On Speeding Up Language Model Evaluation

0

Sign in to get full access
Overview
- This paper presents a method for speeding up the evaluation of large language models (LLMs) by reducing the number of examples required.
- The researchers propose a novel approach called "Masked Language Modeling (MLM) Ranking" that can rank LLMs without ground truth labels.
- The paper also discusses leveraging LLMs for more efficient natural language generation (NLG) evaluation and explores the use of prompts to optimize LLM performance.
Plain English Explanation
The paper focuses on making the process of evaluating large language models (LLMs) more efficient. Evaluating LLMs, which are AI systems that can understand and generate human-like text, typically requires running them on a large number of examples to measure their performance. However, this can be a time-consuming and resource-intensive process.
To address this, the researchers developed a new approach called "Masked Language Modeling (MLM) Ranking." This method allows for ranking LLMs without needing ground truth labels, which are the correct answers that the model should produce. Instead, the MLM Ranking approach uses the model's own predictions to assess its performance, making the evaluation process faster and more efficient.
The paper also explores ways to leverage LLMs to improve the evaluation of natural language generation (NLG) tasks, where AI systems generate human-like text. The researchers discuss how LLMs can be used to streamline the evaluation process and provide more insightful feedback.
Additionally, the paper examines the use of prompts, which are the input texts used to guide LLMs in generating their outputs. The researchers investigate techniques for optimizing prompts to help LLMs perform better, further enhancing the efficiency of the evaluation process.
Technical Explanation
The paper starts by discussing the challenges of evaluating large language models (LLMs), which are AI systems that can understand and generate human-like text. Evaluating LLMs typically requires running them on a large number of examples, which can be time-consuming and resource-intensive.
To address this, the researchers propose a novel approach called "Masked Language Modeling (MLM) Ranking." This method allows for ranking LLMs without needing ground truth labels, which are the correct answers that the model should produce. Instead, the MLM Ranking approach uses the model's own predictions to assess its performance, making the evaluation process faster and more efficient.
The paper also explores ways to leverage LLMs to improve the evaluation of natural language generation (NLG) tasks, where AI systems generate human-like text. The researchers discuss how LLMs can be used to streamline the evaluation process and provide more insightful feedback, as described in the Leveraging Large Language Models for NLG Evaluation Advances paper.
Additionally, the paper examines the use of prompts, which are the input texts used to guide LLMs in generating their outputs. The researchers investigate techniques for optimizing prompts to help LLMs perform better, as discussed in the Efficient Prompt Optimization Through the Lens of Best Arm paper.
Critical Analysis
The paper presents a promising approach for speeding up the evaluation of large language models (LLMs) by reducing the number of examples required. The Masked Language Modeling (MLM) Ranking method is a novel and potentially valuable contribution, as it allows for ranking LLMs without ground truth labels.
However, the paper does not provide a comprehensive evaluation of the MLM Ranking approach, and it would be helpful to see how it performs compared to other existing methods for LLM evaluation, such as those discussed in the Ranking Large Language Models Without Ground Truth and TinyBenchmarks: Evaluating Large Language Models on Fewer Examples papers.
Additionally, the paper could benefit from a more in-depth discussion of the limitations and potential drawbacks of the MLM Ranking approach. For example, it would be useful to understand how the method performs on different types of LLMs or tasks, and whether there are any biases or pitfalls that researchers should be aware of when using this approach.
Conclusion
Overall, the paper presents a promising method for speeding up the evaluation of large language models (LLMs) by reducing the number of examples required. The Masked Language Modeling (MLM) Ranking approach offers a novel way to rank LLMs without ground truth labels, potentially making the evaluation process more efficient.
The paper also explores ways to leverage LLMs for more effective natural language generation (NLG) evaluation and investigates techniques for optimizing prompts to enhance LLM performance. While the research shows promise, further evaluation and discussion of the limitations and potential drawbacks of the proposed methods would be valuable for advancing this important area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On Speeding Up Language Model Evaluation
Jin Peng Zhou, Christian K. Belardi, Ruihan Wu, Travis Zhang, Carla P. Gomes, Wen Sun, Kilian Q. Weinberger
Developing prompt-based methods with Large Language Models (LLMs) requires making numerous decisions, which give rise to a combinatorial search problem. For example, selecting the right pre-trained LLM, prompt, and hyperparameters to attain the best performance for a task typically necessitates evaluating an expoential number of candidates on large validation sets. This exhaustive evaluation can be time-consuming and costly, as both inference and evaluation of LLM-based approaches are resource-intensive. Worse, a lot of computation is wasted: Many hyper-parameter settings are non-competitive, and many samples from the validation set are highly correlated - providing little or no new information. So, if the goal is to identify the best method, it can be done far more efficiently if the validation samples and methods are selected adaptively. In this paper, we propose a novel method to address this challenge. We lean on low-rank matrix factorization to fill in missing evaluations and on multi-armed bandits to sequentially identify the next (method, validation sample)-pair to evaluate. We carefully assess the efficacy of our approach on several competitive benchmark problems and show that it can identify the top-performing method using only 5-15% of the typically needed resources -- resulting in a staggering 85-95% LLM cost savings.
Read more8/16/2024

0
Achieving Peak Performance for Large Language Models: A Systematic Review
Zhyar Rzgar K Rostam, S'andor Sz'en'asi, G'abor Kert'esz
In recent years, large language models (LLMs) have achieved remarkable success in natural language processing (NLP). LLMs require an extreme amount of parameters to attain high performance. As models grow into the trillion-parameter range, computational and memory costs increase significantly. This makes it difficult for many researchers to access the resources needed to train or apply these models. Optimizing LLM performance involves two main approaches: fine-tuning pre-trained models for specific tasks to achieve state-of-the-art performance, and reducing costs or improving training time while maintaining similar performance. This paper presents a systematic literature review (SLR) following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement. We reviewed 65 publications out of 983 from 2017 to December 2023, retrieved from 5 databases. The study presents methods to optimize and accelerate LLMs while achieving cutting-edge results without sacrificing accuracy. We begin with an overview of the development of language modeling, followed by a detailed explanation of commonly used frameworks and libraries, and a taxonomy for improving and speeding up LLMs based on three classes: LLM training, LLM inference, and system serving. We then delve into recent optimization and acceleration strategies such as training optimization, hardware optimization, scalability and reliability, accompanied by the taxonomy and categorization of these strategies. Finally, we provide an in-depth comparison of each class and strategy, with two case studies on optimizing model training and enhancing inference efficiency. These case studies showcase practical approaches to address LLM resource limitations while maintaining performance.
Read more9/10/2024
0
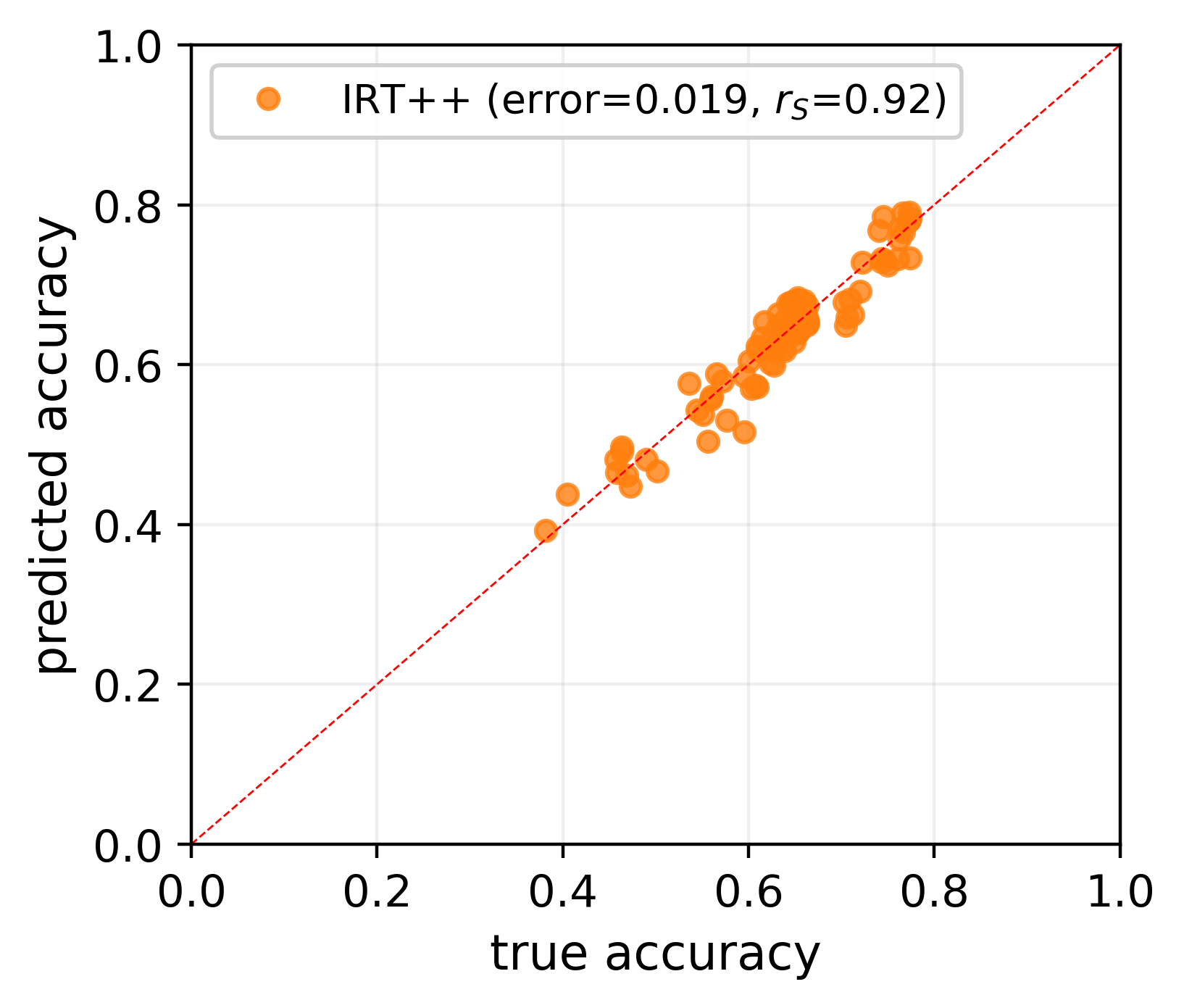
tinyBenchmarks: evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, Mikhail Yurochkin
The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
Read more5/28/2024
0
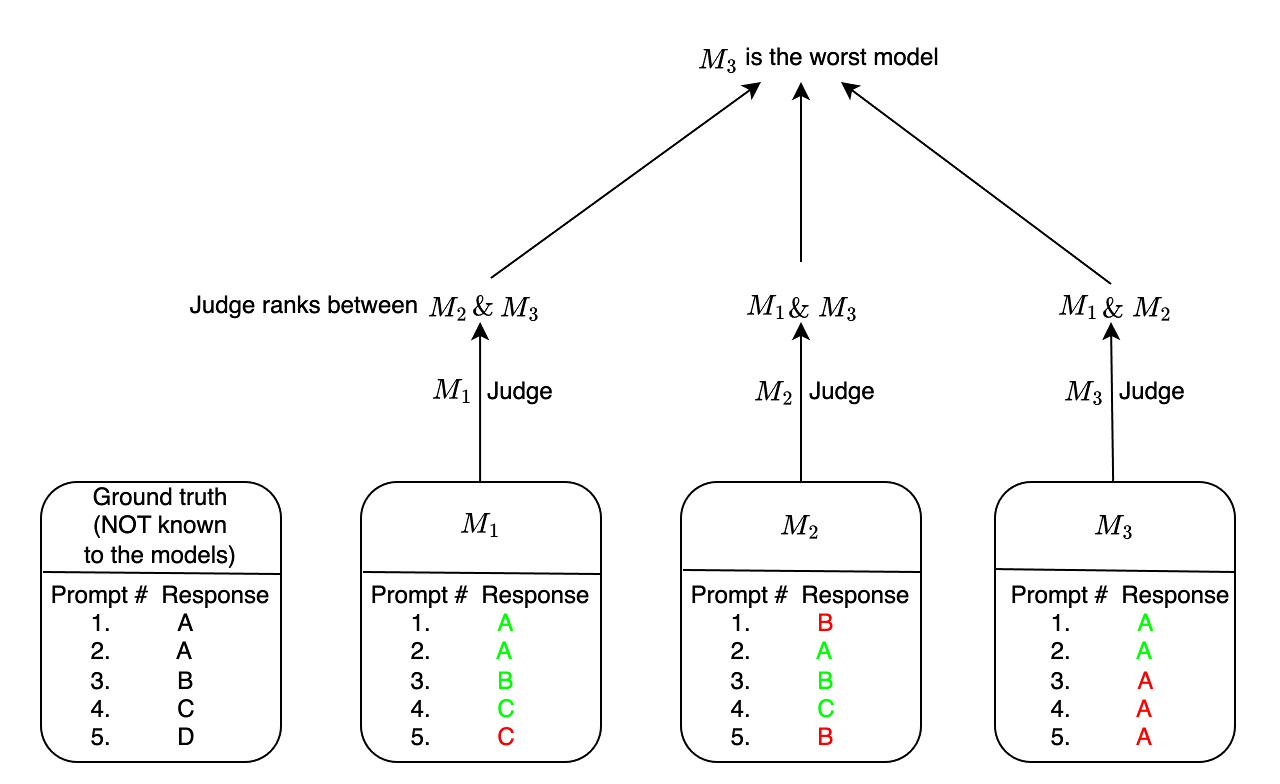
Ranking Large Language Models without Ground Truth
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, Karthikeyan Natesan Ramamurthy
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
Read more6/11/2024