Adaptive Opponent Policy Detection in Multi-Agent MDPs: Real-Time Strategy Switch Identification Using Running Error Estimation
2406.06500
0
0
Abstract
In Multi-agent Reinforcement Learning (MARL), accurately perceiving opponents' strategies is essential for both cooperative and adversarial contexts, particularly within dynamic environments. While Proximal Policy Optimization (PPO) and related algorithms such as Actor-Critic with Experience Replay (ACER), Trust Region Policy Optimization (TRPO), and Deep Deterministic Policy Gradient (DDPG) perform well in single-agent, stationary environments, they suffer from high variance in MARL due to non-stationary and hidden policies of opponents, leading to diminished reward performance. Additionally, existing methods in MARL face significant challenges, including the need for inter-agent communication, reliance on explicit reward information, high computational demands, and sampling inefficiencies. These issues render them less effective in continuous environments where opponents may abruptly change their policies without prior notice. Against this background, we present OPS-DeMo (Online Policy Switch-Detection Model), an online algorithm that employs dynamic error decay to detect changes in opponents' policies. OPS-DeMo continuously updates its beliefs using an Assumed Opponent Policy (AOP) Bank and selects corresponding responses from a pre-trained Response Policy Bank. Each response policy is trained against consistently strategizing opponents, reducing training uncertainty and enabling the effective use of algorithms like PPO in multi-agent environments. Comparative assessments show that our approach outperforms PPO-trained models in dynamic scenarios like the Predator-Prey setting, providing greater robustness to sudden policy shifts and enabling more informed decision-making through precise opponent policy insights.
Create account to get full access
Overview
- Presents a novel approach for detecting opponent strategy switches in multi-agent Markov Decision Processes (MDPs)
- Introduces a real-time strategy switch identification method using running error estimation
- Aims to enable adaptive decision-making in competitive multi-agent environments
Plain English Explanation
In competitive multi-agent environments, understanding and adapting to your opponent's strategy is crucial for success. This paper proposes a new method to help agents detect when their opponents change their strategy in real-time.
The key idea is to use a "running error estimation" technique to continuously monitor the agent's performance against its current model of the opponent's strategy. When the error suddenly increases, it signals that the opponent has likely switched to a new strategy, which the agent can then adapt to.
This approach allows agents to be more responsive and make better decisions in dynamic, multi-agent settings, such as online policy distillation, joint PPO in multi-agent RL, or efficient deep multi-agent reinforcement learning. By quickly detecting strategy switches, agents can update their own policies to better counter their opponents, leading to more successful outcomes.
Technical Explanation
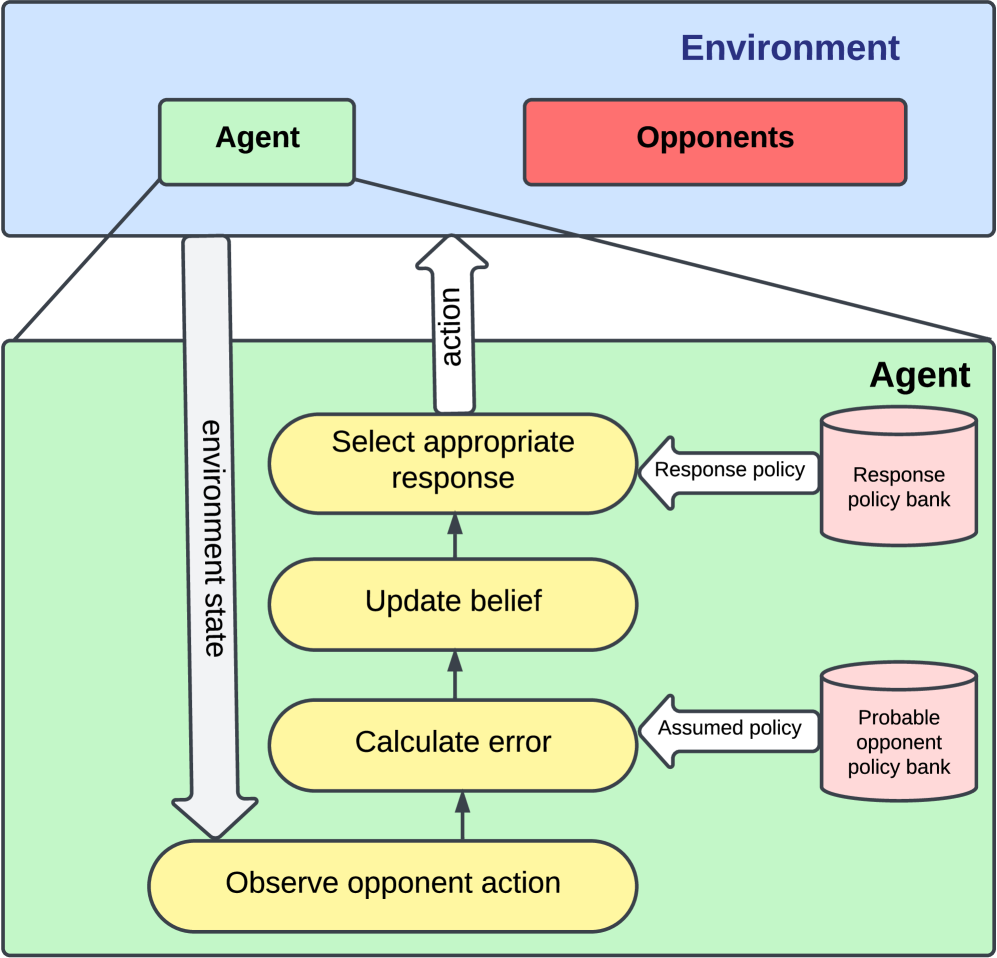
The paper proposes an "Adaptive Opponent Policy Detection" (AOPD) framework for identifying opponent strategy switches in multi-agent MDPs. The key components are:
- Opponent Policy Modeling: The agent maintains a set of candidate opponent policies, which it uses to predict the opponent's actions.
- Running Error Estimation: The agent continuously tracks the error between its predicted actions and the opponent's actual actions. A sudden increase in this error signals a strategy switch.
- Adaptive Decision-Making: When a strategy switch is detected, the agent updates its own policy to better counter the new opponent strategy.
The authors evaluate AOPD in a range of multi-agent environments, including a unified framework for RL under policy dynamics and reinforced token optimization for RLHF. The results show that AOPD outperforms baseline methods in terms of detecting strategy switches and improving the agent's performance.
Critical Analysis
The proposed AOPD framework appears to be a promising approach for enabling adaptive decision-making in multi-agent settings. By continuously monitoring for opponent strategy switches, agents can adjust their own policies to maintain an advantage.
However, the paper does not address some potential limitations of the method. For example, the running error estimation may be sensitive to noise or may struggle to detect subtle strategy changes. Additionally, the performance of AOPD may depend on the quality of the candidate opponent policies, which could be challenging to obtain in practice.
Further research could explore ways to make the error estimation more robust, as well as investigate methods for automatically learning or updating the candidate opponent policies. Incorporating additional contextual information, such as the game state or opponent behaviors, could also improve the switch detection capabilities of the framework.
Conclusion
This paper presents a novel approach for detecting opponent strategy switches in multi-agent MDPs, using a running error estimation technique. The proposed AOPD framework enables agents to adaptively update their policies in response to changes in their opponents' strategies, which can lead to improved performance in competitive multi-agent settings.
While the method shows promising results, further research is needed to address potential limitations and explore ways to enhance its robustness and versatility. Overall, the paper contributes an important step towards more adaptive and intelligent decision-making in complex, multi-agent environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Adaptation in Mixed-Motive Environments via Hierarchical Opponent Modeling and Planning
Yizhe Huang, Anji Liu, Fanqi Kong, Yaodong Yang, Song-Chun Zhu, Xue Feng
0
0
Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge. One feasible approach is to hierarchically model co-players' behavior based on inferring their characteristics. However, these methods often encounter difficulties in efficient reasoning and utilization of inferred information. To address these issues, we propose Hierarchical Opponent modeling and Planning (HOP), a novel multi-agent decision-making algorithm that enables few-shot adaptation to unseen policies in mixed-motive environments. HOP is hierarchically composed of two modules: an opponent modeling module that infers others' goals and learns corresponding goal-conditioned policies, and a planning module that employs Monte Carlo Tree Search (MCTS) to identify the best response. Our approach improves efficiency by updating beliefs about others' goals both across and within episodes and by using information from the opponent modeling module to guide planning. Experimental results demonstrate that in mixed-motive environments, HOP exhibits superior few-shot adaptation capabilities when interacting with various unseen agents, and excels in self-play scenarios. Furthermore, the emergence of social intelligence during our experiments underscores the potential of our approach in complex multi-agent environments.
6/13/2024

OMPO: A Unified Framework for RL under Policy and Dynamics Shifts
Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
0
0
Training reinforcement learning policies using environment interaction data collected from varying policies or dynamics presents a fundamental challenge. Existing works often overlook the distribution discrepancies induced by policy or dynamics shifts, or rely on specialized algorithms with task priors, thus often resulting in suboptimal policy performances and high learning variances. In this paper, we identify a unified strategy for online RL policy learning under diverse settings of policy and dynamics shifts: transition occupancy matching. In light of this, we introduce a surrogate policy learning objective by considering the transition occupancy discrepancies and then cast it into a tractable min-max optimization problem through dual reformulation. Our method, dubbed Occupancy-Matching Policy Optimization (OMPO), features a specialized actor-critic structure equipped with a distribution discriminator and a small-size local buffer. We conduct extensive experiments based on the OpenAI Gym, Meta-World, and Panda Robots environments, encompassing policy shifts under stationary and nonstationary dynamics, as well as domain adaption. The results demonstrate that OMPO outperforms the specialized baselines from different categories in all settings. We also find that OMPO exhibits particularly strong performance when combined with domain randomization, highlighting its potential in RL-based robotics applications
5/30/2024
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
6/17/2024
🏅
SUB-PLAY: Adversarial Policies against Partially Observed Multi-Agent Reinforcement Learning Systems
Oubo Ma, Yuwen Pu, Linkang Du, Yang Dai, Ruo Wang, Xiaolei Liu, Yingcai Wu, Shouling Ji
0
0
Recent advancements in multi-agent reinforcement learning (MARL) have opened up vast application prospects, such as swarm control of drones, collaborative manipulation by robotic arms, and multi-target encirclement. However, potential security threats during the MARL deployment need more attention and thorough investigation. Recent research reveals that attackers can rapidly exploit the victim's vulnerabilities, generating adversarial policies that result in the failure of specific tasks. For instance, reducing the winning rate of a superhuman-level Go AI to around 20%. Existing studies predominantly focus on two-player competitive environments, assuming attackers possess complete global state observation. In this study, we unveil, for the first time, the capability of attackers to generate adversarial policies even when restricted to partial observations of the victims in multi-agent competitive environments. Specifically, we propose a novel black-box attack (SUB-PLAY) that incorporates the concept of constructing multiple subgames to mitigate the impact of partial observability and suggests sharing transitions among subpolicies to improve attackers' exploitative ability. Extensive evaluations demonstrate the effectiveness of SUB-PLAY under three typical partial observability limitations. Visualization results indicate that adversarial policies induce significantly different activations of the victims' policy networks. Furthermore, we evaluate three potential defenses aimed at exploring ways to mitigate security threats posed by adversarial policies, providing constructive recommendations for deploying MARL in competitive environments.
6/27/2024