EasyRec: Simple yet Effective Language Models for Recommendation

0

Sign in to get full access
Overview
- EasyRec is a simple yet effective language model for recommendation tasks.
- It demonstrates that basic language models can outperform more complex recommendation systems.
- The paper focuses on the core ideas and their significance rather than technical details.
Plain English Explanation
EasyRec: Simple yet Effective Language Models for Recommendation shows that simple language models can be highly effective for making recommendations. The key idea is to use a standard language model, trained on a large amount of text data, and then fine-tune it on a specific recommendation task.
The researchers found that this approach can outperform more complex recommendation systems, which often require significant engineering effort and specialized architectures. By leveraging the power of large language models, EasyRec can capture the underlying patterns and relationships in the data without needing bespoke models.
This is significant because it suggests that recommendation systems don't always need to be complex to be effective. The researchers demonstrate that with the right approach, even basic language models can provide high-quality recommendations across a variety of domains, from movie recommendations to product suggestions.
Technical Explanation
EasyRec: Simple yet Effective Language Models for Recommendation explores the use of language models for recommendation tasks. The researchers propose a simple approach that involves fine-tuning a pre-trained language model on a specific recommendation dataset.
The core idea is to treat the recommendation problem as a language modeling task. Given a user's past interactions or preferences, the language model is trained to predict the next item the user might be interested in. This is done by fine-tuning the language model on the recommendation dataset, which includes user-item interactions and item metadata.
The researchers experiment with different language model architectures, such as GPT and BERT, and find that even basic models can outperform more complex recommendation systems. This is because the language models are able to capture the underlying patterns and relationships in the data, without the need for specialized recommendation-specific architectures.
The experiments cover a range of recommendation tasks, including movie, book, and product recommendations, and the results demonstrate the versatility and effectiveness of the EasyRec approach.
Critical Analysis
The EasyRec paper presents a compelling approach to recommendation systems, but it also acknowledges some potential limitations and areas for further research.
One potential caveat is that the performance of EasyRec may depend on the size and quality of the pre-trained language model used. The researchers used large, widely-available models like GPT and BERT, but it's possible that custom-trained models or models fine-tuned on specific domains could provide even better results.
Additionally, the paper does not address how EasyRec would handle the cold-start problem, where new users or items have limited historical data. This is a common challenge in recommendation systems, and it's not clear how the language modeling approach would perform in these scenarios.
Further research could also explore the interpretability and explainability of the EasyRec recommendations. While the language models can provide effective recommendations, it may be valuable to understand the reasoning behind the recommendations, especially in sensitive domains like healthcare or finance.
Overall, the EasyRec paper presents a promising direction for recommendation systems, demonstrating that simple language models can be highly effective. However, there are still opportunities to build upon this work and address potential limitations.
Conclusion
The EasyRec paper offers a refreshingly simple yet powerful approach to recommendation systems. By leveraging the capabilities of large language models, the researchers show that even basic models can outperform more complex recommendation architectures.
This finding has significant implications for the field of recommendation systems. It suggests that the focus on developing ever-more sophisticated models may not always be necessary, and that simpler approaches can be just as effective. This could lead to faster development cycles, lower computational costs, and more accessible recommendation systems.
Moreover, the versatility of the EasyRec approach, demonstrated across diverse recommendation tasks, highlights its potential for widespread adoption. As language models continue to improve and become more widely available, the EasyRec method could become a go-to solution for a wide range of recommendation challenges.
While the paper acknowledges some areas for further research, the core insights of EasyRec are a testament to the power of simplicity in machine learning. By leveraging the rich representations learned by language models, the researchers have shown that recommendation systems can be both effective and efficient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EasyRec: Simple yet Effective Language Models for Recommendation
Xubin Ren, Chao Huang
Deep neural networks have become a powerful technique for learning representations from user-item interaction data in collaborative filtering (CF) for recommender systems. However, many existing methods heavily rely on unique user and item IDs, which limits their ability to perform well in practical zero-shot learning scenarios where sufficient training data may be unavailable. Inspired by the success of language models (LMs) and their strong generalization capabilities, a crucial question arises: How can we harness the potential of language models to empower recommender systems and elevate its generalization capabilities to new heights? In this study, we propose EasyRec - an effective and easy-to-use approach that seamlessly integrates text-based semantic understanding with collaborative signals. EasyRec employs a text-behavior alignment framework, which combines contrastive learning with collaborative language model tuning, to ensure a strong alignment between the text-enhanced semantic space and the collaborative behavior information. Extensive empirical evaluations across diverse real-world datasets demonstrate the superior performance of EasyRec compared to state-of-the-art alternative models, particularly in the challenging text-based zero-shot recommendation scenarios. Furthermore, the study highlights the potential of seamlessly integrating EasyRec as a plug-and-play component into text-enhanced collaborative filtering frameworks, thereby empowering existing recommender systems to elevate their recommendation performance and adapt to the evolving user preferences in dynamic environments. For better result reproducibility of our EasyRec framework, the model implementation details, source code, and datasets are available at the link: https://github.com/HKUDS/EasyRec.
Read more8/19/2024
0
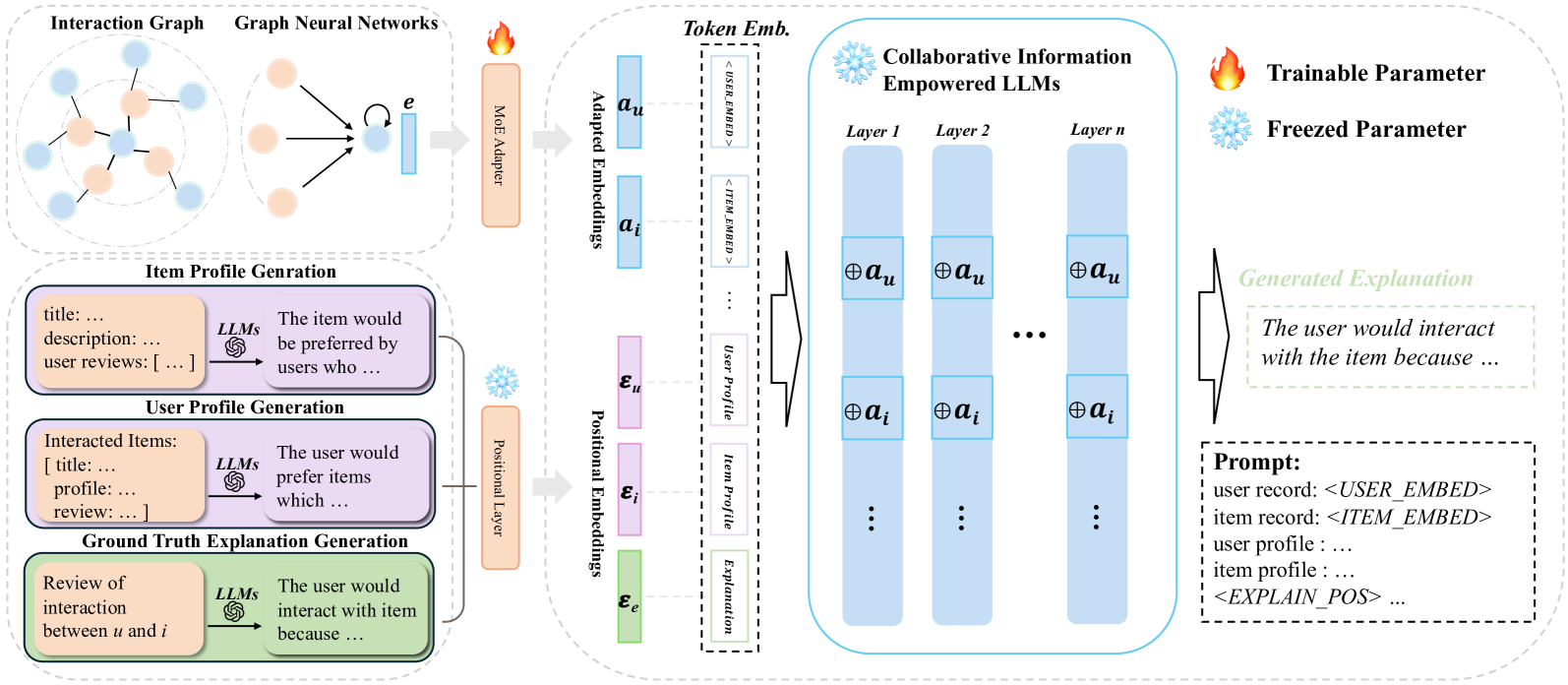
XRec: Large Language Models for Explainable Recommendation
Qiyao Ma, Xubin Ren, Chao Huang
Recommender systems help users navigate information overload by providing personalized recommendations aligned with their preferences. Collaborative Filtering (CF) is a widely adopted approach, but while advanced techniques like graph neural networks (GNNs) and self-supervised learning (SSL) have enhanced CF models for better user representations, they often lack the ability to provide explanations for the recommended items. Explainable recommendations aim to address this gap by offering transparency and insights into the recommendation decision-making process, enhancing users' understanding. This work leverages the language capabilities of Large Language Models (LLMs) to push the boundaries of explainable recommender systems. We introduce a model-agnostic framework called XRec, which enables LLMs to provide comprehensive explanations for user behaviors in recommender systems. By integrating collaborative signals and designing a lightweight collaborative adaptor, the framework empowers LLMs to understand complex patterns in user-item interactions and gain a deeper understanding of user preferences. Our extensive experiments demonstrate the effectiveness of XRec, showcasing its ability to generate comprehensive and meaningful explanations that outperform baseline approaches in explainable recommender systems. We open-source our model implementation at https://github.com/HKUDS/XRec.
Read more6/5/2024

0
Language Models Encode Collaborative Signals in Recommendation
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, Tat-Seng Chua
Recent studies empirically indicate that language models (LMs) encode rich world knowledge beyond mere semantics, attracting significant attention across various fields. However, in the recommendation domain, it remains uncertain whether LMs implicitly encode user preference information. Contrary to the prevailing understanding that LMs and traditional recommender models learn two distinct representation spaces due to a huge gap in language and behavior modeling objectives, this work rethinks such understanding and explores extracting a recommendation space directly from the language representation space. Surprisingly, our findings demonstrate that item representations, when linearly mapped from advanced LM representations, yield superior recommendation performance. This outcome suggests the homomorphism between the language representation space and an effective recommendation space, implying that collaborative signals may indeed be encoded within advanced LMs. Motivated by these findings, we propose a simple yet effective collaborative filtering (CF) model named AlphaRec, which utilizes language representations of item textual metadata (e.g., titles) instead of traditional ID-based embeddings. Specifically, AlphaRec is comprised of three main components: a multilayer perceptron (MLP), graph convolution, and contrastive learning (CL) loss function, making it extremely easy to implement and train. Our empirical results show that AlphaRec outperforms leading ID-based CF models on multiple datasets, marking the first instance of such a recommender with text embeddings achieving this level of performance. Moreover, AlphaRec introduces a new language-representation-based CF paradigm with several desirable advantages: being easy to implement, lightweight, rapid convergence, superior zero-shot recommendation abilities in new domains, and being aware of user intention.
Read more7/9/2024
0
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, Chanyoung Park
Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
Read more6/4/2024