting image and text features, which are then fed into the feature combiner to enhance each other. As the main component, the feature combiner first propose a token-wise attention block to adaptively recalibrate text tokens according to their relevance to the image data, and then develop an efficient cross-attention fusion module to propagate information across different modalities. The enhanced multi-modal features are compressed into the feature descriptor for performing retrieval. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly smaller image descriptor dimension.
Read more7/10/2024