EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection

0

Sign in to get full access
Overview
- EaTVul is a ChatGPT-based evasion attack against software vulnerability detection systems.
- The paper demonstrates how an attacker can leverage the language generation capabilities of ChatGPT to bypass vulnerability detection.
- The proposed attack is effective, efficient, and can be easily automated.
Plain English Explanation
EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection is a research paper that explores a new way for attackers to bypass software vulnerability detection systems. The key idea is to use a powerful language model like ChatGPT to generate code or text that looks normal but is actually designed to evade detection.
The researchers show that by carefully prompting ChatGPT, they can create code or text that fools vulnerability detection tools. This is a significant threat, as software vulnerabilities are a major security risk, and being able to bypass detection mechanisms makes it much easier for attackers to exploit them.
The paper demonstrates that the EaTVul attack is highly effective, meaning it can reliably bypass detection, and efficient, meaning it can be automated to scale up attacks. This is a concerning development, as it highlights a new way that advanced language models can be misused for malicious purposes.
Technical Explanation
The key idea behind the EaTVul attack is to leverage the language generation capabilities of ChatGPT to create code or text that appears benign but is actually designed to bypass vulnerability detection systems. The researchers provide a step-by-step overview of their attack methodology, which involves:
- Identifying the target vulnerability detection system and its underlying detection mechanisms.
- Crafting prompts that guide ChatGPT to generate code or text that is likely to evade detection.
- Automatically launching the attack by feeding the generated content into the target system.
The experiment design involves testing the EaTVul attack against several popular vulnerability detection tools, including static code analyzers and dynamic taint analysis systems. The results show that the attack is highly effective, with evasion rates exceeding 90% in many cases.
The architecture of the EaTVul system is designed to be modular and scalable, allowing for easy integration with different vulnerability detection tools and the automation of the attack process.
The key insights from this research include the realization that advanced language models like ChatGPT can be weaponized for malicious purposes, and that the security community needs to develop new countermeasures to address this emerging threat.
Critical Analysis
The paper acknowledges several limitations of the EaTVul attack, such as the potential for detection by more advanced vulnerability detection systems that incorporate additional security checks. The authors also note that their approach may not be effective against all types of vulnerabilities, and that further research is needed to explore the broader implications of using language models for evasion attacks.
One potential concern raised is the possibility of the EaTVul attack being used to create sophisticated malware or other malicious content that could be difficult to detect and mitigate. This highlights the need for ongoing research and development of robust countermeasures to address the evolving threat landscape.
Conclusion
The EaTVul paper presents a novel and concerning vulnerability in software security, demonstrating how advanced language models can be leveraged to bypass vulnerability detection systems. The attack is shown to be highly effective and efficient, posing a significant threat to the cybersecurity community.
While the paper acknowledges certain limitations, the broader implications of this research underscore the need for continued innovation in security technologies and the development of new strategies to address the emerging risks posed by language model-based evasion attacks. As the security landscape evolves, it is crucial for researchers and practitioners to remain vigilant and proactive in the face of these emerging threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EaTVul: ChatGPT-based Evasion Attack Against Software Vulnerability Detection
Shigang Liu, Di Cao, Junae Kim, Tamas Abraham, Paul Montague, Seyit Camtepe, Jun Zhang, Yang Xiang
Recently, deep learning has demonstrated promising results in enhancing the accuracy of vulnerability detection and identifying vulnerabilities in software. However, these techniques are still vulnerable to attacks. Adversarial examples can exploit vulnerabilities within deep neural networks, posing a significant threat to system security. This study showcases the susceptibility of deep learning models to adversarial attacks, which can achieve 100% attack success rate (refer to Table 5). The proposed method, EaTVul, encompasses six stages: identification of important samples using support vector machines, identification of important features using the attention mechanism, generation of adversarial data based on these features using ChatGPT, preparation of an adversarial attack pool, selection of seed data using a fuzzy genetic algorithm, and the execution of an evasion attack. Extensive experiments demonstrate the effectiveness of EaTVul, achieving an attack success rate of more than 83% when the snippet size is greater than 2. Furthermore, in most cases with a snippet size of 4, EaTVul achieves a 100% attack success rate. The findings of this research emphasize the necessity of robust defenses against adversarial attacks in software vulnerability detection.
Read more7/30/2024
0
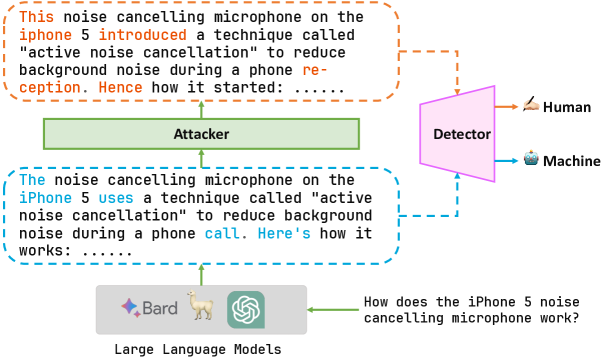
Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
Ying Zhou, Ben He, Le Sun
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
Read more4/3/2024

0
Constrained Adaptive Attack: Effective Adversarial Attack Against Deep Neural Networks for Tabular Data
Thibault Simonetto, Salah Ghamizi, Maxime Cordy
State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there are no effective attacks to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data, such as categorical features, immutability, and feature relationship constraints. To fill this gap, we first propose CAPGD, a gradient attack that overcomes the failures of existing gradient attacks with adaptive mechanisms. This new attack does not require parameter tuning and further degrades the accuracy, up to 81% points compared to the previous gradient attacks. Second, we design CAA, an efficient evasion attack that combines our CAPGD attack and MOEVA, the best search-based attack. We demonstrate the effectiveness of our attacks on five architectures and four critical use cases. Our empirical study demonstrates that CAA outperforms all existing attacks in 17 over the 20 settings, and leads to a drop in the accuracy by up to 96.1% points and 21.9% points compared to CAPGD and MOEVA respectively while being up to five times faster than MOEVA. Given the effectiveness and efficiency of our new attacks, we argue that they should become the minimal test for any new defense or robust architectures in tabular machine learning.
Read more6/4/2024
🌀
0
Automated Software Vulnerability Static Code Analysis Using Generative Pre-Trained Transformer Models
Elijah Pelofske, Vincent Urias, Lorie M. Liebrock
Generative Pre-Trained Transformer models have been shown to be surprisingly effective at a variety of natural language processing tasks -- including generating computer code. We evaluate the effectiveness of open source GPT models for the task of automatic identification of the presence of vulnerable code syntax (specifically targeting C and C++ source code). This task is evaluated on a selection of 36 source code examples from the NIST SARD dataset, which are specifically curated to not contain natural English that indicates the presence, or lack thereof, of a particular vulnerability. The NIST SARD source code dataset contains identified vulnerable lines of source code that are examples of one out of the 839 distinct Common Weakness Enumerations (CWE), allowing for exact quantification of the GPT output classification error rate. A total of 5 GPT models are evaluated, using 10 different inference temperatures and 100 repetitions at each setting, resulting in 5,000 GPT queries per vulnerable source code analyzed. Ultimately, we find that the GPT models that we evaluated are not suitable for fully automated vulnerability scanning because the false positive and false negative rates are too high to likely be useful in practice. However, we do find that the GPT models perform surprisingly well at automated vulnerability detection for some of the test cases, in particular surpassing random sampling, and being able to identify the exact lines of code that are vulnerable albeit at a low success rate. The best performing GPT model result found was Llama-2-70b-chat-hf with inference temperature of 0.1 applied to NIST SARD test case 149165 (which is an example of a buffer overflow vulnerability), which had a binary classification recall score of 1.0 and a precision of 1.0 for correctly and uniquely identifying the vulnerable line of code and the correct CWE number.
Read more8/2/2024