MaskFuser: Masked Fusion of Joint Multi-Modal Tokenization for End-to-End Autonomous Driving

0
Sign in to get full access
Overview
- This paper introduces MaskFuser, a novel approach for end-to-end autonomous driving that fuses multi-modal sensor data using masked tokenization.
- The key ideas include using a Masked Auto-Encoder to learn robust multi-modal representations, and a joint Multi-Modal Transformer to fuse the sensor data.
- The authors demonstrate the effectiveness of MaskFuser on several autonomous driving benchmarks, showcasing its advantages over state-of-the-art methods.
Plain English Explanation
MaskFuser is a new technique for self-driving cars that helps them better understand their surroundings by combining different types of sensor data. In a self-driving car, there are usually multiple sensors, like cameras, radar, and lidar, that provide information about the environment. MaskFuser takes the data from these sensors and fuses them together in a clever way to create a more complete and accurate understanding of the scene.
The key innovations in MaskFuser are:
-
Masked Auto-Encoder: This is a way to train the system to learn robust representations of the sensor data, even if some of the information is missing or obscured. This makes the system more resilient to real-world conditions where sensor data can be noisy or incomplete.
-
Joint Multi-Modal Transformer: This is a type of neural network that can effectively combine the different sensor data streams, finding the connections and relationships between them to build a unified understanding of the environment. This is crucial for autonomous driving, where the car needs to make decisions based on integrating information from various sources.
By using these techniques, MaskFuser is able to outperform other state-of-the-art methods for autonomous driving tasks, such as predicting the future movements of other vehicles or detecting and recognizing objects. This means self-driving cars equipped with MaskFuser would be able to navigate more safely and effectively in complex real-world environments.
Technical Explanation
The core of MaskFuser is a Masked Auto-Encoder that learns to reconstruct the input sensor data from a partially masked version of it. This forces the model to learn robust, multi-modal representations that can handle missing or noisy information, which is common in real-world autonomous driving scenarios.
The learned representations from the Masked Auto-Encoder are then fed into a Joint Multi-Modal Transformer that fuses the multi-modal sensor data. The Transformer architecture is well-suited for this task as it can effectively model the complex relationships and interactions between the different sensor modalities.
The authors evaluate MaskFuser on several autonomous driving benchmarks, including prediction of future vehicle trajectories and detection of objects and traffic participants. They show that MaskFuser outperforms state-of-the-art approaches, demonstrating the effectiveness of the masked fusion technique for end-to-end autonomous driving.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the MaskFuser approach, with experiments on multiple autonomous driving tasks and comparisons to strong baselines. The authors also discuss several limitations and potential areas for future research, such as the need to further improve the model's efficiency and the potential for incorporating additional sensor modalities beyond the ones considered in this work.
One aspect that could be explored further is the interpretability of the MaskFuser model. While the paper focuses on the performance improvements, it would be interesting to understand better how the model is able to fuse the multi-modal sensor data and which aspects of the Masked Auto-Encoder and Joint Multi-Modal Transformer contribute most to the final results. Techniques for interpreting multi-modal deep learning models could provide valuable insights in this regard.
Additionally, the authors could consider evaluating the robustness of MaskFuser to more extreme real-world conditions, such as sensor failures or adversarial attacks. This would help assess the model's suitability for deployment in safety-critical autonomous driving applications.
Conclusion
The MaskFuser approach presented in this paper represents a significant advancement in the field of end-to-end autonomous driving. By leveraging Masked Auto-Encoders and Joint Multi-Modal Transformers, the authors have developed a novel fusion technique that can effectively integrate multi-modal sensor data, leading to improved performance on a range of driving-related tasks.
The key strengths of MaskFuser are its ability to learn robust, multi-modal representations and its effective fusion of sensor information. These capabilities are crucial for building reliable and safe self-driving systems that can navigate complex real-world environments. As the autonomous driving industry continues to evolve, techniques like MaskFuser will play an increasingly important role in pushing the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MaskFuser: Masked Fusion of Joint Multi-Modal Tokenization for End-to-End Autonomous Driving
Yiqun Duan, Xianda Guo, Zheng Zhu, Zhen Wang, Yu-Kai Wang, Chin-Teng Lin
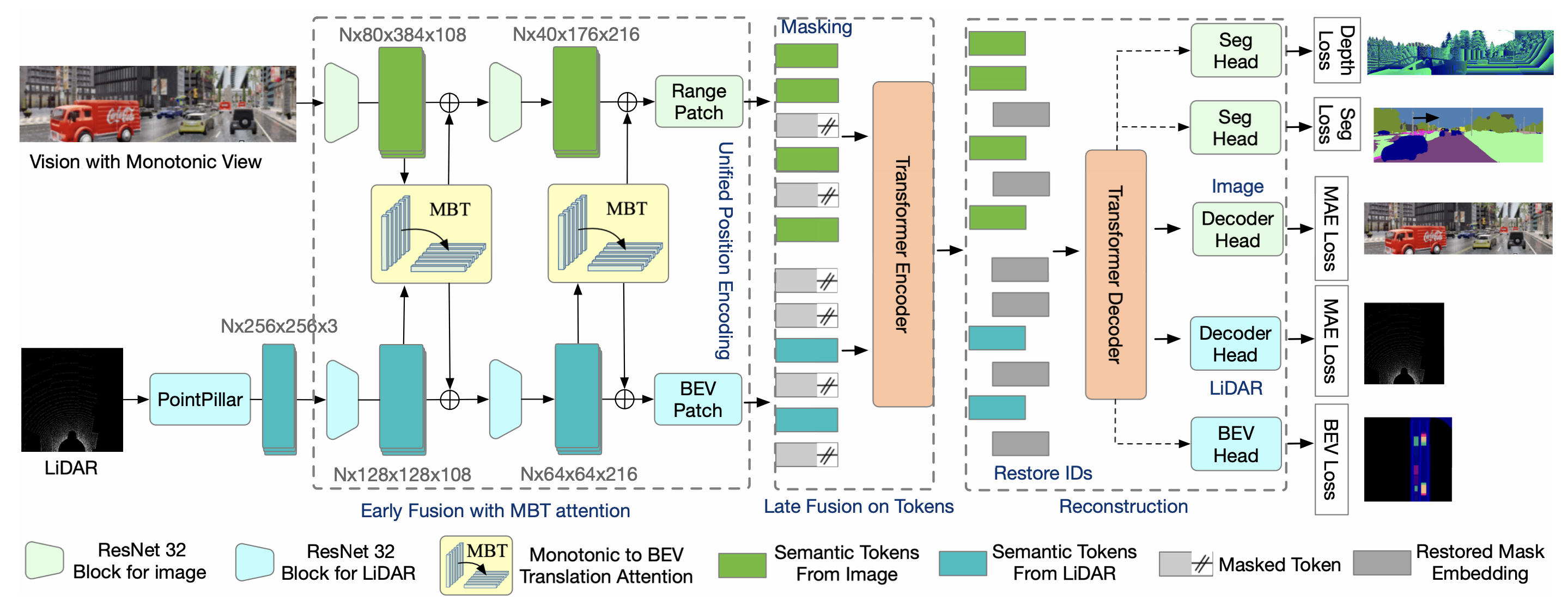
Current multi-modality driving frameworks normally fuse representation by utilizing attention between single-modality branches. However, the existing networks still suppress the driving performance as the Image and LiDAR branches are independent and lack a unified observation representation. Thus, this paper proposes MaskFuser, which tokenizes various modalities into a unified semantic feature space and provides a joint representation for further behavior cloning in driving contexts. Given the unified token representation, MaskFuser is the first work to introduce cross-modality masked auto-encoder training. The masked training enhances the fusion representation by reconstruction on masked tokens. Architecturally, a hybrid-fusion network is proposed to combine advantages from both early and late fusion: For the early fusion stage, modalities are fused by performing monotonic-to-BEV translation attention between branches; Late fusion is performed by tokenizing various modalities into a unified token space with shared encoding on it. MaskFuser respectively reaches a driving score of 49.05 and route completion of 92.85% on the CARLA LongSet6 benchmark evaluation, which improves the best of previous baselines by 1.74 and 3.21%. The introduced masked fusion increases driving stability under damaged sensory inputs. MaskFuser outperforms the best of previous baselines on driving score by 6.55 (27.8%), 1.53 (13.8%), 1.57 (30.9%), respectively given sensory masking ratios 25%, 50%, and 75%.
Read more5/14/2024

0
MultiFuser: Multimodal Fusion Transformer for Enhanced Driver Action Recognition
Ruoyu Wang, Wenqian Wang, Jianjun Gao, Dan Lin, Kim-Hui Yap, Bingbing Li
Driver action recognition, aiming to accurately identify drivers' behaviours, is crucial for enhancing driver-vehicle interactions and ensuring driving safety. Unlike general action recognition, drivers' environments are often challenging, being gloomy and dark, and with the development of sensors, various cameras such as IR and depth cameras have emerged for analyzing drivers' behaviors. Therefore, in this paper, we propose a novel multimodal fusion transformer, named MultiFuser, which identifies cross-modal interrelations and interactions among multimodal car cabin videos and adaptively integrates different modalities for improved representations. Specifically, MultiFuser comprises layers of Bi-decomposed Modules to model spatiotemporal features, with a modality synthesizer for multimodal features integration. Each Bi-decomposed Module includes a Modal Expertise ViT block for extracting modality-specific features and a Patch-wise Adaptive Fusion block for efficient cross-modal fusion. Extensive experiments are conducted on Drive&Act dataset and the results demonstrate the efficacy of our proposed approach.
Read more8/20/2024

0
Efficient Fusion and Task Guided Embedding for End-to-end Autonomous Driving
Yipin Guo, Yilin Lang, Qinyuan Ren
To address the challenges of sensor fusion and safety risk prediction, contemporary closed-loop autonomous driving neural networks leveraging imitation learning typically require a substantial volume of parameters and computational resources to run neural networks. Given the constrained computational capacities of onboard vehicular computers, we introduce a compact yet potent solution named EfficientFuser. This approach employs EfficientViT for visual information extraction and integrates feature maps via cross attention. Subsequently, it utilizes a decoder-only transformer for the amalgamation of multiple features. For prediction purposes, learnable vectors are embedded as tokens to probe the association between the task and sensor features through attention. Evaluated on the CARLA simulation platform, EfficientFuser demonstrates remarkable efficiency, utilizing merely 37.6% of the parameters and 8.7% of the computations compared to the state-of-the-art lightweight method with only 0.4% lower driving score, and the safety score neared that of the leading safety-enhanced method, showcasing its efficacy and potential for practical deployment in autonomous driving systems.
Read more7/18/2024
🔍
0
UniM$^2$AE: Multi-modal Masked Autoencoders with Unified 3D Representation for 3D Perception in Autonomous Driving
Jian Zou, Tianyu Huang, Guanglei Yang, Zhenhua Guo, Tao Luo, Chun-Mei Feng, Wangmeng Zuo
Masked Autoencoders (MAE) play a pivotal role in learning potent representations, delivering outstanding results across various 3D perception tasks essential for autonomous driving. In real-world driving scenarios, it's commonplace to deploy multiple sensors for comprehensive environment perception. Despite integrating multi-modal features from these sensors can produce rich and powerful features, there is a noticeable challenge in MAE methods addressing this integration due to the substantial disparity between the different modalities. This research delves into multi-modal Masked Autoencoders tailored for a unified representation space in autonomous driving, aiming to pioneer a more efficient fusion of two distinct modalities. To intricately marry the semantics inherent in images with the geometric intricacies of LiDAR point clouds, we propose UniM$^2$AE. This model stands as a potent yet straightforward, multi-modal self-supervised pre-training framework, mainly consisting of two designs. First, it projects the features from both modalities into a cohesive 3D volume space to intricately marry the bird's eye view (BEV) with the height dimension. The extension allows for a precise representation of objects and reduces information loss when aligning multi-modal features. Second, the Multi-modal 3D Interactive Module (MMIM) is invoked to facilitate the efficient inter-modal interaction during the interaction process. Extensive experiments conducted on the nuScenes Dataset attest to the efficacy of UniM$^2$AE, indicating enhancements in 3D object detection and BEV map segmentation by 1.2% NDS and 6.5% mIoU, respectively. The code is available at https://github.com/hollow-503/UniM2AE.
Read more8/26/2024