Effective Black Box Testing of Sentiment Analysis Classification Networks

0

Sign in to get full access
Overview
- Sentiment analysis classification networks are AI models used to determine the emotional tone of text, like whether a review is positive or negative.
- This paper explores effective black box testing techniques to assess the reliability and robustness of these sentiment analysis models.
- The researchers focus on using "coverage criteria" - specific test cases designed to expose weaknesses in the model's performance.
Plain English Explanation
The paper looks at ways to thoroughly test sentiment analysis AI models that classify text as positive, negative, or neutral. These models are often used to analyze things like product reviews or social media posts.
The researchers wanted to find effective "black box" testing methods - ways to evaluate the model's performance without knowing the details of how it works internally. They focused on using "coverage criteria," which are specific test cases designed to uncover weaknesses in the model's capabilities.
For example, one test might be to see how the model handles text with sarcasm or irony, which can be challenging for some sentiment analysis systems. Another test could look at how the model deals with ambiguous or contradictory language. The goal is to push the model to its limits and identify areas where it may struggle or make mistakes.
By thoroughly testing the models in this way, the researchers hope to improve their reliability and robustness, making them more trustworthy for real-world applications like analyzing Reddit comments or targeted sentiment analysis.
Technical Explanation
The paper proposes a methodology for effective black box testing of sentiment analysis classification networks using coverage criteria. The researchers first define several coverage criteria, including:
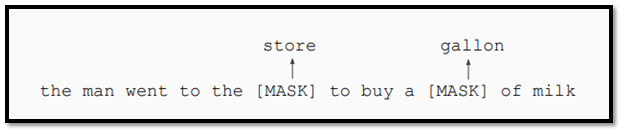
- Lexical Coverage: Ensuring the model handles a diverse set of vocabulary, including rare words, domain-specific terms, and words with multiple meanings.
- Semantic Coverage: Testing the model's ability to correctly interpret the sentiment of text with complex semantics, such as sarcasm, irony, or contradictions.
- Contextual Coverage: Evaluating how the model handles text where sentiment is influenced by surrounding context, like negation or intensifiers.
They then develop a systematic approach to generate test cases that satisfy these coverage criteria, using techniques like adversarial text generation and dataset augmentation. The researchers evaluate their methodology on several popular sentiment analysis models, including transformer-based architectures.
Their results show that the proposed coverage-guided testing can uncover significant performance gaps and reliability issues in the examined models, highlighting the importance of thorough black box testing for sentiment analysis systems.
Critical Analysis
The paper provides a well-designed and comprehensive approach to black box testing of sentiment analysis models. By focusing on coverage criteria, the researchers have developed a systematic way to identify weaknesses in model performance that may not be evident from standard evaluation metrics.
However, the authors acknowledge that their methodology is limited to the specific coverage criteria they have defined. There may be other important aspects of model behavior that are not captured by these tests, such as the model's sensitivity to adversarial attacks or its performance on real-world, noisy data.
Additionally, the paper does not explore the relationship between the identified performance gaps and the internal workings of the models. Understanding the underlying reasons for the observed issues could lead to more targeted model improvements.
Future research could investigate ways to expand the coverage criteria, perhaps by drawing insights from human annotation studies or analyzing common failure modes in deployed sentiment analysis systems. Integrating the testing approach with model interpretability techniques could also help shed light on the root causes of the identified weaknesses.
Conclusion
This paper presents an effective methodology for black box testing of sentiment analysis classification networks using coverage criteria. By systematically evaluating model performance on diverse test cases, the researchers have uncovered significant reliability issues in several popular sentiment analysis models.
The findings highlight the importance of thorough testing for AI systems, especially those deployed in high-stakes applications. The proposed coverage-guided approach can help developers and researchers improve the robustness and trustworthiness of sentiment analysis models, ultimately leading to more reliable and impactful natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Effective Black Box Testing of Sentiment Analysis Classification Networks
Parsa Karbasizadeh, Fathiyeh Faghih, Pouria Golshanrad
Transformer-based neural networks have demonstrated remarkable performance in natural language processing tasks such as sentiment analysis. Nevertheless, the issue of ensuring the dependability of these complicated architectures through comprehensive testing is still open. This paper presents a collection of coverage criteria specifically designed to assess test suites created for transformer-based sentiment analysis networks. Our approach utilizes input space partitioning, a black-box method, by considering emotionally relevant linguistic features such as verbs, adjectives, adverbs, and nouns. In order to effectively produce test cases that encompass a wide range of emotional elements, we utilize the k-projection coverage metric. This metric minimizes the complexity of the problem by examining subsets of k features at the same time, hence reducing dimensionality. Large language models are employed to generate sentences that display specific combinations of emotional features. The findings from experiments obtained from a sentiment analysis dataset illustrate that our criteria and generated tests have led to an average increase of 16% in test coverage. In addition, there is a corresponding average decrease of 6.5% in model accuracy, showing the ability to identify vulnerabilities. Our work provides a foundation for improving the dependability of transformer-based sentiment analysis systems through comprehensive test evaluation.
Read more7/31/2024
0
Transfer Learning and Transformer Architecture for Financial Sentiment Analysis
Tohida Rehman, Raghubir Bose, Samiran Chattopadhyay, Debarshi Kumar Sanyal
Financial sentiment analysis allows financial institutions like Banks and Insurance Companies to better manage the credit scoring of their customers in a better way. Financial domain uses specialized mechanisms which makes sentiment analysis difficult. In this paper, we propose a pre-trained language model which can help to solve this problem with fewer labelled data. We extend on the principles of Transfer learning and Transformation architecture principles and also take into consideration recent outbreak of pandemics like COVID. We apply the sentiment analysis to two different sets of data. We also take smaller training set and fine tune the same as part of the model.
Read more5/6/2024
🏷️
0
New Directions in Text Classification Research: Maximizing The Performance of Sentiment Classification from Limited Data
Surya Agustian, Muhammad Irfan Syah, Nurul Fatiara, Rahmad Abdillah
The stakeholders' needs in sentiment analysis for various issues, whether positive or negative, are speed and accuracy. One new challenge in sentiment analysis tasks is the limited training data, which often leads to suboptimal machine learning models and poor performance on test data. This paper discusses the problem of text classification based on limited training data (300 to 600 samples) into three classes: positive, negative, and neutral. A benchmark dataset is provided for training and testing data on the issue of Kaesang Pangarep's appointment as Chairman of PSI. External data for aggregation and augmentation purposes are provided, consisting of two datasets: the topic of Covid Vaccination sentiment and an open topic. The official score used is the F1-score, which balances precision and recall among the three classes, positive, negative, and neutral. A baseline score is provided as a reference for researchers for unoptimized classification methods. The optimized score is provided as a reference for the target score to be achieved by any proposed method. Both scoring (baseline and optimized) use the SVM method, which is widely reported as the state-of-the-art in conventional machine learning methods. The F1-scores achieved by the baseline and optimized methods are 40.83% and 51.28%, respectively.
Read more7/9/2024
🚀
0
Performance evaluation of Reddit Comments using Machine Learning and Natural Language Processing methods in Sentiment Analysis
Xiaoxia Zhang, Xiuyuan Qi, Zixin Teng
Sentiment analysis, an increasingly vital field in both academia and industry, plays a pivotal role in machine learning applications, particularly on social media platforms like Reddit. However, the efficacy of sentiment analysis models is hindered by the lack of expansive and fine-grained emotion datasets. To address this gap, our study leverages the GoEmotions dataset, comprising a diverse range of emotions, to evaluate sentiment analysis methods across a substantial corpus of 58,000 comments. Distinguished from prior studies by the Google team, which limited their analysis to only two models, our research expands the scope by evaluating a diverse array of models. We investigate the performance of traditional classifiers such as Naive Bayes and Support Vector Machines (SVM), as well as state-of-the-art transformer-based models including BERT, RoBERTa, and GPT. Furthermore, our evaluation criteria extend beyond accuracy to encompass nuanced assessments, including hierarchical classification based on varying levels of granularity in emotion categorization. Additionally, considerations such as computational efficiency are incorporated to provide a comprehensive evaluation framework. Our findings reveal that the RoBERTa model consistently outperforms the baseline models, demonstrating superior accuracy in fine-grained sentiment classification tasks. This underscores the substantial potential and significance of the RoBERTa model in advancing sentiment analysis capabilities.
Read more5/29/2024