Efficient Adaptation in Mixed-Motive Environments via Hierarchical Opponent Modeling and Planning
2406.08002
0
0

Abstract
Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge. One feasible approach is to hierarchically model co-players' behavior based on inferring their characteristics. However, these methods often encounter difficulties in efficient reasoning and utilization of inferred information. To address these issues, we propose Hierarchical Opponent modeling and Planning (HOP), a novel multi-agent decision-making algorithm that enables few-shot adaptation to unseen policies in mixed-motive environments. HOP is hierarchically composed of two modules: an opponent modeling module that infers others' goals and learns corresponding goal-conditioned policies, and a planning module that employs Monte Carlo Tree Search (MCTS) to identify the best response. Our approach improves efficiency by updating beliefs about others' goals both across and within episodes and by using information from the opponent modeling module to guide planning. Experimental results demonstrate that in mixed-motive environments, HOP exhibits superior few-shot adaptation capabilities when interacting with various unseen agents, and excels in self-play scenarios. Furthermore, the emergence of social intelligence during our experiments underscores the potential of our approach in complex multi-agent environments.
Create account to get full access
Overview
- This paper presents a hierarchical opponent modeling and planning approach to enable efficient adaptation in mixed-motive environments, where agents have both collaborative and competitive objectives.
- The proposed method, called Efficient Adaptation in Mixed-Motive Environments via Hierarchical Opponent Modeling and Planning, allows agents to model their opponents' behaviors and plan their actions accordingly to achieve their own goals.
- The paper demonstrates the effectiveness of this approach through experiments in complex multi-agent environments, showing improved performance compared to baseline methods.
Plain English Explanation
In many real-world scenarios, such as business negotiations or multiplayer games, we often find ourselves in "mixed-motive" environments. These are situations where we have both collaborative and competitive objectives with other agents or players. For example, in a business deal, we may want to cooperate to reach an agreement, but we also want to secure the best possible terms for ourselves.
The challenge in these mixed-motive environments is to find a way to efficiently adapt our strategies and actions to achieve our goals, while also taking into account the goals and behaviors of our opponents or collaborators. This paper presents a novel approach to address this challenge.
The key idea is to use a hierarchical model to understand and predict the behaviors of our opponents. By building a detailed model of how our opponents think and act, we can then plan our own actions more effectively to outmaneuver them or find mutually beneficial compromises.
Imagine a simple game of chess. If we can accurately predict our opponent's next moves, we can plan our own moves to counter them and gain an advantage. Similarly, in a business negotiation, if we can anticipate how the other party might respond to our proposals, we can tailor our strategies to get a better deal.
The authors of this paper have developed a sophisticated algorithm that allows agents to build these hierarchical opponent models and use them to plan their actions in complex, mixed-motive environments. Through experiments, they demonstrate that this approach can significantly improve the performance of agents compared to other, more traditional methods.
Technical Explanation
The paper introduces a hierarchical opponent modeling and planning approach to enable efficient adaptation in mixed-motive environments. The key components of the proposed method are:
-
Opponent Modeling: The agents build a hierarchical model of their opponents' behaviors, capturing both their goals and decision-making processes. This is done by learning a cognitive hierarchy that represents the different levels of opponent reasoning.
-
Planning: Using the opponent model, the agents can then plan their own actions to achieve their objectives, taking into account the predicted responses of their opponents. This is accomplished through a multi-agent planning algorithm that considers the adaptive opponent policies of the other agents.
The experiments conducted in the paper demonstrate the effectiveness of this approach in complex multi-agent environments. The proposed method outperforms baseline approaches in terms of both individual and joint performance, showcasing its ability to enable efficient adaptation in mixed-motive settings.
Critical Analysis
The paper presents a compelling approach to address the challenge of efficient adaptation in mixed-motive environments. The key strength of the proposed method is its ability to build a detailed, hierarchical model of opponents' behaviors, which allows the agents to plan their actions more effectively.
However, the paper also acknowledges several limitations and areas for further research. For instance, the hierarchical opponent modeling assumes that the opponents' decision-making processes can be accurately captured by the cognitive hierarchy. In more complex or dynamic environments, this assumption may not always hold true.
Additionally, the planning algorithm relies on the accuracy of the opponent model, which can be sensitive to noise or incomplete information. The paper suggests exploring alternative planning approaches, such as robust optimization, to address this limitation.
Another potential area for improvement is the computational efficiency of the proposed method, as the hierarchical modeling and planning can be computationally intensive, especially in large-scale environments. Investigating more efficient algorithms or approximation techniques could help address this concern.
Overall, the paper presents a promising approach to enable efficient adaptation in mixed-motive environments, but further research is needed to address the identified limitations and explore additional applications and extensions of the proposed framework.
Conclusion
This paper introduces a novel hierarchical opponent modeling and planning approach to enable efficient adaptation in mixed-motive environments. By building a detailed model of their opponents' behaviors and decision-making processes, agents can plan their actions more effectively to achieve their goals, whether they are collaborative or competitive in nature.
The experimental results demonstrate the effectiveness of this approach, showcasing its ability to outperform baseline methods in complex multi-agent settings. While the paper acknowledges several limitations and areas for further research, the proposed framework represents an important step forward in addressing the challenge of efficient adaptation in mixed-motive environments.
The insights and techniques presented in this paper have the potential to significantly impact a wide range of applications, from business negotiations and strategic decision-making to multiplayer games and cooperative robotics. As the complexity of real-world interactions continues to grow, the ability to model and adapt to the behaviors of others will become increasingly crucial for achieving desired outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
🚀
Detecting and Deterring Manipulation in a Cognitive Hierarchy
Nitay Alon, Lion Schulz, Joseph M. Barnby, Jeffrey S. Rosenschein, Peter Dayan
0
0
Social agents with finitely nested opponent models are vulnerable to manipulation by agents with deeper reasoning and more sophisticated opponent modelling. This imbalance, rooted in logic and the theory of recursive modelling frameworks, cannot be solved directly. We propose a computational framework, $aleph$-IPOMDP, augmenting model-based RL agents' Bayesian inference with an anomaly detection algorithm and an out-of-belief policy. Our mechanism allows agents to realize they are being deceived, even if they cannot understand how, and to deter opponents via a credible threat. We test this framework in both a mixed-motive and zero-sum game. Our results show the $aleph$ mechanism's effectiveness, leading to more equitable outcomes and less exploitation by more sophisticated agents. We discuss implications for AI safety, cybersecurity, cognitive science, and psychiatry.
5/6/2024

Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration
Xudong Guo, Daming Shi, Junjie Yu, Wenhui Fan
0
0
The rise of multi-agent systems, especially the success of multi-agent reinforcement learning (MARL), is reshaping our future across diverse domains like autonomous vehicle networks. However, MARL still faces significant challenges, particularly in achieving zero-shot scalability, which allows trained MARL models to be directly applied to unseen tasks with varying numbers of agents. In addition, real-world multi-agent systems usually contain agents with different functions and strategies, while the existing scalable MARL methods only have limited heterogeneity. To address this, we propose a novel MARL framework named Scalable and Heterogeneous Proximal Policy Optimization (SHPPO), integrating heterogeneity into parameter-shared PPO-based MARL networks. we first leverage a latent network to adaptively learn strategy patterns for each agent. Second, we introduce a heterogeneous layer for decision-making, whose parameters are specifically generated by the learned latent variables. Our approach is scalable as all the parameters are shared except for the heterogeneous layer, and gains both inter-individual and temporal heterogeneity at the same time. We implement our approach based on the state-of-the-art backbone PPO-based algorithm as SHPPO, while our approach is agnostic to the backbone and can be seamlessly plugged into any parameter-shared MARL method. SHPPO exhibits superior performance over the baselines such as MAPPO and HAPPO in classic MARL environments like Starcraft Multi-Agent Challenge (SMAC) and Google Research Football (GRF), showcasing enhanced zero-shot scalability and offering insights into the learned latent representation's impact on team performance by visualization.
4/8/2024
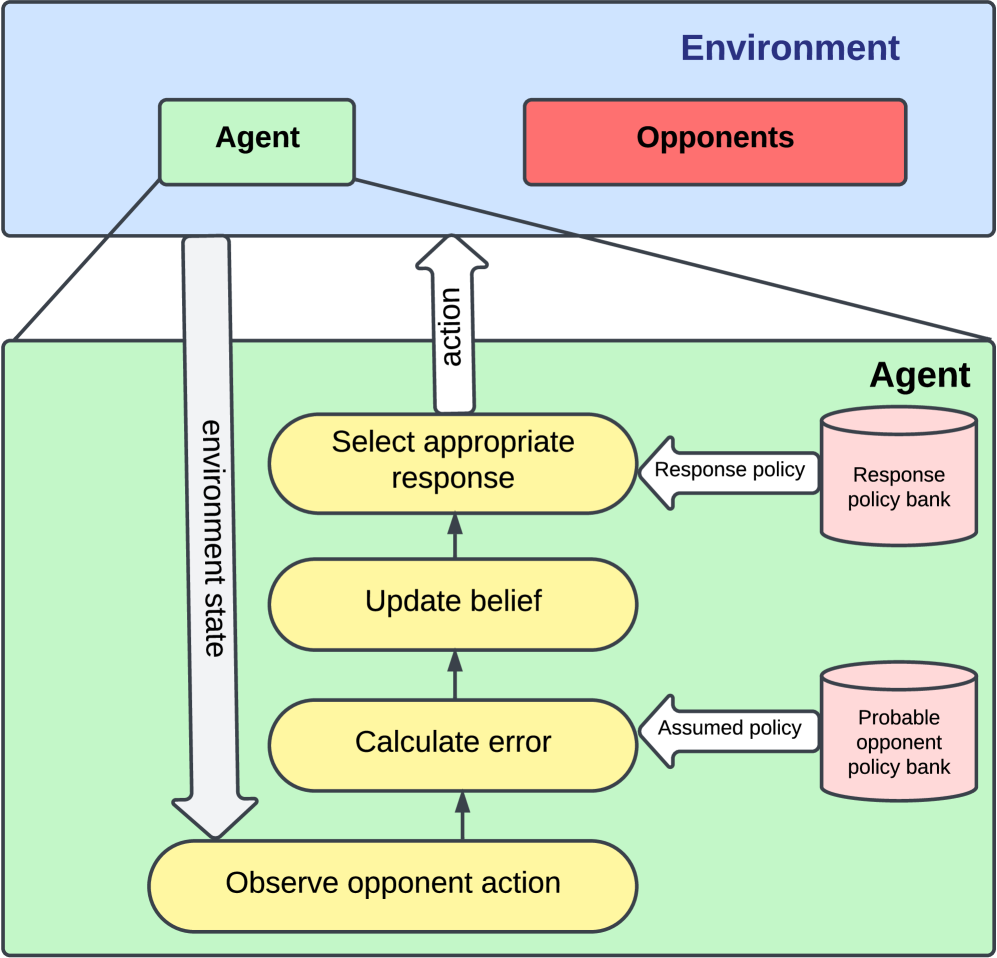
Adaptive Opponent Policy Detection in Multi-Agent MDPs: Real-Time Strategy Switch Identification Using Running Error Estimation
Mohidul Haque Mridul, Mohammad Foysal Khan, Redwan Ahmed Rizvee, Md Mosaddek Khan
0
0
In Multi-agent Reinforcement Learning (MARL), accurately perceiving opponents' strategies is essential for both cooperative and adversarial contexts, particularly within dynamic environments. While Proximal Policy Optimization (PPO) and related algorithms such as Actor-Critic with Experience Replay (ACER), Trust Region Policy Optimization (TRPO), and Deep Deterministic Policy Gradient (DDPG) perform well in single-agent, stationary environments, they suffer from high variance in MARL due to non-stationary and hidden policies of opponents, leading to diminished reward performance. Additionally, existing methods in MARL face significant challenges, including the need for inter-agent communication, reliance on explicit reward information, high computational demands, and sampling inefficiencies. These issues render them less effective in continuous environments where opponents may abruptly change their policies without prior notice. Against this background, we present OPS-DeMo (Online Policy Switch-Detection Model), an online algorithm that employs dynamic error decay to detect changes in opponents' policies. OPS-DeMo continuously updates its beliefs using an Assumed Opponent Policy (AOP) Bank and selects corresponding responses from a pre-trained Response Policy Bank. Each response policy is trained against consistently strategizing opponents, reducing training uncertainty and enabling the effective use of algorithms like PPO in multi-agent environments. Comparative assessments show that our approach outperforms PPO-trained models in dynamic scenarios like the Predator-Prey setting, providing greater robustness to sudden policy shifts and enabling more informed decision-making through precise opponent policy insights.
6/11/2024