An Efficient Real-Time Object Detection Framework on Resource-Constricted Hardware Devices via Software and Hardware Co-design

0

Sign in to get full access
Overview
- Presents an adaptive tensor-train (TT) decomposition approach for efficient deep neural network compression
- Focuses on convolutional neural networks (CNNs) used for image classification tasks
- Adaptively selects the TT-ranks during training to balance compression ratio and accuracy
Plain English Explanation
The paper introduces a new way to compress deep neural networks, which are complex mathematical models used for tasks like image classification. The key idea is to use a technique called tensor-train decomposition to break down the large matrices inside the network into smaller, more manageable pieces.
Traditionally, compressing neural networks can be tricky because reducing the model size too much can hurt the accuracy. This new approach adaptively adjusts the size of those smaller pieces during training, finding the right balance between how much the model is compressed and how well it performs on the task.
The researchers tested this method on common image classification convolutional neural networks and showed they could achieve significant compression (up to 25x) with only a small drop in accuracy. This makes the models more efficient and easier to deploy on devices with limited computing power, like smartphones.
Technical Explanation
The paper proposes an adaptive tensor-train (TT) decomposition approach for compressing deep convolutional neural networks (CNNs). TT decomposition is a tensor factorization technique that can efficiently represent high-dimensional tensors (the multi-dimensional arrays that make up neural network weights) using a series of smaller, low-dimensional tensors.
The key innovation is an adaptive rank selection mechanism that adjusts the TT-ranks (the dimensions of these smaller tensors) during training. This allows the compression ratio to be balanced with the model's performance on the target task (e.g., image classification). The authors develop a principled optimization framework to jointly optimize the network weights and the TT-ranks.
Experiments on several popular CNN architectures, including VGG, ResNet, and MobileNet, demonstrate that the proposed approach can achieve up to 25x model compression with only a small drop in classification accuracy on benchmark datasets like ImageNet. The adaptive nature of the TT-rank selection is shown to be crucial, outperforming static rank selection strategies.
Critical Analysis
The paper presents a well-designed and technically sound approach for compressing deep neural networks using tensor decomposition. The adaptive rank selection is a clever solution to the challenge of balancing compression and accuracy, which is a common issue in model compression techniques.
However, the paper does not address some potential limitations or areas for further research. For example, it's unclear how the approach would scale to larger, more complex neural network architectures beyond the tested models. The compression ratios and accuracy trade-offs may not be as favorable for deeper or more sophisticated networks.
Additionally, the paper focuses solely on image classification tasks, but the applicability of the method to other domains, such as natural language processing or reinforcement learning, is not explored. Investigating the performance of the adaptive TT decomposition on a wider range of neural network applications would be valuable.
Finally, the paper does not provide much insight into the computational overhead or runtime implications of the proposed method. In practice, the additional optimization complexity introduced by the adaptive rank selection may offset some of the benefits of the reduced model size, especially for real-time or latency-sensitive applications.
Conclusion
This paper presents a novel approach for efficiently compressing deep convolutional neural networks using an adaptive tensor-train decomposition. By dynamically adjusting the TT-ranks during training, the method can achieve significant model compression (up to 25x) with only minor accuracy degradation on standard image classification benchmarks.
The adaptive nature of the rank selection is a key strength of the approach, as it allows for a flexible trade-off between compression ratio and model performance. This makes the compressed models more suitable for deployment on resource-constrained devices, such as mobile phones or embedded systems, where both model size and accuracy are critical.
While the paper focuses on image classification tasks, the underlying principles of the adaptive TT decomposition could potentially be extended to other deep learning domains. Further research is needed to explore the scalability and generalizability of this compression technique across a wider range of neural network architectures and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Efficient Real-Time Object Detection Framework on Resource-Constricted Hardware Devices via Software and Hardware Co-design
Mingshuo Liu, Shiyi Luo, Kevin Han, Bo Yuan, Ronald F. DeMara, Yu Bai
The fast development of object detection techniques has attracted attention to developing efficient Deep Neural Networks (DNNs). However, the current state-of-the-art DNN models can not provide a balanced solution among accuracy, speed, and model size. This paper proposes an efficient real-time object detection framework on resource-constrained hardware devices through hardware and software co-design. The Tensor Train (TT) decomposition is proposed for compressing the YOLOv5 model. By unitizing the unique characteristics given by the TT decomposition, we develop an efficient hardware accelerator based on FPGA devices. Experimental results show that the proposed method can significantly reduce the model size and improve the execution time.
Read more8/21/2024

0
PowerYOLO: Mixed Precision Model for Hardware Efficient Object Detection with Event Data
Dominika Przewlocka-Rus, Tomasz Kryjak, Marek Gorgon
The performance of object detection systems in automotive solutions must be as high as possible, with minimal response time and, due to the often battery-powered operation, low energy consumption. When designing such solutions, we therefore face challenges typical for embedded vision systems: the problem of fitting algorithms of high memory and computational complexity into small low-power devices. In this paper we propose PowerYOLO - a mixed precision solution, which targets three essential elements of such application. First, we propose a system based on a Dynamic Vision Sensor (DVS), a novel sensor, that offers low power requirements and operates well in conditions with variable illumination. It is these features that may make event cameras a preferential choice over frame cameras in some applications. Second, to ensure high accuracy and low memory and computational complexity, we propose to use 4-bit width Powers-of-Two (PoT) quantisation for convolution weights of the YOLO detector, with all other parameters quantised linearly. Finally, we embrace from PoT scheme and replace multiplication with bit-shifting to increase the efficiency of hardware acceleration of such solution, with a special convolution-batch normalisation fusion scheme. The use of specific sensor with PoT quantisation and special batch normalisation fusion leads to a unique system with almost 8x reduction in memory complexity and vast computational simplifications, with relation to a standard approach. This efficient system achieves high accuracy of mAP 0.301 on the GEN1 DVS dataset, marking the new state-of-the-art for such compressed model.
Read more7/12/2024
🔎
1
YOLOv10: Real-Time End-to-End Object Detection
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46% less latency and 25% fewer parameters for the same performance.
Read more5/24/2024
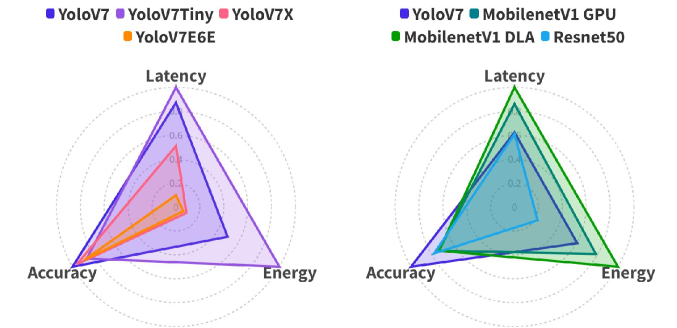
0
Context-aware Multi-Model Object Detection for Diversely Heterogeneous Compute Systems
Justin Davis, Mehmet E. Belviranli
In recent years, deep neural networks (DNNs) have gained widespread adoption for continuous mobile object detection (OD) tasks, particularly in autonomous systems. However, a prevalent issue in their deployment is the one-size-fits-all approach, where a single DNN is used, resulting in inefficient utilization of computational resources. This inefficiency is particularly detrimental in energy-constrained systems, as it degrades overall system efficiency. We identify that, the contextual information embedded in the input data stream (e.g. the frames in the camera feed that the OD models are run on) could be exploited to allow a more efficient multi-model-based OD process. In this paper, we propose SHIFT which continuously selects from a variety of DNN-based OD models depending on the dynamically changing contextual information and computational constraints. During this selection, SHIFT uniquely considers multi-accelerator execution to better optimize the energy-efficiency while satisfying the latency constraints. Our proposed methodology results in improvements of up to 7.5x in energy usage and 2.8x in latency compared to state-of-the-art GPU-based single model OD approaches.
Read more4/30/2024