On the Limitation and Experience Replay for GNNs in Continual Learning

0
🏷️
Sign in to get full access
Overview
- This paper explores the learnability of Graph Neural Networks (GNNs) in Node-wise Graph Continual Learning (NGCL), a practical yet challenging paradigm where a GNN is trained continually on a sequence of node-related tasks.
- The paper introduces the first theoretical exploration of GNN learnability in NGCL, revealing that it is heavily influenced by structural shifts due to the interconnected nature of graph data.
- To address the impact of structural shifts, the paper proposes a novel experience replay method called Structure-Evolution-Aware Experience Replay (SEA-ER) that leverages the topological awareness of GNNs and structural alignment to counter catastrophic forgetting and diminish the effect of structural changes.
Plain English Explanation
In the real world, many systems are constantly evolving and changing over time. Continual learning is a way to help AI models like Graph Neural Networks (GNNs) adapt and learn new information progressively, rather than having to start from scratch each time.
One practical application of continual learning is Node-wise Graph Continual Learning (NGCL), where a GNN is trained on a series of tasks related to nodes in a graph. However, the authors explain that the interconnected nature of graph data can cause significant structural shifts, which can make it difficult for GNNs to learn effectively in this continual setting.
To address this challenge, the researchers propose a new technique called Structure-Evolution-Aware Experience Replay (SEA-ER). SEA-ER uses the GNN's understanding of the graph's topology to select and replay relevant past experiences in a way that helps the model adapt to structural changes and avoid forgetting what it has learned.
The paper provides a thorough theoretical analysis of GNN learnability in NGCL, showing that structural shifts can be a major obstacle. The authors then demonstrate the effectiveness of their SEA-ER approach through extensive experiments, validating their theoretical insights.
Technical Explanation
The paper begins by highlighting the importance of continual learning for real-world systems that evolve over time, and the practical yet challenging paradigm of Node-wise Graph Continual Learning (NGCL), where a Graph Neural Network (GNN) is trained continually on node-related tasks.
Despite recent advancements in continual learning strategies for GNNs in NGCL, the authors note a lack of thorough theoretical understanding, particularly regarding the learnability of GNNs in this setting. Learnability refers to the existence of a learning algorithm that can produce a good candidate model, which is crucial for model selection in NGCL development.
The paper then introduces the first theoretical exploration of GNN learnability in NGCL, revealing that it is heavily influenced by structural shifts due to the interconnected nature of graph data. Specifically, the authors show that GNNs may not be viable for NGCL under significant structural changes, emphasizing the need to manage these structural shifts.
To mitigate the impact of structural shifts, the researchers propose a novel experience replay method called Structure-Evolution-Aware Experience Replay (SEA-ER). SEA-ER features an innovative experience selection strategy that capitalizes on the topological awareness of GNNs, alongside a unique replay strategy that employs structural alignment to effectively counter catastrophic forgetting and diminish the impact of structural shifts on GNNs in NGCL.
The paper's extensive experiments validate the theoretical insights and demonstrate the effectiveness of the proposed SEA-ER approach.
Critical Analysis
The paper provides a valuable theoretical exploration of GNN learnability in the context of Node-wise Graph Continual Learning (NGCL), which is an important and practical paradigm for many real-world applications. The authors' identification of structural shifts as a key challenge for GNNs in this setting is a significant contribution to the field.
While the theoretical analysis is thorough, the paper could have delved deeper into the specific mechanisms and assumptions underlying the learnability analysis. Additionally, the paper could have discussed potential limitations or boundary conditions of the proposed SEA-ER approach, such as its performance under different levels of structural changes or its scalability to large-scale graph datasets.
Furthermore, the paper could have explored alternative strategies for managing structural shifts, such as incorporating explicit graph evolution modeling or leveraging causal reasoning approaches, and compared their effectiveness with the SEA-ER method.
Overall, the paper makes a valuable contribution to the understanding of GNN learnability in continual learning settings, and the proposed SEA-ER approach provides a promising direction for addressing the challenges posed by structural shifts. Readers are encouraged to think critically about the research and consider potential avenues for further exploration and improvement.
Conclusion
This paper presents a groundbreaking theoretical exploration of the learnability of Graph Neural Networks (GNNs) in the context of Node-wise Graph Continual Learning (NGCL). The key finding is that GNN learnability is heavily influenced by structural shifts in the underlying graph data, which can pose a significant challenge for these models in continual learning scenarios.
To address this issue, the researchers propose a novel experience replay method called Structure-Evolution-Aware Experience Replay (SEA-ER). SEA-ER leverages the topological awareness of GNNs and structural alignment to effectively counter catastrophic forgetting and diminish the impact of structural shifts, as demonstrated through extensive experiments.
The theoretical insights and the SEA-ER approach introduced in this paper have important implications for the development of robust and adaptive Graph Neural Network models that can effectively learn and adapt in dynamic, real-world environments. This work lays the foundation for further exploration of continual learning techniques for graph-structured data, which is crucial for many practical applications that involve evolving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
On the Limitation and Experience Replay for GNNs in Continual Learning
Junwei Su, Difan Zou, Chuan Wu
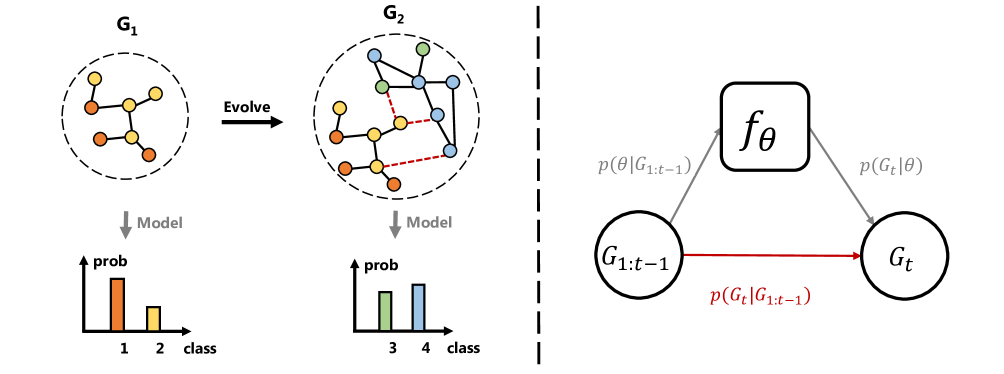
Continual learning seeks to empower models to progressively acquire information from a sequence of tasks. This approach is crucial for many real-world systems, which are dynamic and evolve over time. Recent research has witnessed a surge in the exploration of Graph Neural Networks (GNN) in Node-wise Graph Continual Learning (NGCL), a practical yet challenging paradigm involving the continual training of a GNN on node-related tasks. Despite recent advancements in continual learning strategies for GNNs in NGCL, a thorough theoretical understanding, especially regarding its learnability, is lacking. Learnability concerns the existence of a learning algorithm that can produce a good candidate model from the hypothesis/weight space, which is crucial for model selection in NGCL development. This paper introduces the first theoretical exploration of the learnability of GNN in NGCL, revealing that learnability is heavily influenced by structural shifts due to the interconnected nature of graph data. Specifically, GNNs may not be viable for NGCL under significant structural changes, emphasizing the need to manage structural shifts. To mitigate the impact of structural shifts, we propose a novel experience replay method termed Structure-Evolution-Aware Experience Replay (SEA-ER). SEA-ER features an innovative experience selection strategy that capitalizes on the topological awareness of GNNs, alongside a unique replay strategy that employs structural alignment to effectively counter catastrophic forgetting and diminish the impact of structural shifts on GNNs in NGCL. Our extensive experiments validate our theoretical insights and the effectiveness of SEA-ER.
Read more7/10/2024
0
E-CGL: An Efficient Continual Graph Learner
Jianhao Guo, Zixuan Ni, Yun Zhu, Siliang Tang
Continual learning has emerged as a crucial paradigm for learning from sequential data while preserving previous knowledge. In the realm of continual graph learning, where graphs continuously evolve based on streaming graph data, continual graph learning presents unique challenges that require adaptive and efficient graph learning methods in addition to the problem of catastrophic forgetting. The first challenge arises from the interdependencies between different graph data, where previous graphs can influence new data distributions. The second challenge lies in the efficiency concern when dealing with large graphs. To addresses these two problems, we produce an Efficient Continual Graph Learner (E-CGL) in this paper. We tackle the interdependencies issue by demonstrating the effectiveness of replay strategies and introducing a combined sampling strategy that considers both node importance and diversity. To overcome the limitation of efficiency, E-CGL leverages a simple yet effective MLP model that shares weights with a GCN during training, achieving acceleration by circumventing the computationally expensive message passing process. Our method comprehensively surpasses nine baselines on four graph continual learning datasets under two settings, meanwhile E-CGL largely reduces the catastrophic forgetting problem down to an average of -1.1%. Additionally, E-CGL achieves an average of 15.83x training time acceleration and 4.89x inference time acceleration across the four datasets. These results indicate that E-CGL not only effectively manages the correlation between different graph data during continual training but also enhances the efficiency of continual learning on large graphs. The code is publicly available at https://github.com/aubreygjh/E-CGL.
Read more8/20/2024
0
Graph Memory Learning: Imitating Lifelong Remembering and Forgetting of Brain Networks
Jiaxing Miao, Liang Hu, Qi Zhang, Longbing Cao
Graph data in real-world scenarios undergo rapid and frequent changes, making it challenging for existing graph models to effectively handle the continuous influx of new data and accommodate data withdrawal requests. The approach to frequently retraining graph models is resource intensive and impractical. To address this pressing challenge, this paper introduces a new concept of graph memory learning. Its core idea is to enable a graph model to selectively remember new knowledge but forget old knowledge. Building on this approach, the paper presents a novel graph memory learning framework - Brain-inspired Graph Memory Learning (BGML), inspired by brain network dynamics and function-structure coupling strategies. BGML incorporates a multi-granular hierarchical progressive learning mechanism rooted in feature graph grain learning to mitigate potential conflict between memorization and forgetting in graph memory learning. This mechanism allows for a comprehensive and multi-level perception of local details within evolving graphs. In addition, to tackle the issue of unreliable structures in newly added incremental information, the paper introduces an information self-assessment ownership mechanism. This mechanism not only facilitates the propagation of incremental information within the model but also effectively preserves the integrity of past experiences. We design five types of graph memory learning tasks: regular, memory, unlearning, data-incremental, and class-incremental to evaluate BGML. Its excellent performance is confirmed through extensive experiments on multiple real-world node classification datasets.
Read more7/30/2024

0
Computation-friendly Graph Neural Network Design by Accumulating Knowledge on Large Language Models
Jialiang Wang, Shimin Di, Hanmo Liu, Zhili Wang, Jiachuan Wang, Lei Chen, Xiaofang Zhou
Graph Neural Networks (GNNs), like other neural networks, have shown remarkable success but are hampered by the complexity of their architecture designs, which heavily depend on specific data and tasks. Traditionally, designing proper architectures involves trial and error, which requires intensive manual effort to optimize various components. To reduce human workload, researchers try to develop automated algorithms to design GNNs. However, both experts and automated algorithms suffer from two major issues in designing GNNs: 1) the substantial computational resources expended in repeatedly trying candidate GNN architectures until a feasible design is achieved, and 2) the intricate and prolonged processes required for humans or algorithms to accumulate knowledge of the interrelationship between graphs, GNNs, and performance. To further enhance the automation of GNN architecture design, we propose a computation-friendly way to empower Large Language Models (LLMs) with specialized knowledge in designing GNNs, thereby drastically shortening the computational overhead and development cycle of designing GNN architectures. Our framework begins by establishing a knowledge retrieval pipeline that comprehends the intercorrelations between graphs, GNNs, and performance. This pipeline converts past model design experiences into structured knowledge for LLM reference, allowing it to quickly suggest initial model proposals. Subsequently, we introduce a knowledge-driven search strategy that emulates the exploration-exploitation process of human experts, enabling quick refinement of initial proposals within a promising scope. Extensive experiments demonstrate that our framework can efficiently deliver promising (e.g., Top-5.77%) initial model proposals for unseen datasets within seconds and without any prior training and achieve outstanding search performance in a few iterations.
Read more8/14/2024