Large Language Models for Mathematical Reasoning: Progresses and Challenges

0

Sign in to get full access
Overview
- This paper explores the progress and challenges of using large language models (LLMs) for mathematical reasoning tasks.
- It covers related work on using LLMs for math and education, as well as datasets and benchmarks for evaluating mathematical reasoning capabilities.
- The paper delves into the technical details of LLM architecture, training, and evaluation for mathematical reasoning.
- It also provides a critical analysis of the limitations and areas for further research in this domain.
Plain English Explanation
This research paper examines how well large language models, which are powerful AI systems trained on vast amounts of text data, can be used to solve mathematical problems and reason about mathematical concepts. The authors review previous work on applying these language models to math and education, and describe the various datasets and tests that have been developed to measure a model's mathematical reasoning abilities.
The core of the paper goes into the technical details of how these large language models are designed and trained to perform mathematical reasoning tasks. This includes discussing the model architectures, the training data and methods used, and the specific techniques employed to assess the models' capabilities.
<a href="https://aimodels.fyi/papers/arxiv/large-language-models-mathematicians">The paper also highlights the current limitations and challenges</a> in using language models for advanced mathematical reasoning, such as their tendency to make mistakes or struggle with more complex problem-solving. The authors suggest areas for further research and development to improve the mathematical abilities of these AI systems.
Overall, this work provides an in-depth look at the progress and open questions surrounding the use of powerful language models for tasks that require deep mathematical understanding and reasoning.
Technical Explanation
The paper begins by surveying the related work on applying <a href="https://aimodels.fyi/papers/arxiv/large-language-models-education-survey-outlook">large language models (LLMs) to mathematical reasoning and educational applications</a>. This includes research on using LLMs for math problem-solving, theorem proving, and even generating mathematical proofs.
The authors then describe the various datasets and benchmarks that have been developed to evaluate the mathematical reasoning capabilities of LLMs. These include datasets of math word problems, logic puzzles, and other math-focused tasks that can be used to assess the models' performance.
In terms of the technical approach, the paper delves into the architectural choices and training techniques used to enable LLMs to effectively reason about mathematical concepts. This includes the use of specialized token embeddings, attention mechanisms, and other model components tailored for mathematical reasoning.
The authors also discuss the evaluation methodologies employed, which go <a href="https://aimodels.fyi/papers/arxiv/beyond-accuracy-evaluating-reasoning-behavior-large-language">beyond just measuring accuracy</a> to also analyze the models' step-by-step reasoning processes and their ability to handle more open-ended mathematical tasks.
Critical Analysis
The paper acknowledges several key limitations and challenges in using LLMs for advanced mathematical reasoning. <a href="https://aimodels.fyi/papers/arxiv/are-large-language-models-superhuman-chemists">Despite their impressive capabilities, the models still struggle with certain types of mathematical reasoning</a>, such as handling complex multi-step problems, maintaining long-term reasoning, and dealing with ambiguity or edge cases.
The authors also note that the current evaluation frameworks may not fully capture the nuances of mathematical reasoning, and that more work is needed to develop robust and comprehensive benchmarks in this domain.
Additionally, the paper suggests that further research is needed to better understand the internal representations and decision-making processes of LLMs when solving mathematical problems. This could help identify the core strengths and limitations of these models, and inform the development of more effective architectural and training approaches.
Conclusion
This paper provides a detailed exploration of the progress and challenges in using large language models for mathematical reasoning tasks. It highlights the significant advancements made in this area, while also calling attention to the remaining limitations and areas for further research and development.
<a href="https://aimodels.fyi/papers/arxiv/survey-large-language-model-based-autonomous-agents">The insights from this work have important implications for the broader field of AI-powered mathematical reasoning and problem-solving</a>, and could help guide the design of more effective and versatile AI systems capable of tackling complex mathematical problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
Read more9/18/2024

0
Benchmarking Large Language Models for Math Reasoning Tasks
Kathrin Se{ss}ler, Yao Rong, Emek Gozluklu, Enkelejda Kasneci
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
Read more8/21/2024
0
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
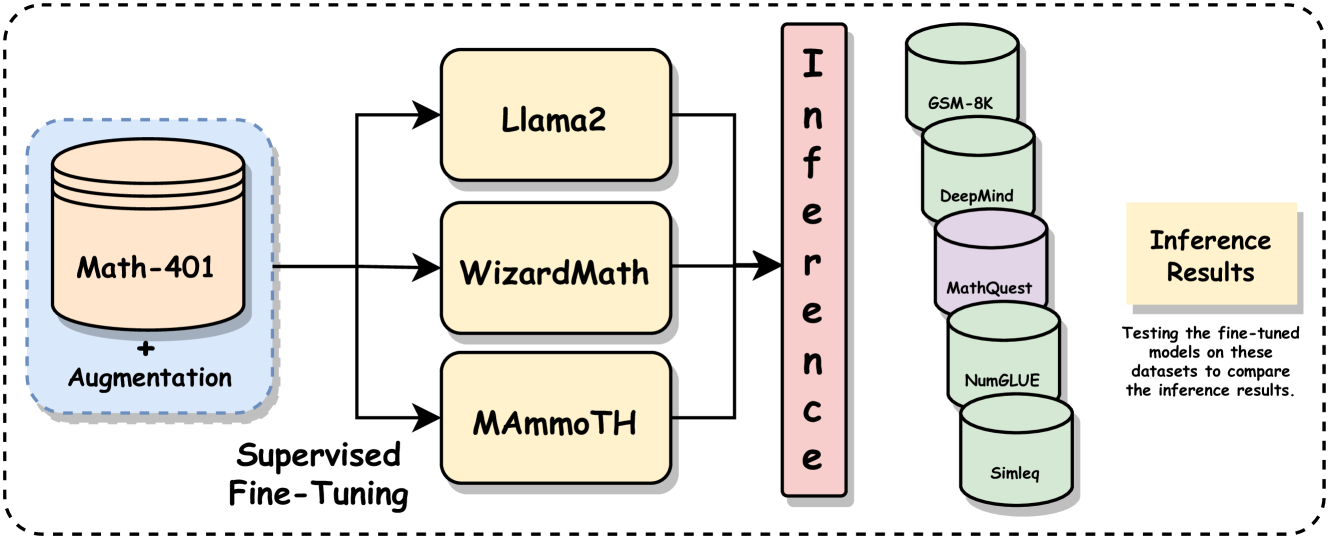
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
Read more4/23/2024
💬
0
Puzzle Solving using Reasoning of Large Language Models: A Survey
Panagiotis Giadikiaroglou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
Exploring the capabilities of Large Language Models (LLMs) in puzzle solving unveils critical insights into their potential and challenges in AI, marking a significant step towards understanding their applicability in complex reasoning tasks. This survey leverages a unique taxonomy -- dividing puzzles into rule-based and rule-less categories -- to critically assess LLMs through various methodologies, including prompting techniques, neuro-symbolic approaches, and fine-tuning. Through a critical review of relevant datasets and benchmarks, we assess LLMs' performance, identifying significant challenges in complex puzzle scenarios. Our findings highlight the disparity between LLM capabilities and human-like reasoning, particularly in those requiring advanced logical inference. The survey underscores the necessity for novel strategies and richer datasets to advance LLMs' puzzle-solving proficiency and contribute to AI's logical reasoning and creative problem-solving advancements.
Read more9/17/2024