A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
2405.16646
0
0
Abstract
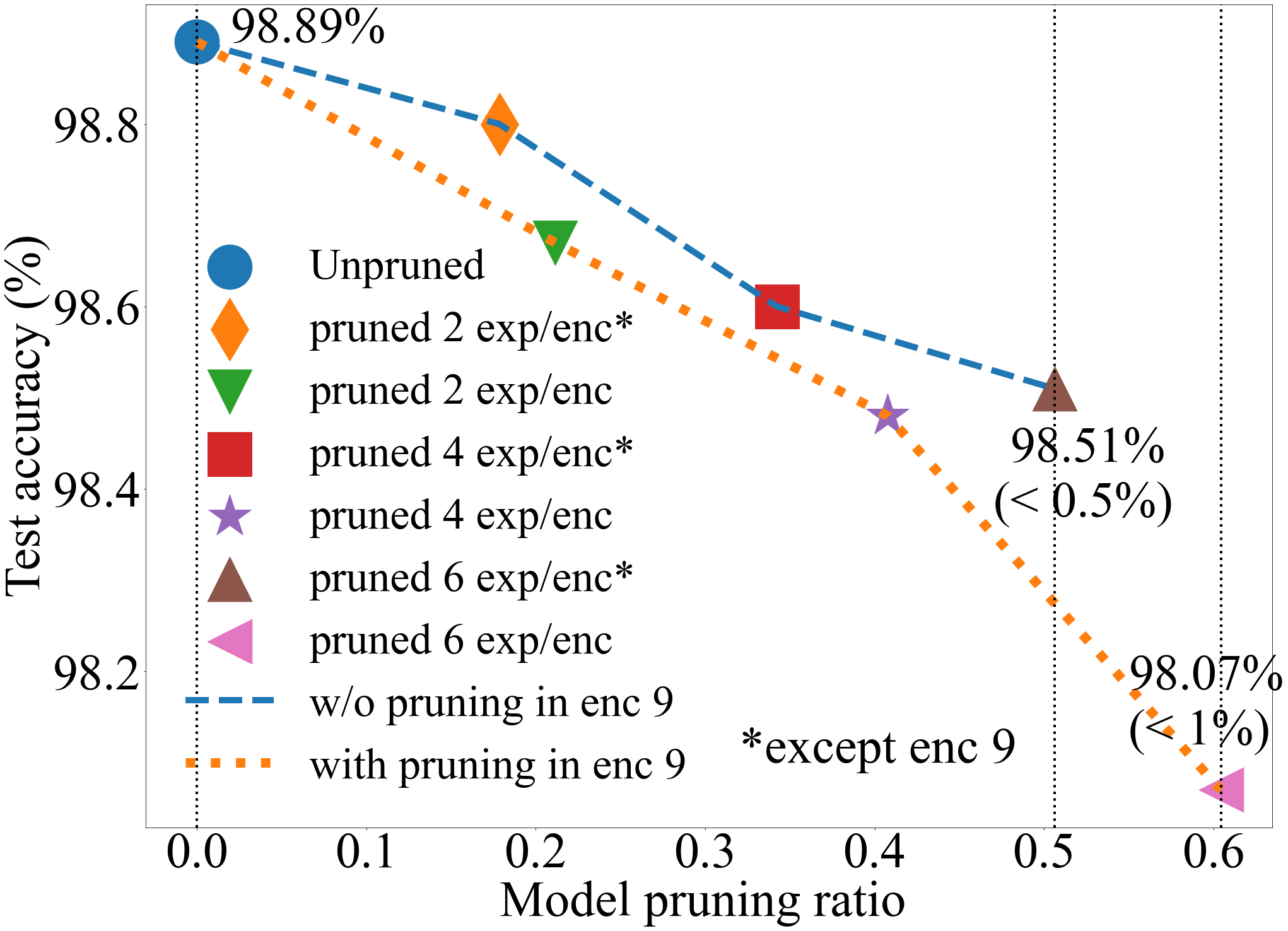
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
Create account to get full access
Overview
- Presents a novel pruning method for fine-tuned sparse Mixture-of-Experts (MoE) models
- Aims to improve the efficiency of MoE models by selectively removing less important expert modules
- Introduces a provably effective pruning algorithm with theoretical guarantees
Plain English Explanation
The paper describes a new technique to make Mixture-of-Experts (MoE) models more efficient. MoE models work by dividing a machine learning task into different "experts" and then combining their outputs. However, not all experts are equally important, so the researchers developed a way to automatically identify and remove the less useful ones.
This pruning method has several benefits. First, it can reduce the overall model size and computational cost, making the MoE model more efficient to run. Second, the pruning is "provably effective," meaning the researchers were able to mathematically prove that it will work as intended. This gives users more confidence that the pruned model will maintain its performance.
The key idea is to add a special type of regularization during the training process that encourages some experts to become less important. The algorithm can then safely remove these less important experts without significantly impacting the model's accuracy. This builds on prior work on sparse MoE models and adaptive expert assignment.
Technical Explanation
The paper proposes a novel pruning method for fine-tuned sparse Mixture-of-Experts (MoE) models. The core component is a regularization term added during training that encourages some experts to become less important. Specifically, the authors introduce a Sparse Entropy Regularization (SER) loss that minimizes the entropy of the gating network's outputs. This causes the gating network to more sharply select a smaller subset of experts for each input, enabling the subsequent pruning step.
The pruning algorithm then removes the least important experts based on the magnitudes of their weight matrices. The authors provide theoretical guarantees that this pruning procedure will not significantly degrade the model's performance. Intuitively, the regularization encourages the model to rely on a small number of experts, so removing the least important ones has minimal impact.
The pruning method is evaluated on several language modeling benchmarks, including GPT-2 and PrefixLM. The results show that the proposed approach can prune up to 50% of the experts while maintaining comparable or even improved performance compared to the unpruned baselines. This demonstrates the effectiveness of the method in improving the efficiency of fine-tuned sparse MoE models.
Critical Analysis
The paper makes a valuable contribution by providing a principled approach to pruning experts in MoE models. The theoretical guarantees and empirical results suggest that the proposed method is a reliable way to reduce model complexity without sacrificing performance.
However, a potential limitation is that the pruning is conducted after the initial fine-tuning process. In some cases, it may be more efficient to incorporate the pruning directly into the fine-tuning procedure, rather than treating them as separate steps. Additionally, the authors only evaluate their method on language modeling tasks, so further research is needed to assess its generalizability to other domains.
It would also be interesting to explore the potential trade-offs between the degree of pruning and other model properties, such as inference latency or energy efficiency. The authors mention this as a direction for future work, but do not delve into it in depth.
Overall, this paper presents a compelling approach to improving the efficiency of MoE models, which is an important and active area of research in machine learning. The techniques described could have significant practical implications for deploying large-scale AI models in resource-constrained environments.
Conclusion
This paper introduces a novel pruning method for fine-tuned sparse Mixture-of-Experts (MoE) models. The key contribution is a regularization-based approach that encourages the model to rely on a smaller subset of experts, allowing for the safe removal of less important experts without significantly impacting performance.
The proposed method comes with theoretical guarantees and is shown to be effective in improving the efficiency of MoE models on language modeling tasks. While the paper focuses on a specific application, the general principles and techniques could be applicable to a wider range of multi-expert or modular AI architectures.
Overall, this research represents an important step forward in making complex machine learning models more practical and deployable in real-world settings, which is a crucial challenge for the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li
0
0
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
5/31/2024

New!Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B. Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
0
0
The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.
7/2/2024

SEER-MoE: Sparse Expert Efficiency through Regularization for Mixture-of-Experts
Alexandre Muzio, Alex Sun, Churan He
0
0
The advancement of deep learning has led to the emergence of Mixture-of-Experts (MoEs) models, known for their dynamic allocation of computational resources based on input. Despite their promise, MoEs face challenges, particularly in terms of memory requirements. To address this, our work introduces SEER-MoE, a novel two-stage framework for reducing both the memory footprint and compute requirements of pre-trained MoE models. The first stage involves pruning the total number of experts using a heavy-hitters counting guidance, while the second stage employs a regularization-based fine-tuning strategy to recover accuracy loss and reduce the number of activated experts during inference. Our empirical studies demonstrate the effectiveness of our method, resulting in a sparse MoEs model optimized for inference efficiency with minimal accuracy trade-offs.
4/9/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024