On the Effects of Heterogeneous Data Sources on Speech-to-Text Foundation Models

0

Sign in to get full access
Overview
- This paper investigates the effects of using heterogeneous data sources on the performance of speech-to-text foundation models.
- The researchers explore how incorporating diverse datasets, including audio recordings from different domains and modalities, can impact the accuracy and robustness of these models.
- The study provides insights into the tradeoffs and challenges involved in building large-scale speech recognition systems that can handle a wide range of input data.
Plain English Explanation
Speech-to-text foundation models are AI systems that can transcribe spoken language into written text. These models are trained on large datasets of audio recordings and their corresponding transcripts. However, the data used to train these models often comes from a limited set of sources, which can make them less effective at handling diverse types of speech.
In this paper, the researchers investigate the benefits and challenges of using heterogeneous data sources to train speech-to-text foundation models. They explore how incorporating a wider range of audio recordings, including those from different domains (e.g., audio quality of speech-to-text systems on various noisy environments) and modalities (e.g., speech recognition for whispered speech), can impact the model's performance.
The researchers' findings provide valuable insights for researchers and developers working on building robust and versatile speech-to-text systems. By understanding the trade-offs involved in using diverse data sources, they can develop more effective strategies for training large-scale speech recognition models that can handle a wide range of input data, including multilingual and multi-speaker scenarios and Chinese-language speech recognition.
Technical Explanation
The paper explores the impact of using heterogeneous data sources on the performance of speech-to-text foundation models. The researchers collected a diverse dataset of audio recordings from various domains, including broadcast news, podcasts, and conversational speech. They then trained several speech recognition models using this heterogeneous data, as well as models trained on more homogeneous datasets, and compared their performance on a range of test sets.
The results show that incorporating diverse data sources can lead to improvements in overall model accuracy, particularly on test sets that differ significantly from the training data. However, the researchers also identified some challenges, such as the need for effective data augmentation and domain adaptation techniques to mitigate potential negative transfer effects from incompatible data sources.
The paper provides a detailed analysis of the trade-offs involved in leveraging heterogeneous data for speech-to-text foundation models, including the impact on model architecture, loss functions, and training strategies. The findings from this study can inform the development of more robust and versatile speech recognition systems that can handle a wide range of input data.
Critical Analysis
The paper presents a thorough investigation of the effects of using heterogeneous data sources on speech-to-text foundation models. The researchers have carefully designed their experiments and provided a comprehensive analysis of the results.
One potential limitation of the study is the lack of exploration into the specific mechanisms by which diverse data sources can impact model performance. While the paper identifies the overall trends and trade-offs, a more in-depth investigation into the underlying causes and the specific model behaviors would further strengthen the insights.
Additionally, the paper could have benefited from a more extensive discussion of the potential biases and fairness implications of using heterogeneous data. As speech recognition systems are deployed in increasingly diverse real-world settings, understanding and mitigating any demographic or socioeconomic biases introduced by the training data becomes crucial.
Overall, the research presented in this paper provides valuable contributions to the field of speech recognition and highlights the importance of considering the diversity and representativeness of the training data when developing large-scale speech-to-text models. Further work in this direction, addressing the limitations and exploring additional implications, could lead to even more robust and equitable speech recognition systems.
Conclusion
This paper offers a comprehensive investigation of the effects of using heterogeneous data sources on the performance of speech-to-text foundation models. The researchers' findings suggest that incorporating diverse audio recordings, covering a range of domains and modalities, can lead to improved model accuracy and robustness, particularly on test sets that differ from the training data.
The insights gained from this study can inform the development of more versatile and effective speech recognition systems, which are crucial for a wide range of applications, from virtual assistants to language learning tools. By understanding the trade-offs and challenges involved in leveraging heterogeneous data sources, researchers and developers can design better strategies for training large-scale speech-to-text models that can handle diverse input and deliver high-quality transcriptions across a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Effects of Heterogeneous Data Sources on Speech-to-Text Foundation Models
Jinchuan Tian, Yifan Peng, William Chen, Kwanghee Choi, Karen Livescu, Shinji Watanabe
The Open Whisper-style Speech Model (OWSM) series was introduced to achieve full transparency in building advanced speech-to-text (S2T) foundation models. To this end, OWSM models are trained on 25 public speech datasets, which are heterogeneous in multiple ways. In this study, we advance the OWSM series by introducing OWSM v3.2, which improves on prior models by investigating and addressing the impacts of this data heterogeneity. Our study begins with a detailed analysis of each dataset, from which we derive two key strategies: data filtering with proxy task to enhance data quality, and the incorporation of punctuation and true-casing using an open large language model (LLM). With all other configurations staying the same, OWSM v3.2 improves performance over the OWSM v3.1 baseline while using 15% less training data.
Read more6/14/2024
🗣️
0
OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Yifan Peng, Jinchuan Tian, William Chen, Siddhant Arora, Brian Yan, Yui Sudo, Muhammad Shakeel, Kwanghee Choi, Jiatong Shi, Xuankai Chang, Jee-weon Jung, Shinji Watanabe
Recent studies have highlighted the importance of fully open foundation models. The Open Whisper-style Speech Model (OWSM) is an initial step towards reproducing OpenAI Whisper using public data and open-source toolkits. However, previous versions of OWSM (v1 to v3) are still based on standard Transformer, which might lead to inferior performance compared to state-of-the-art speech encoder architectures. This work aims to improve the performance and efficiency of OWSM without additional data. We present a series of E-Branchformer-based models named OWSM v3.1, ranging from 100M to 1B parameters. OWSM v3.1 outperforms its predecessor, OWSM v3, in most evaluation benchmarks, while showing an improved inference speed of up to 25%. We further reveal the emergent ability of OWSM v3.1 in zero-shot contextual biasing speech recognition. We also provide a model trained on a subset of data with low license restrictions. We will publicly release the code, pre-trained models, and training logs.
Read more8/28/2024
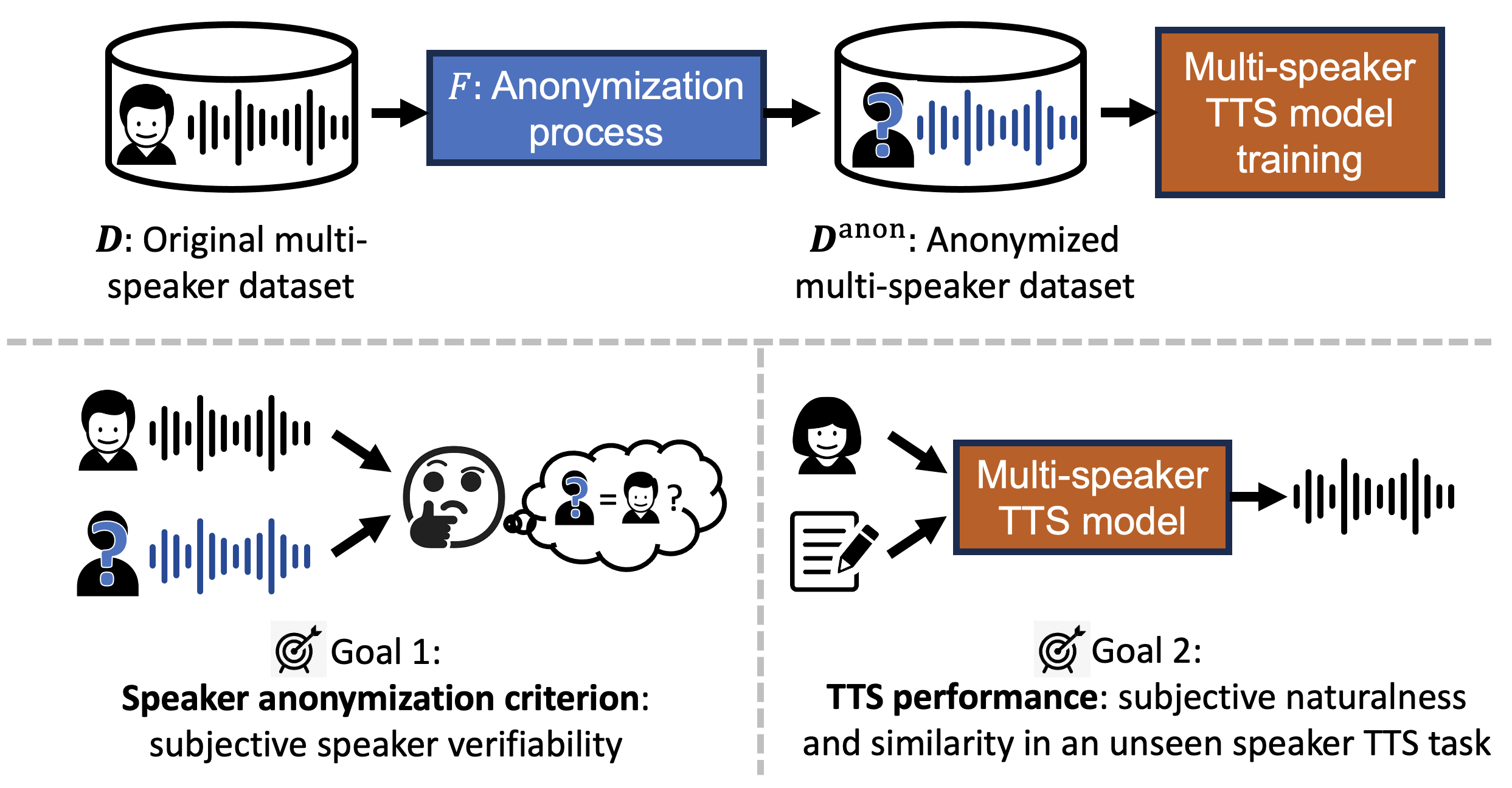
0
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
Read more5/21/2024

0
OWSM-CTC: An Open Encoder-Only Speech Foundation Model for Speech Recognition, Translation, and Language Identification
Yifan Peng, Yui Sudo, Muhammad Shakeel, Shinji Watanabe
There has been an increasing interest in large speech models that can perform multiple tasks in a single model. Such models usually adopt an encoder-decoder or decoder-only architecture due to their popularity and good performance in many domains. However, autoregressive models can be slower during inference compared to non-autoregressive models and also have potential risks of hallucination. Though prior studies observed promising results of non-autoregressive models for certain tasks at small scales, it remains unclear if they can be scaled to speech-to-text generation in diverse languages and tasks. Inspired by the Open Whisper-style Speech Model (OWSM) project, we propose OWSM-CTC, a novel encoder-only speech foundation model based on Connectionist Temporal Classification (CTC). It is trained on 180k hours of public audio data for multilingual automatic speech recognition (ASR), speech translation (ST), and language identification (LID). Compared to encoder-decoder OWSM, our OWSM-CTC achieves competitive results on ASR and up to 24% relative improvement on ST, while it is more robust and 3 to 4 times faster for inference. OWSM-CTC also improves the long-form ASR result with 20x speed-up. We will publicly release our code, pre-trained model, and training logs to promote open science in speech foundation models.
Read more8/28/2024