Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
2407.00945
0
0

Abstract
The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.
Create account to get full access
Overview
- This paper presents a method for efficiently pruning experts in sparse Mixture-of-Experts (MoE) language models to enhance performance and reduce inference costs.
- The proposed approach involves identifying and removing less important experts, leading to a more compact and efficient model without significant accuracy degradation.
- The authors demonstrate the effectiveness of their method on several language modeling benchmarks, showcasing improved performance and reduced computational requirements compared to previous sparse MoE models.
Plain English Explanation
Mixture-of-Experts (MoE) language models are a type of AI system that combine the outputs of multiple specialized "experts" to generate more accurate and diverse text. However, these models can be computationally expensive, especially during inference (the process of generating new text).
The researchers in this paper have developed a technique to "prune" or remove less important experts from the MoE model, making it more efficient without losing much accuracy. By identifying and removing the weakest experts, they can create a more compact model that is faster and cheaper to run, while still maintaining the benefits of the MoE architecture.
The authors tested their pruning method on various language modeling tasks and found that it outperformed previous sparse MoE approaches in terms of both performance and computational efficiency. This means the pruned models can generate high-quality text more quickly and with less hardware resources, which could be valuable for real-world applications like chatbots, content generation, and language translation.
Technical Explanation
The core of the paper's contribution is an "efficient expert pruning" method for sparse Mixture-of-Experts (MoE) language models. MoE models [link to "Dense Training, Sparse Inference: Rethinking Training and Inference of Mixture-of-Experts Models"] consist of a gating network that selects a small subset of "experts" (specialized sub-networks) to process each input, rather than using all experts.
The authors propose a novel pruning technique that identifies and removes less important experts from the MoE model, resulting in a more compact and efficient architecture without significant accuracy degradation. Their approach involves:
- Ranking experts based on their contribution to the overall model performance, using a combination of signal importance and sparsity metrics.
- Iteratively pruning the lowest-ranked experts, fine-tuning the remaining model, and repeating the process.
The authors evaluate their pruning method on several language modeling benchmarks, including [link to "Not All Experts Are Equal: Efficient Expert Pruning for Sparse Mixture-of-Experts Models"] and [link to "Toward Inference-Optimal Mixture-of-Experts for Large Language Models"]. Their results demonstrate that the pruned MoE models outperform previous sparse MoE approaches in terms of both performance and computational efficiency, making them more practical for real-world applications.
Critical Analysis
The paper presents a compelling and well-executed approach to efficiently pruning experts in sparse MoE language models. The authors' proposed pruning technique is theoretically grounded and empirically validated, showing significant improvements over previous methods.
One potential limitation is the reliance on manual hyperparameter tuning for the pruning process, which may limit the scalability of the approach to larger models. The authors acknowledge this and suggest further research into automated hyperparameter optimization techniques.
Additionally, the paper does not explore the transferability of the pruned models to other downstream tasks beyond language modeling. It would be interesting to see how the pruned experts perform on tasks like question answering, text summarization, or dialogue generation.
Finally, the paper's focus is on improving computational efficiency, but it does not explicitly address the potential for the pruning process to introduce biases or fairness issues in the resulting models. This is an important consideration that could be explored in future work.
Conclusion
This paper presents a novel and effective method for pruning experts in sparse Mixture-of-Experts language models, leading to significant improvements in both performance and computational efficiency. By identifying and removing less important experts, the authors have created a more compact and practical MoE architecture that could have far-reaching applications in real-world language modeling tasks.
The insights and techniques developed in this research contribute to the ongoing efforts to make large language models more accessible and deployable, while maintaining their impressive capabilities. As the field of natural language processing continues to evolve, approaches like efficient expert pruning will be crucial for unlocking the full potential of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li
0
0
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
5/31/2024
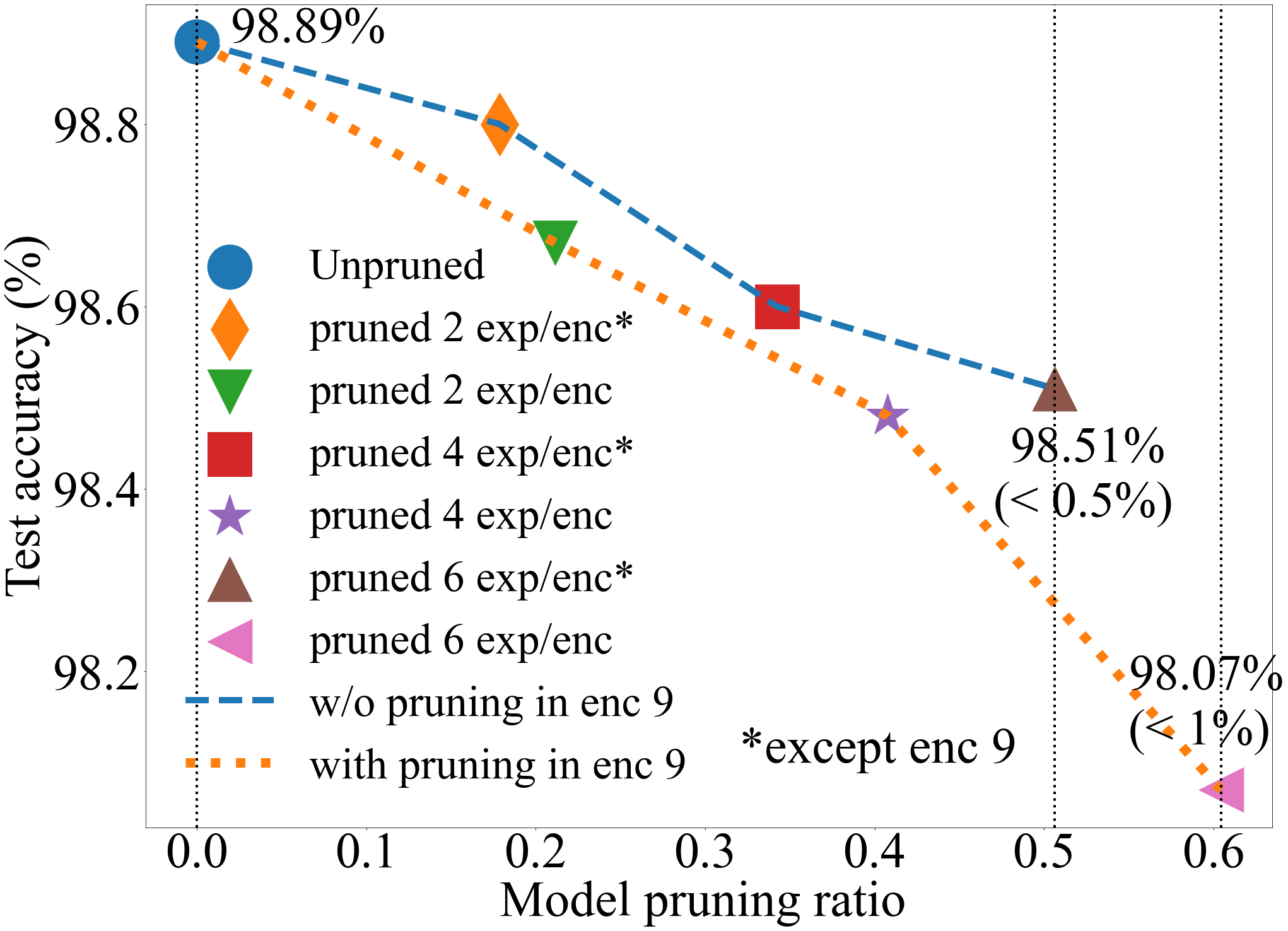
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
Mohammed Nowaz Rabbani Chowdhury, Meng Wang, Kaoutar El Maghraoui, Naigang Wang, Pin-Yu Chen, Christopher Carothers
0
0
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
5/31/2024
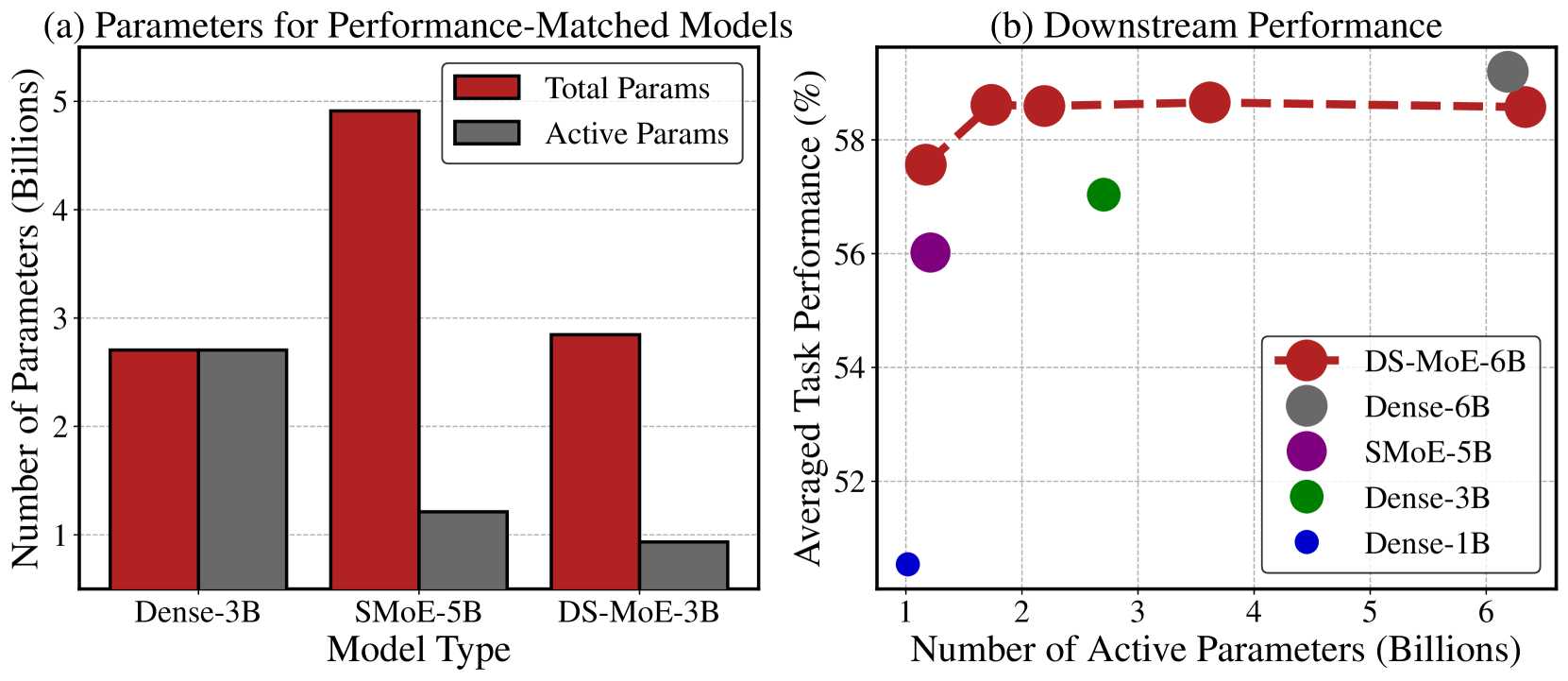
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
0
0
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
4/9/2024

SEER-MoE: Sparse Expert Efficiency through Regularization for Mixture-of-Experts
Alexandre Muzio, Alex Sun, Churan He
0
0
The advancement of deep learning has led to the emergence of Mixture-of-Experts (MoEs) models, known for their dynamic allocation of computational resources based on input. Despite their promise, MoEs face challenges, particularly in terms of memory requirements. To address this, our work introduces SEER-MoE, a novel two-stage framework for reducing both the memory footprint and compute requirements of pre-trained MoE models. The first stage involves pruning the total number of experts using a heavy-hitters counting guidance, while the second stage employs a regularization-based fine-tuning strategy to recover accuracy loss and reduce the number of activated experts during inference. Our empirical studies demonstrate the effectiveness of our method, resulting in a sparse MoEs model optimized for inference efficiency with minimal accuracy trade-offs.
4/9/2024