Efficient Prompt Optimization Through the Lens of Best Arm Identification

0

Sign in to get full access
Overview
- This paper explores the problem of identifying the best "prompts" to use with large language models (LLMs) when the available budget for evaluating prompts is limited.
- Prompts are short input phrases that are used to guide LLMs to produce desired outputs. Choosing the right prompts is crucial for effective use of LLMs.
- The researchers frame this as a "best arm identification" problem, where the goal is to efficiently identify the most effective prompt from a set of candidates, given a limited budget for evaluating them.
- They propose an algorithm called "BAIT" (Best Arm Identification for Prompt learning under a limited budgeT) to solve this problem.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text on a wide range of topics. However, getting these models to produce the specific outputs you want can be challenging. This is where "prompts" come in.
Prompts are short phrases or sentences that you provide to the LLM to guide its text generation. The choice of prompt can have a big impact on the quality and relevance of the model's output. [Imagine you're trying to get a language model to write a product description - the prompt you give it will determine whether it focuses on the features, the benefits, the use cases, etc.]
The problem is that there are often many possible prompts to choose from, and it can be time-consuming and expensive to evaluate them all. This paper presents a new algorithm called "BAIT" that helps you efficiently identify the best prompt to use, even when you have a limited budget for trying out different prompts.
The key idea behind BAIT is to treat the problem of finding the best prompt like a "best arm identification" problem in the field of multi-armed bandits. This allows the algorithm to intelligently explore the space of possible prompts and quickly zero in on the most effective one, without having to exhaustively evaluate every option.
[The paper cites several related works on prompt optimization and selection, which you can check out for more context on this problem: [link1], [link2], [link3], [link4], [link5].]
Technical Explanation
The researchers frame the prompt learning problem as a "best arm identification" task in the multi-armed bandit setting. Each "arm" corresponds to a different prompt, and the "rewards" are the performance scores obtained when using that prompt with the language model.
The goal is to identify the "best arm" (the most effective prompt) using as few samples/evaluations as possible, given a limited budget. The researchers propose the BAIT algorithm to solve this problem.
BAIT works by maintaining an estimate of the performance of each prompt, along with a measure of the uncertainty around that estimate. It then selects prompts to evaluate based on a combination of their estimated performance and uncertainty, in order to quickly zero in on the best prompt.
The key components of BAIT include:
- An initialization phase to get rough estimates of prompt performance
- A sampling strategy that balances exploration (trying new prompts) and exploitation (focusing on promising prompts)
- A stopping rule that determines when to stop evaluating prompts and return the estimated best one
The researchers evaluate BAIT on both synthetic and real-world language modeling tasks, and show that it can efficiently identify the best prompt while using significantly fewer prompt evaluations compared to baseline approaches.
Critical Analysis
The paper makes a compelling case for the importance of efficient prompt selection, and the BAIT algorithm seems to be a promising solution. However, a few potential limitations or areas for further research are worth noting:
- The experiments are relatively limited in scale, focusing on a few synthetic and real-world language modeling tasks. It would be interesting to see how BAIT performs on a wider range of prompt-dependent LLM applications.
- The paper does not deeply explore the connections between prompt performance and the underlying properties of the language model and task. Understanding these relationships could lead to even more efficient prompt selection strategies.
- While BAIT aims to be sample-efficient, the actual costs of prompt evaluation (e.g., computational resources, time) are not considered. Incorporating these factors could make the algorithm even more practical.
- The algorithm assumes that prompt performance is independent across tasks/models. Relaxing this assumption and handling potential transfer or relatedness between prompts could further improve efficiency.
Overall, this paper provides a solid foundation for efficient prompt selection, and the BAIT algorithm seems like a useful tool for researchers and practitioners working on prompt-based LLM applications. Continued exploration of this problem space could yield valuable insights and advancements.
Conclusion
This paper tackles the important problem of efficiently identifying the best prompts to use with large language models, when the budget for evaluating prompts is limited. By framing the problem as a "best arm identification" task, the researchers develop the BAIT algorithm, which can quickly zero in on the most effective prompt while minimizing the number of prompt evaluations required.
The results demonstrate the practical value of BAIT, and the paper provides a solid foundation for further research into prompt optimization and selection. Continued work in this area could lead to significant improvements in the effective use of large language models, with applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Prompt Optimization Through the Lens of Best Arm Identification
Chengshuai Shi, Kun Yang, Zihan Chen, Jundong Li, Jing Yang, Cong Shen
The remarkable instruction-following capability of large language models (LLMs) has sparked a growing interest in automatically finding good prompts, i.e., prompt optimization. Most existing works follow the scheme of selecting from a pre-generated pool of candidate prompts. However, these designs mainly focus on the generation strategy, while limited attention has been paid to the selection method. Especially, the cost incurred during the selection (e.g., accessing LLM and evaluating the responses) is rarely explicitly considered. To overcome this limitation, this work provides a principled framework, TRIPLE, to efficiently perform prompt selection under an explicit budget constraint. TRIPLE is built on a novel connection established between prompt optimization and fixed-budget best arm identification (BAI-FB) in multi-armed bandits (MAB); thus, it is capable of leveraging the rich toolbox from BAI-FB systematically and also incorporating unique characteristics of prompt optimization. Extensive experiments on multiple well-adopted tasks using various LLMs demonstrate the remarkable performance improvement of TRIPLE over baselines while satisfying the limited budget constraints. As an extension, variants of TRIPLE are proposed to efficiently select examples for few-shot prompts, also achieving superior empirical performance.
Read more6/3/2024

0
On Speeding Up Language Model Evaluation
Jin Peng Zhou, Christian K. Belardi, Ruihan Wu, Travis Zhang, Carla P. Gomes, Wen Sun, Kilian Q. Weinberger
Developing prompt-based methods with Large Language Models (LLMs) requires making numerous decisions, which give rise to a combinatorial search problem. For example, selecting the right pre-trained LLM, prompt, and hyperparameters to attain the best performance for a task typically necessitates evaluating an expoential number of candidates on large validation sets. This exhaustive evaluation can be time-consuming and costly, as both inference and evaluation of LLM-based approaches are resource-intensive. Worse, a lot of computation is wasted: Many hyper-parameter settings are non-competitive, and many samples from the validation set are highly correlated - providing little or no new information. So, if the goal is to identify the best method, it can be done far more efficiently if the validation samples and methods are selected adaptively. In this paper, we propose a novel method to address this challenge. We lean on low-rank matrix factorization to fill in missing evaluations and on multi-armed bandits to sequentially identify the next (method, validation sample)-pair to evaluate. We carefully assess the efficacy of our approach on several competitive benchmark problems and show that it can identify the top-performing method using only 5-15% of the typically needed resources -- resulting in a staggering 85-95% LLM cost savings.
Read more8/16/2024
0
Language Model Prompt Selection via Simulation Optimization
Haoting Zhang, Jinghai He, Rhonda Righter, Zeyu Zheng
With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
Read more5/21/2024
0
Automatic Prompt Selection for Large Language Models
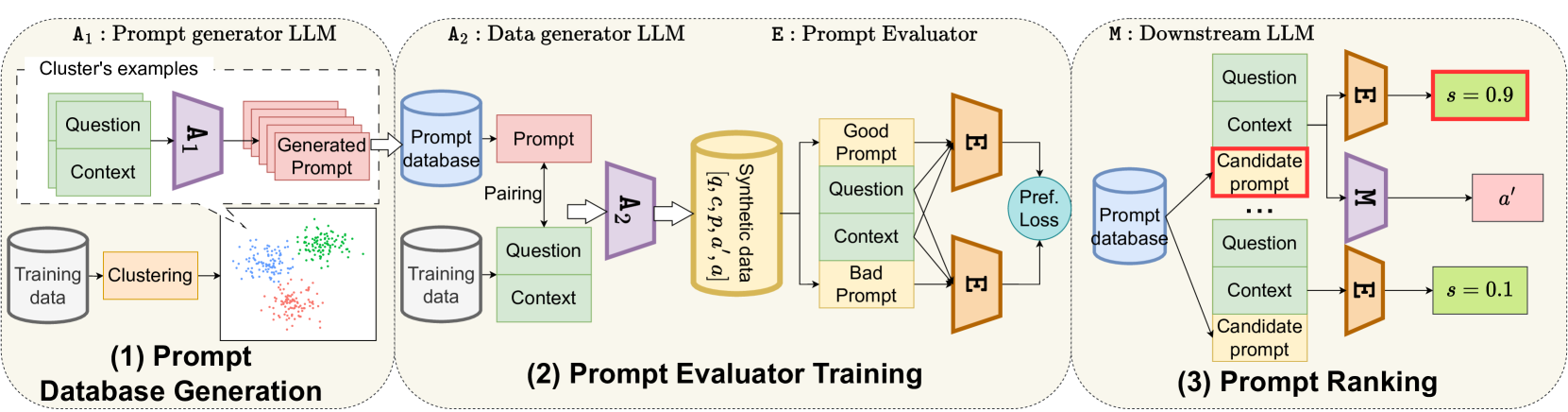
Viet-Tung Do, Van-Khanh Hoang, Duy-Hung Nguyen, Shahab Sabahi, Jeff Yang, Hajime Hotta, Minh-Tien Nguyen, Hung Le
Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
Read more4/4/2024