E2E-MFD: Towards End-to-End Synchronous Multimodal Fusion Detection

0

Sign in to get full access
Overview
• This paper introduces a new method called EfficientMFD, which aims to improve the efficiency of multimodal synchronous fusion object detection.
• Multimodal fusion combines information from different sensor modalities, such as RGB images and depth data, to improve object detection accuracy.
• The key innovation of EfficientMFD is a more efficient fusion mechanism that reduces computational overhead while maintaining high performance.
Plain English Explanation
Object detection is a important task in computer vision, where the goal is to identify and locate objects in an image. Traditionally, this has been done using a single sensor, such as a regular camera that captures RGB (color) information.
However, more advanced object detection systems can use multiple sensors, such as RGB cameras and depth sensors, to capture additional information about the scene. This is called multimodal fusion, and it can lead to better detection accuracy.
The challenge is that integrating all this extra sensor data can be computationally expensive, which makes it difficult to deploy these systems in real-world applications with limited computing resources.
The EfficientMFD method proposed in this paper aims to address this by introducing a more efficient fusion mechanism. Instead of simply combining all the sensor data, EfficientMFD selectively fuses the most relevant information to reduce the overall computational cost, while still maintaining high object detection performance.
This could enable more powerful multimodal object detection systems to be deployed on a wider range of devices, from smartphones to autonomous vehicles, opening up new possibilities for applications that rely on accurate and efficient object recognition.
Technical Explanation
The key innovation in the EfficientMFD method is a new fusion mechanism that selectively combines information from different sensor modalities. Rather than naively fusing all available data, EfficientMFD learns to focus on the most relevant features for the object detection task at hand.
This is achieved through a series of adaptive fusion modules that dynamically adjust the fusion weights based on the input data. These modules use attention mechanisms to identify the most informative features from each modality and then combine them in an efficient way.
The authors evaluate EfficientMFD on several standard multimodal object detection benchmarks, comparing it to state-of-the-art fusion methods like AMFD-Distillation, Equivariant Multi-Modality Image Fusion, and Fusion-MAMBA. They show that EfficientMFD achieves comparable or better detection performance while being significantly more computationally efficient.
The authors also demonstrate the flexibility of EfficientMFD by incorporating it into different object detection architectures, such as MaskFuser and Multimodal Collaboration Networks, further showcasing its broad applicability.
Critical Analysis
The EfficientMFD method represents a promising step towards more efficient multimodal object detection, but there are a few potential limitations and areas for further research:
-
The paper focuses on a relatively narrow set of sensor modalities (RGB and depth), and it would be interesting to see how EfficientMFD performs with a wider range of modalities, such as thermal, hyperspectral, or radar data.
-
The experiments are conducted on standard benchmarks, which may not fully capture the challenges of real-world deployment scenarios. Further testing on more diverse and realistic datasets would help validate the practical effectiveness of EfficientMFD.
-
The authors mention that the adaptive fusion modules introduce some additional computational overhead, and it would be valuable to explore ways to further optimize these components to minimize the overall runtime and memory footprint.
-
While the authors demonstrate the flexibility of EfficientMFD by incorporating it into different detection architectures, a more comprehensive analysis of its performance and scalability across a wider range of models would provide a clearer understanding of its general applicability.
Conclusion
The EfficientMFD method proposed in this paper represents an important step forward in the field of multimodal object detection. By introducing a more efficient fusion mechanism, the authors have shown that it is possible to maintain high detection accuracy while significantly reducing the computational cost.
This could have significant implications for the deployment of advanced computer vision systems in resource-constrained environments, such as mobile devices or embedded platforms. By making multimodal fusion more efficient, EfficientMFD opens the door to a new generation of intelligent systems that can leverage rich sensor data to perceive the world with greater accuracy and understanding.
As the field of computer vision continues to advance, techniques like EfficientMFD will play a crucial role in bridging the gap between academic research and real-world applications, ultimately leading to more capable and practical AI-powered solutions for a wide range of industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
E2E-MFD: Towards End-to-End Synchronous Multimodal Fusion Detection
Jiaqing Zhang, Mingxiang Cao, Xue Yang, Weiying Xie, Jie Lei, Daixun Li, Wenbo Huang, Yunsong Li
Multimodal image fusion and object detection are crucial for autonomous driving. While current methods have advanced the fusion of texture details and semantic information, their complex training processes hinder broader applications. Addressing this challenge, we introduce E2E-MFD, a novel end-to-end algorithm for multimodal fusion detection. E2E-MFD streamlines the process, achieving high performance with a single training phase. It employs synchronous joint optimization across components to avoid suboptimal solutions tied to individual tasks. Furthermore, it implements a comprehensive optimization strategy in the gradient matrix for shared parameters, ensuring convergence to an optimal fusion detection configuration. Our extensive testing on multiple public datasets reveals E2E-MFD's superior capabilities, showcasing not only visually appealing image fusion but also impressive detection outcomes, such as a 3.9% and 2.0% mAP50 increase on horizontal object detection dataset M3FD and oriented object detection dataset DroneVehicle, respectively, compared to state-of-the-art approaches. The code is released at https://github.com/icey-zhang/E2E-MFD.
Read more5/24/2024
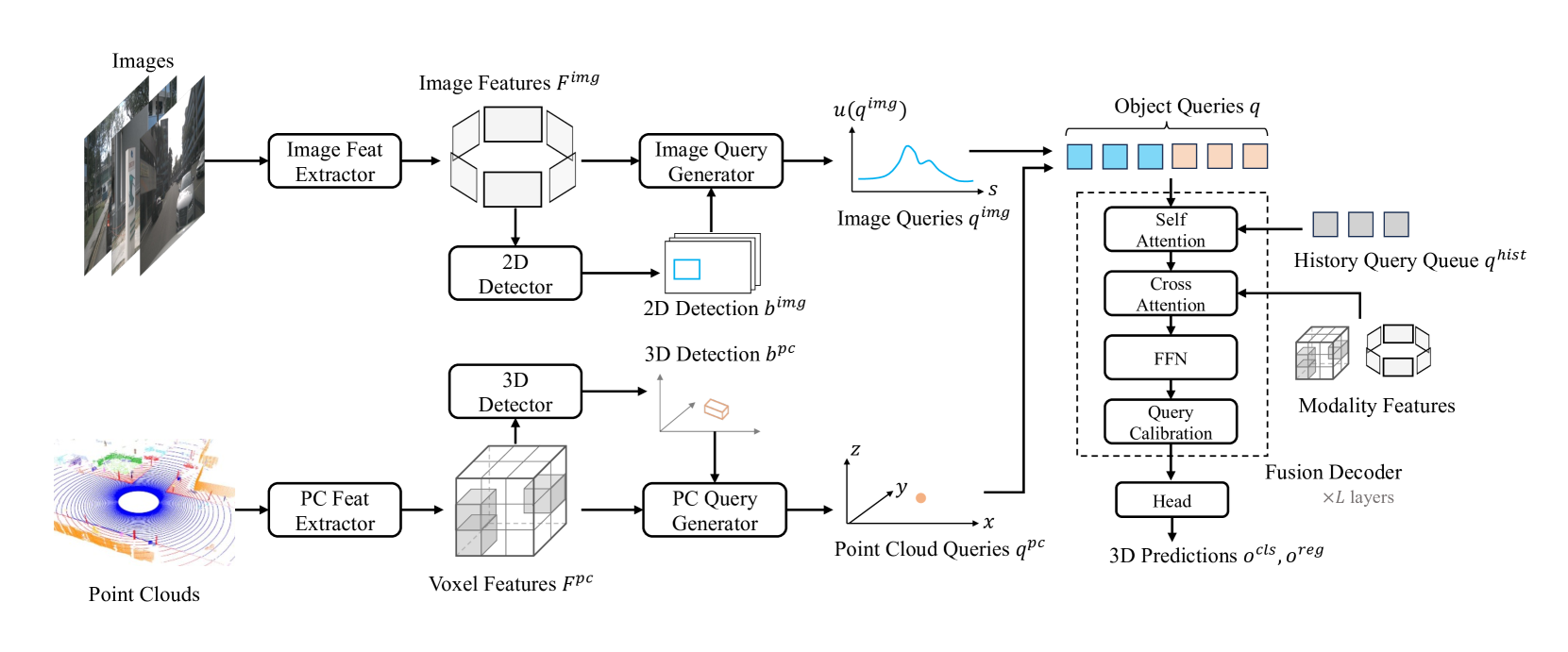
0
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Read more8/13/2024
🔎
0
AMFD: Distillation via Adaptive Multimodal Fusion for Multispectral Pedestrian Detection
Zizhao Chen, Yeqiang Qian, Xiaoxiao Yang, Chunxiang Wang, Ming Yang
Multispectral pedestrian detection has been shown to be effective in improving performance within complex illumination scenarios. However, prevalent double-stream networks in multispectral detection employ two separate feature extraction branches for multi-modal data, leading to nearly double the inference time compared to single-stream networks utilizing only one feature extraction branch. This increased inference time has hindered the widespread employment of multispectral pedestrian detection in embedded devices for autonomous systems. To address this limitation, various knowledge distillation methods have been proposed. However, traditional distillation methods focus only on the fusion features and ignore the large amount of information in the original multi-modal features, thereby restricting the student network's performance. To tackle the challenge, we introduce the Adaptive Modal Fusion Distillation (AMFD) framework, which can fully utilize the original modal features of the teacher network. Specifically, a Modal Extraction Alignment (MEA) module is utilized to derive learning weights for student networks, integrating focal and global attention mechanisms. This methodology enables the student network to acquire optimal fusion strategies independent from that of teacher network without necessitating an additional feature fusion module. Furthermore, we present the SMOD dataset, a well-aligned challenging multispectral dataset for detection. Extensive experiments on the challenging KAIST, LLVIP and SMOD datasets are conducted to validate the effectiveness of AMFD. The results demonstrate that our method outperforms existing state-of-the-art methods in both reducing log-average Miss Rate and improving mean Average Precision. The code is available at https://github.com/bigD233/AMFD.git.
Read more5/22/2024

0
Multi-modal Evidential Fusion Network for Trusted PET/CT Tumor Segmentation
Yuxuan Qi, Li Lin, Jiajun Wang, Jingya Zhang, Bin Zhang
Accurate segmentation of tumors in PET/CT images is important in computer-aided diagnosis and treatment of cancer. The key issue of such a segmentation problem lies in the effective integration of complementary information from PET and CT images. However, the quality of PET and CT images varies widely in clinical settings, which leads to uncertainty in the modality information extracted by networks. To take the uncertainty into account in multi-modal information fusion, this paper proposes a novel Multi-modal Evidential Fusion Network (MEFN) comprising a Cross-Modal Feature Learning (CFL) module and a Multi-modal Trusted Fusion (MTF) module. The CFL module reduces the domain gap upon modality conversion and highlights common tumor features, thereby alleviating the needs of the segmentation module to handle modality specificity. The MTF module utilizes mutual attention mechanisms and an uncertainty calibrator to fuse modality features based on modality uncertainty and then fuse the segmentation results under the guidance of Dempster-Shafer Theory. Besides, a new uncertainty perceptual loss is introduced to force the model focusing on uncertain features and hence improve its ability to extract trusted modality information. Extensive comparative experiments are conducted on two publicly available PET/CT datasets to evaluate the performance of our proposed method whose results demonstrate that our MEFN significantly outperforms state-of-the-art methods with improvements of 2.15% and 3.23% in DSC scores on the AutoPET dataset and the Hecktor dataset, respectively. More importantly, our model can provide radiologists with credible uncertainty of the segmentation results for their decision in accepting or rejecting the automatic segmentation results, which is particularly important for clinical applications. Our code will be available at https://github.com/QPaws/MEFN.
Read more6/27/2024