Efficient Model-Stealing Attacks Against Inductive Graph Neural Networks

0
🧠
Sign in to get full access
Overview
- Graph Neural Networks (GNNs) are powerful tools for processing graph-structured data found in the real world.
- Inductive GNNs, which can process graphs without relying on predefined structures, are becoming increasingly important across many applications.
- As GNNs excel at various tasks, they are vulnerable to model-stealing attacks where adversaries try to replicate the target network's functionality.
- While significant work has focused on model-stealing attacks for image and text-based models, little attention has been given to GNNs trained on graph data.
Plain English Explanation
Graph-structured data, like social networks or transportation routes, is common in the real world. Graph Neural Networks (GNNs) are a type of machine learning model that can analyze and make predictions using this kind of data.
Inductive GNNs are a specific type of GNN that can process graph data without needing to know the exact structure of the graph ahead of time. This makes them very useful for a wide range of applications.
As GNNs become more capable, they also become more vulnerable to a type of attack called "model-stealing." In a model-stealing attack, someone tries to copy the inner workings of a GNN model by repeatedly querying it and analyzing the responses. This allows the attacker to create their own version of the model, which they can then use for their own purposes.
While model-stealing attacks have been well-studied for models that work with images and text, not much research has looked at attacking GNNs that work with graph data. This paper introduces a new method for stealing inductive GNN models by using techniques like graph contrasting learning and spectral graph augmentations.
Technical Explanation
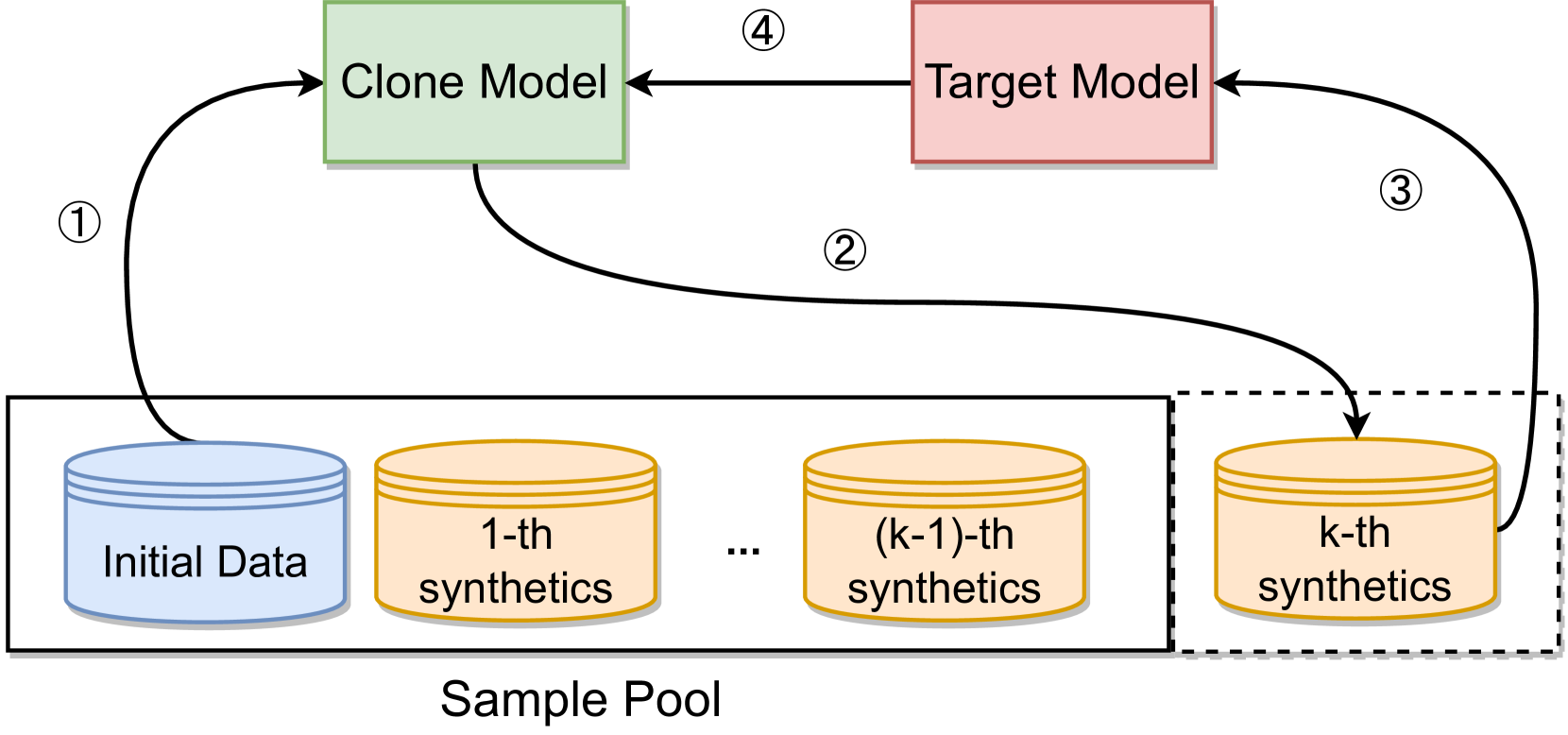
This paper proposes a novel unsupervised model-stealing attack against inductive Graph Neural Networks (GNNs). The attack leverages graph contrasting learning and spectral graph augmentations to efficiently extract information from the target GNN model.
The researchers thoroughly evaluated the proposed attack on six different datasets. The results show that this approach outperforms existing model-stealing attacks, achieving higher fidelity and downstream accuracy of the stolen model while requiring fewer queries sent to the target model.
The key technical innovations include:
-
Graph Contrasting Learning: The attacker trains a substitute model to learn representations that contrast with the target model's outputs, allowing the attacker to capture the target model's underlying knowledge.
-
Spectral Graph Augmentations: The attacker generates diverse graph samples by applying spectral transformations, which help the substitute model learn a more comprehensive understanding of the target model's behavior.
-
Query-Efficient Extraction: The proposed attack demonstrates higher efficiency compared to prior approaches, requiring fewer queries to the target model to achieve high-fidelity model extraction.
Critical Analysis
The paper makes a valuable contribution by introducing a novel model-stealing attack targeting inductive GNNs, an important class of machine learning models that have received less attention in the model-stealing literature compared to image and text-based models.
However, the authors acknowledge several limitations and avenues for future research:
-
Real-world Applicability: The evaluation is conducted on standard benchmark datasets, and the authors note that the attack's effectiveness may differ in more complex, real-world graph scenarios.
-
Defenses: The paper does not explore potential defenses against the proposed attack. Developing robust countermeasures is an important next step.
-
Ethical Considerations: As with any security research, there are potential misuse cases that should be carefully considered. The authors could have discussed the ethical implications of model-stealing attacks more extensively.
-
[object Object]: While this paper focuses on model-stealing, other types of attacks, such as structural adversarial attacks, pose additional threats to the security of GNNs that were not addressed.
Overall, the paper introduces a promising new model-stealing attack and highlights the need for further research into the security of inductive GNNs, including the development of robust defenses against unsupervised graph anomalies.
Conclusion
This paper presents a novel unsupervised model-stealing attack against inductive Graph Neural Networks (GNNs), a powerful class of machine learning models for processing graph-structured data. The proposed attack leverages graph contrasting learning and spectral graph augmentations to efficiently extract information from the target GNN model, outperforming existing model-stealing approaches.
The research underscores the growing importance of inductive GNNs and the need to address their vulnerability to model-stealing attacks, which could have significant implications as these models become more widely adopted across a range of applications. The findings highlight the need for further work on developing robust defenses to safeguard the security and integrity of GNN-based systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Efficient Model-Stealing Attacks Against Inductive Graph Neural Networks
Marcin Podhajski, Jan Dubi'nski, Franziska Boenisch, Adam Dziedzic, Agnieszka Pregowska And Tomasz Michalak
Graph Neural Networks (GNNs) are recognized as potent tools for processing real-world data organized in graph structures. Especially inductive GNNs, which allow for the processing of graph-structured data without relying on predefined graph structures, are becoming increasingly important in a wide range of applications. As such these networks become attractive targets for model-stealing attacks where an adversary seeks to replicate the functionality of the targeted network. Significant efforts have been devoted to developing model-stealing attacks that extract models trained on images and texts. However, little attention has been given to stealing GNNs trained on graph data. This paper identifies a new method of performing unsupervised model-stealing attacks against inductive GNNs, utilizing graph contrastive learning and spectral graph augmentations to efficiently extract information from the targeted model. The new type of attack is thoroughly evaluated on six datasets and the results show that our approach outperforms the current state-of-the-art by Shen et al. (2021). In particular, our attack surpasses the baseline across all benchmarks, attaining superior fidelity and downstream accuracy of the stolen model while necessitating fewer queries directed toward the target model.
Read more8/27/2024

0
Link Stealing Attacks Against Inductive Graph Neural Networks
Yixin Wu, Xinlei He, Pascal Berrang, Mathias Humbert, Michael Backes, Neil Zhenqiang Gong, Yang Zhang
A graph neural network (GNN) is a type of neural network that is specifically designed to process graph-structured data. Typically, GNNs can be implemented in two settings, including the transductive setting and the inductive setting. In the transductive setting, the trained model can only predict the labels of nodes that were observed at the training time. In the inductive setting, the trained model can be generalized to new nodes/graphs. Due to its flexibility, the inductive setting is the most popular GNN setting at the moment. Previous work has shown that transductive GNNs are vulnerable to a series of privacy attacks. However, a comprehensive privacy analysis of inductive GNN models is still missing. This paper fills the gap by conducting a systematic privacy analysis of inductive GNNs through the lens of link stealing attacks, one of the most popular attacks that are specifically designed for GNNs. We propose two types of link stealing attacks, i.e., posterior-only attacks and combined attacks. We define threat models of the posterior-only attacks with respect to node topology and the combined attacks by considering combinations of posteriors, node attributes, and graph features. Extensive evaluation on six real-world datasets demonstrates that inductive GNNs leak rich information that enables link stealing attacks with advantageous properties. Even attacks with no knowledge about graph structures can be effective. We also show that our attacks are robust to different node similarities and different graph features. As a counterpart, we investigate two possible defenses and discover they are ineffective against our attacks, which calls for more effective defenses.
Read more5/10/2024
0
Model Stealing Attack against Graph Classification with Authenticity, Uncertainty and Diversity
Zhihao Zhu, Chenwang Wu, Rui Fan, Yi Yang, Zhen Wang, Defu Lian, Enhong Chen
Recent research demonstrates that GNNs are vulnerable to the model stealing attack, a nefarious endeavor geared towards duplicating the target model via query permissions. However, they mainly focus on node classification tasks, neglecting the potential threats entailed within the domain of graph classification tasks. Furthermore, their practicality is questionable due to unreasonable assumptions, specifically concerning the large data requirements and extensive model knowledge. To this end, we advocate following strict settings with limited real data and hard-label awareness to generate synthetic data, thereby facilitating the stealing of the target model. Specifically, following important data generation principles, we introduce three model stealing attacks to adapt to different actual scenarios: MSA-AU is inspired by active learning and emphasizes the uncertainty to enhance query value of generated samples; MSA-AD introduces diversity based on Mixup augmentation strategy to alleviate the query inefficiency issue caused by over-similar samples generated by MSA-AU; MSA-AUD combines the above two strategies to seamlessly integrate the authenticity, uncertainty, and diversity of the generated samples. Finally, extensive experiments consistently demonstrate the superiority of the proposed methods in terms of concealment, query efficiency, and stealing performance.
Read more8/21/2024

0
Problem space structural adversarial attacks for Network Intrusion Detection Systems based on Graph Neural Networks
Andrea Venturi, Dario Stabili, Mirco Marchetti
Machine Learning (ML) algorithms have become increasingly popular for supporting Network Intrusion Detection Systems (NIDS). Nevertheless, extensive research has shown their vulnerability to adversarial attacks, which involve subtle perturbations to the inputs of the models aimed at compromising their performance. Recent proposals have effectively leveraged Graph Neural Networks (GNN) to produce predictions based also on the structural patterns exhibited by intrusions to enhance the detection robustness. However, the adoption of GNN-based NIDS introduces new types of risks. In this paper, we propose the first formalization of adversarial attacks specifically tailored for GNN in network intrusion detection. Moreover, we outline and model the problem space constraints that attackers need to consider to carry out feasible structural attacks in real-world scenarios. As a final contribution, we conduct an extensive experimental campaign in which we launch the proposed attacks against state-of-the-art GNN-based NIDS. Our findings demonstrate the increased robustness of the models against classical feature-based adversarial attacks, while highlighting their susceptibility to structure-based attacks.
Read more4/24/2024