Model Stealing Attack against Graph Classification with Authenticity, Uncertainty and Diversity

0
Sign in to get full access
Overview
- This paper presents a model stealing attack against graph classification models, which aims to steal the target model's functionality.
- The attack focuses on achieving authenticity, uncertainty, and diversity in the stolen model, to make it difficult to detect as a copy.
- The authors evaluate their attack on real-world graph classification tasks and show it can effectively steal the target model's performance.
Plain English Explanation
Model Stealing Attacks
Model stealing attacks are a type of security vulnerability where someone tries to copy the functionality of a machine learning model without permission. This could allow them to use the model for their own purposes, even if they don't have access to the original training data or model parameters.
Graph Classification Models
Graph classification models are a type of machine learning model that can categorize data represented as graphs, rather than simple vectors or images. Graphs can capture more complex relationships between data points, making them useful for tasks like social network analysis or chemical compound prediction.
Authenticity, Uncertainty, and Diversity
In this paper, the researchers develop a model stealing attack that focuses on three key properties:
- Authenticity: The stolen model should closely match the behavior of the original target model, so it's difficult to detect as a copy.
- Uncertainty: The stolen model should express appropriate levels of confidence in its predictions, rather than being overconfident.
- Diversity: The stolen model should generate a diverse set of possible outputs, not just mimicking the most common outputs of the target model.
By achieving these properties, the researchers aim to create a stolen model that is hard to distinguish from the original.
Technical Explanation
Target Model
The target model in this paper is a Graph Neural Network (GNN), a type of deep learning model designed to operate on graph-structured data. GNNs work by iteratively updating node representations based on their local neighborhood, allowing them to capture complex relationships in the data.
Attack Approach
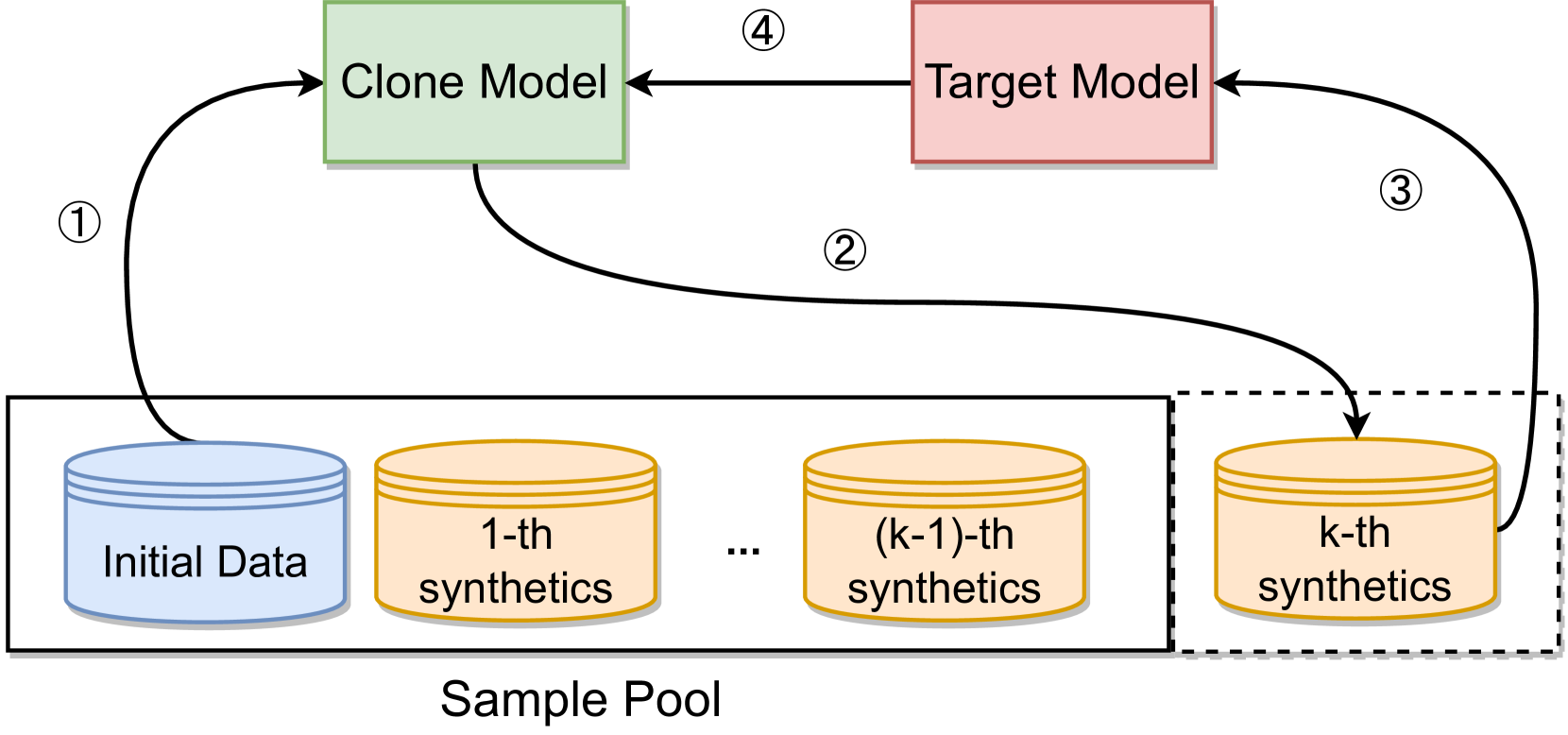
The researchers develop a model stealing attack that works in two stages:
- Surrogate Model Training: They first train a "surrogate" model to approximate the behavior of the target GNN model, using a small number of input-output pairs obtained from the target model.
- Uncertainty-Aware Optimization: They then fine-tune the surrogate model using an optimization process that encourages the stolen model to have the desired properties of authenticity, uncertainty, and diversity.
The key innovation is the use of uncertainty-aware loss functions and diversity-promoting regularization to shape the behavior of the stolen model.
Experiments
The researchers evaluate their attack on real-world graph classification tasks, including predicting molecular properties and classifying social networks. They show that the stolen models can match the performance of the original target models, while exhibiting the desired properties of authenticity, uncertainty, and diversity.
Critical Analysis
The paper provides a strong technical contribution, demonstrating an effective model stealing attack against graph classification models. However, it's important to note that model stealing attacks can raise significant ethical and security concerns, as they can enable the unauthorized use of valuable intellectual property.
While the researchers mention some potential defenses, such as model watermarking, further research is needed to develop robust countermeasures against these types of attacks. Additionally, the long-term implications of model stealing on the machine learning ecosystem deserve careful consideration.
Conclusion
This paper presents an advanced model stealing attack that can effectively copy the functionality of graph classification models, while preserving key properties like authenticity, uncertainty, and diversity. The technical insights could be valuable for both model developers and security researchers, but the broader implications of model stealing attacks warrant further discussion and investigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Model Stealing Attack against Graph Classification with Authenticity, Uncertainty and Diversity
Zhihao Zhu, Chenwang Wu, Rui Fan, Yi Yang, Zhen Wang, Defu Lian, Enhong Chen
Recent research demonstrates that GNNs are vulnerable to the model stealing attack, a nefarious endeavor geared towards duplicating the target model via query permissions. However, they mainly focus on node classification tasks, neglecting the potential threats entailed within the domain of graph classification tasks. Furthermore, their practicality is questionable due to unreasonable assumptions, specifically concerning the large data requirements and extensive model knowledge. To this end, we advocate following strict settings with limited real data and hard-label awareness to generate synthetic data, thereby facilitating the stealing of the target model. Specifically, following important data generation principles, we introduce three model stealing attacks to adapt to different actual scenarios: MSA-AU is inspired by active learning and emphasizes the uncertainty to enhance query value of generated samples; MSA-AD introduces diversity based on Mixup augmentation strategy to alleviate the query inefficiency issue caused by over-similar samples generated by MSA-AU; MSA-AUD combines the above two strategies to seamlessly integrate the authenticity, uncertainty, and diversity of the generated samples. Finally, extensive experiments consistently demonstrate the superiority of the proposed methods in terms of concealment, query efficiency, and stealing performance.
Read more8/21/2024
🧠
0
Efficient Model-Stealing Attacks Against Inductive Graph Neural Networks
Marcin Podhajski, Jan Dubi'nski, Franziska Boenisch, Adam Dziedzic, Agnieszka Pregowska And Tomasz Michalak
Graph Neural Networks (GNNs) are recognized as potent tools for processing real-world data organized in graph structures. Especially inductive GNNs, which allow for the processing of graph-structured data without relying on predefined graph structures, are becoming increasingly important in a wide range of applications. As such these networks become attractive targets for model-stealing attacks where an adversary seeks to replicate the functionality of the targeted network. Significant efforts have been devoted to developing model-stealing attacks that extract models trained on images and texts. However, little attention has been given to stealing GNNs trained on graph data. This paper identifies a new method of performing unsupervised model-stealing attacks against inductive GNNs, utilizing graph contrastive learning and spectral graph augmentations to efficiently extract information from the targeted model. The new type of attack is thoroughly evaluated on six datasets and the results show that our approach outperforms the current state-of-the-art by Shen et al. (2021). In particular, our attack surpasses the baseline across all benchmarks, attaining superior fidelity and downstream accuracy of the stolen model while necessitating fewer queries directed toward the target model.
Read more8/27/2024
0
Beyond Labeling Oracles: What does it mean to steal ML models?
Avital Shafran, Ilia Shumailov, Murat A. Erdogdu, Nicolas Papernot
Model extraction attacks are designed to steal trained models with only query access, as is often provided through APIs that ML-as-a-Service providers offer. Machine Learning (ML) models are expensive to train, in part because data is hard to obtain, and a primary incentive for model extraction is to acquire a model while incurring less cost than training from scratch. Literature on model extraction commonly claims or presumes that the attacker is able to save on both data acquisition and labeling costs. We thoroughly evaluate this assumption and find that the attacker often does not. This is because current attacks implicitly rely on the adversary being able to sample from the victim model's data distribution. We thoroughly research factors influencing the success of model extraction. We discover that prior knowledge of the attacker, i.e., access to in-distribution data, dominates other factors like the attack policy the adversary follows to choose which queries to make to the victim model API. Our findings urge the community to redefine the adversarial goals of ME attacks as current evaluation methods misinterpret the ME performance.
Read more6/14/2024

0
Stealing Image-to-Image Translation Models With a Single Query
Nurit Spingarn-Eliezer, Tomer Michaeli
Training deep neural networks requires significant computational resources and large datasets that are often confidential or expensive to collect. As a result, owners tend to protect their models by allowing access only via an API. Many works demonstrated the possibility of stealing such protected models by repeatedly querying the API. However, to date, research has predominantly focused on stealing classification models, for which a very large number of queries has been found necessary. In this paper, we study the possibility of stealing image-to-image models. Surprisingly, we find that many such models can be stolen with as little as a single, small-sized, query image using simple distillation. We study this phenomenon on a wide variety of model architectures, datasets, and tasks, including denoising, deblurring, deraining, super-resolution, and biological image-to-image translation. Remarkably, we find that the vulnerability to stealing attacks is shared by CNNs and by models with attention mechanisms, and that stealing is commonly possible even without knowing the architecture of the target model.
Read more6/4/2024