Large Language Models in Targeted Sentiment Analysis
2404.12342
0
0
💬
Abstract
In this paper we investigate the use of decoder-based generative transformers for extracting sentiment towards the named entities in Russian news articles. We study sentiment analysis capabilities of instruction-tuned large language models (LLMs). We consider the dataset of RuSentNE-2023 in our study. The first group of experiments was aimed at the evaluation of zero-shot capabilities of LLMs with closed and open transparencies. The second covers the fine-tuning of Flan-T5 using the chain-of-thought (CoT) three-hop reasoning framework (THoR). We found that the results of the zero-shot approaches are similar to the results achieved by baseline fine-tuned encoder-based transformers (BERT-base). Reasoning capabilities of the fine-tuned Flan-T5 models with THoR achieve at least 5% increment with the base-size model compared to the results of the zero-shot experiment. The best results of sentiment analysis on RuSentNE-2023 were achieved by fine-tuned Flan-T5-xl, which surpassed the results of previous state-of-the-art transformer-based classifiers. Our CoT application framework is publicly available: https://github.com/nicolay-r/Reasoning-for-Sentiment-Analysis-Framework
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The researchers investigate the use of decoder-based generative transformers for extracting sentiment towards named entities in Russian news articles.
- They study the sentiment analysis capabilities of large language models (LLMs) that have been instruction-tuned.
- The study focuses on the RuSentNE-2023 dataset.
- The first set of experiments evaluates the zero-shot capabilities of LLMs with closed and open transparencies.
- The second set of experiments involves fine-tuning the Flan-T5 model using a chain-of-thought (CoT) three-hop reasoning framework (THoR).
Plain English Explanation
The researchers wanted to see how well large language models (LLMs) that have been trained on instructions can analyze the sentiment (positive or negative feelings) towards specific people, organizations, or other entities mentioned in Russian news articles. They used a dataset called RuSentNE-2023, which contains Russian news articles with sentiment annotations.
First, they tested the LLMs' ability to do this task without any additional training, just using the natural language understanding they already had. This is called "zero-shot" learning. They found that the zero-shot performance was similar to what baseline transformer models (like BERT) could do.
Next, they fine-tuned the Flan-T5 LLM using a special reasoning framework that helps the model break down the task into a few steps of thinking. This improved the sentiment analysis performance by at least 5% compared to the zero-shot results.
The best results came from the fine-tuned Flan-T5-xl model, which outperformed previous state-of-the-art transformer-based classifiers on the RuSentNE-2023 dataset.
Technical Explanation
The researchers conducted two main experiments. In the first, they evaluated the zero-shot capabilities of LLMs for sentiment analysis on the RuSentNE-2023 dataset. They tested both closed-transparency LLMs, which have limited information about their own inner workings, and open-transparency LLMs, which provide more details about their decision-making.
The second set of experiments involved fine-tuning the Flan-T5 model using a chain-of-thought (CoT) three-hop reasoning framework (THoR). This framework helps the model break down the sentiment analysis task into a sequence of reasoning steps.
The researchers found that the zero-shot performance of the LLMs was similar to that of baseline fine-tuned encoder-based transformers like BERT. However, the fine-tuned Flan-T5 models with the THoR reasoning framework achieved at least a 5% improvement in performance compared to the zero-shot results.
The best-performing model was the fine-tuned Flan-T5-xl, which outperformed previous state-of-the-art transformer-based sentiment analysis classifiers on the RuSentNE-2023 dataset.
Critical Analysis
The paper provides a thorough evaluation of LLM sentiment analysis capabilities on the RuSentNE-2023 dataset. However, it does not delve into the potential limitations or biases of the dataset itself, which could impact the generalizability of the results.
Additionally, while the chain-of-thought reasoning framework improved performance, the paper does not explore the interpretability or explainability of the model's decision-making process. Understanding how the model arrives at its sentiment predictions could be valuable for real-world applications.
Further research could investigate the performance of these LLM-based approaches on other languages and domains beyond Russian news articles. Exploring the transfer learning capabilities of the models would also be an interesting avenue for future work.
Conclusion
This study demonstrates the potential of decoder-based generative transformers for sentiment analysis on Russian news articles. While the zero-shot performance of LLMs was on par with baseline models, fine-tuning the Flan-T5 model with a chain-of-thought reasoning framework led to a significant improvement in sentiment analysis accuracy.
The findings suggest that instruction-tuned LLMs can be effectively leveraged for complex natural language processing tasks, such as extracting sentiment towards named entities in news articles. This research contributes to the growing body of work on the capabilities of large language models and provides a framework for further exploration in the field of sentiment analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
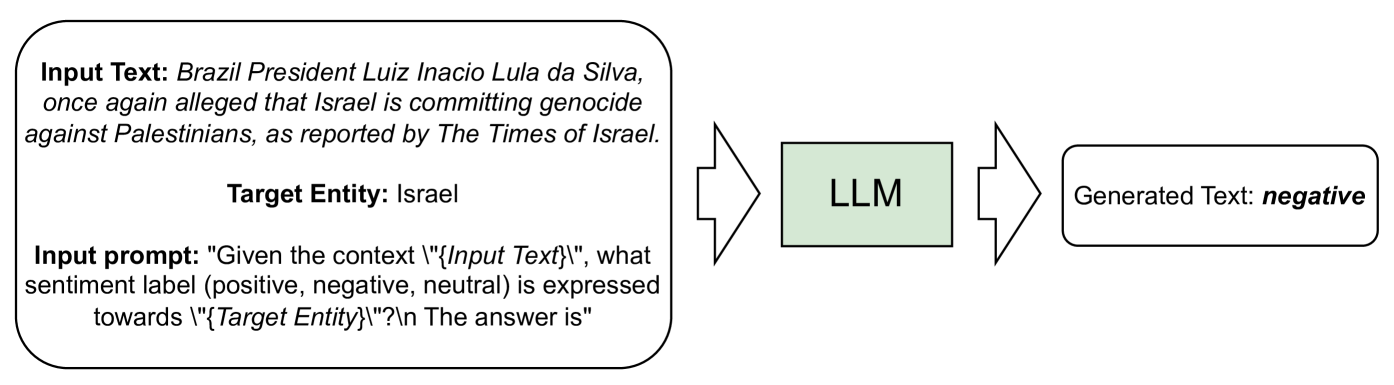
Deciphering Political Entity Sentiment in News with Large Language Models: Zero-Shot and Few-Shot Strategies
Alapan Kuila, Sudeshna Sarkar
0
0
Sentiment analysis plays a pivotal role in understanding public opinion, particularly in the political domain where the portrayal of entities in news articles influences public perception. In this paper, we investigate the effectiveness of Large Language Models (LLMs) in predicting entity-specific sentiment from political news articles. Leveraging zero-shot and few-shot strategies, we explore the capability of LLMs to discern sentiment towards political entities in news content. Employing a chain-of-thought (COT) approach augmented with rationale in few-shot in-context learning, we assess whether this method enhances sentiment prediction accuracy. Our evaluation on sentiment-labeled datasets demonstrates that LLMs, outperform fine-tuned BERT models in capturing entity-specific sentiment. We find that learning in-context significantly improves model performance, while the self-consistency mechanism enhances consistency in sentiment prediction. Despite the promising results, we observe inconsistencies in the effectiveness of the COT prompting method. Overall, our findings underscore the potential of LLMs in entity-centric sentiment analysis within the political news domain and highlight the importance of suitable prompting strategies and model architectures.
4/9/2024
⚙️
Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
Md. Arid Hasan, Shudipta Das, Afiyat Anjum, Firoj Alam, Anika Anjum, Avijit Sarker, Sheak Rashed Haider Noori
0
0
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,606 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community.
4/8/2024
Transfer Learning and Transformer Architecture for Financial Sentiment Analysis
Tohida Rehman, Raghubir Bose, Samiran Chattopadhyay, Debarshi Kumar Sanyal
0
0
Financial sentiment analysis allows financial institutions like Banks and Insurance Companies to better manage the credit scoring of their customers in a better way. Financial domain uses specialized mechanisms which makes sentiment analysis difficult. In this paper, we propose a pre-trained language model which can help to solve this problem with fewer labelled data. We extend on the principles of Transfer learning and Transformation architecture principles and also take into consideration recent outbreak of pandemics like COVID. We apply the sentiment analysis to two different sets of data. We also take smaller training set and fine tune the same as part of the model.
5/6/2024
🛠️
New!Optimization Techniques for Sentiment Analysis Based on LLM (GPT-3)
Tong Zhan, Chenxi Shi, Yadong Shi, Huixiang Li, Yiyu Lin
0
0
With the rapid development of natural language processing (NLP) technology, large-scale pre-trained language models such as GPT-3 have become a popular research object in NLP field. This paper aims to explore sentiment analysis optimization techniques based on large pre-trained language models such as GPT-3 to improve model performance and effect and further promote the development of natural language processing (NLP). By introducing the importance of sentiment analysis and the limitations of traditional methods, GPT-3 and Fine-tuning techniques are introduced in this paper, and their applications in sentiment analysis are explained in detail. The experimental results show that the Fine-tuning technique can optimize GPT-3 model and obtain good performance in sentiment analysis task. This study provides an important reference for future sentiment analysis using large-scale language models.
5/17/2024