Efficient Stitchable Task Adaptation

0
👨🏫
Sign in to get full access
Overview
- The paper introduces a novel framework called Efficient Stitchable Task Adaptation (ESTA) to efficiently produce a range of fine-tuned models that meet diverse resource constraints.
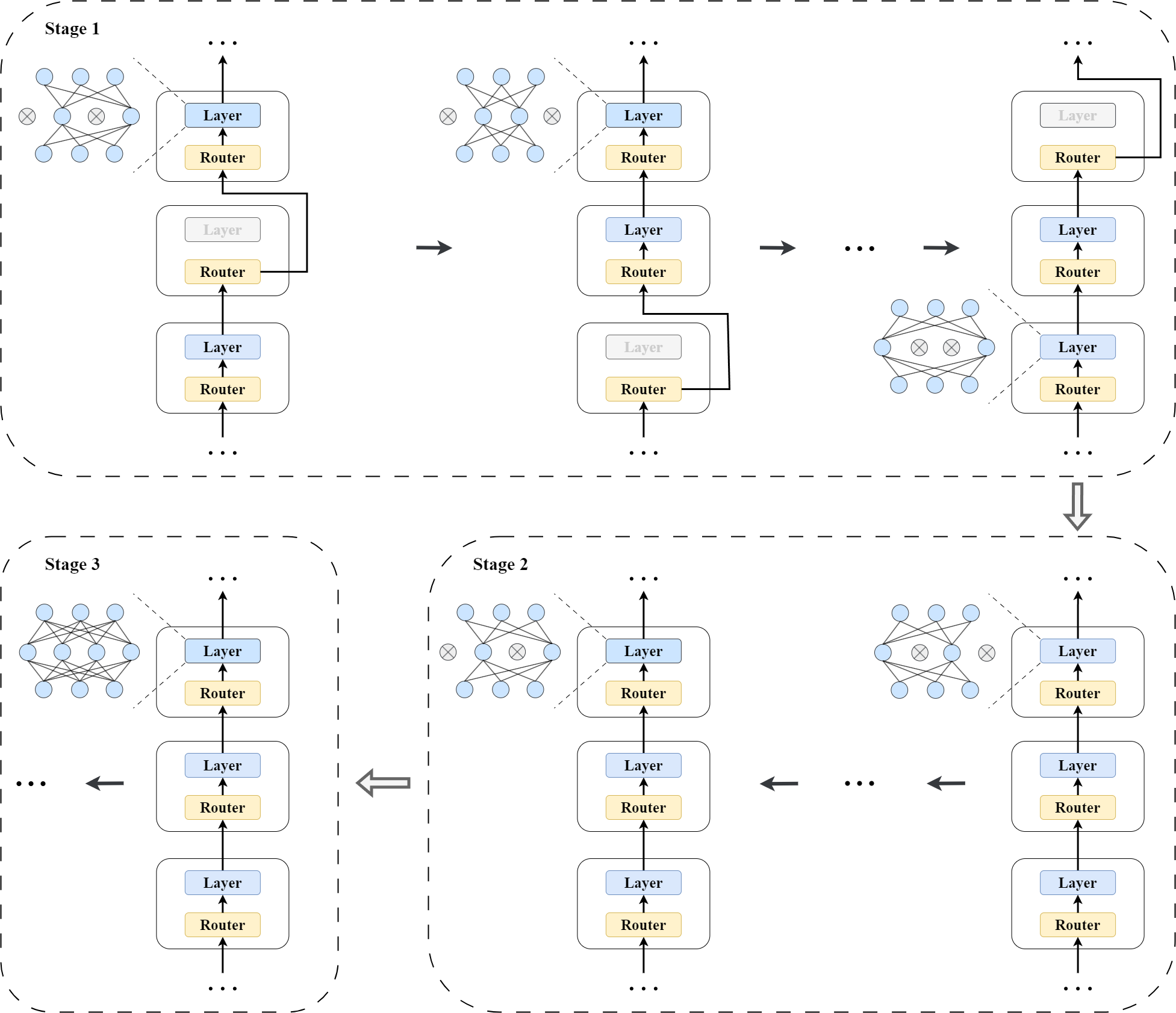
- ESTA builds on the concept of model stitching, which aims to quickly obtain numerous new networks (stitches) from pre-trained models (anchors).
- The key innovations of ESTA include parameter-efficient fine-tuning and a streamlined one-stage deployment pipeline that estimates important stitches to deploy.
Plain English Explanation
Deep learning models are often pre-trained on large datasets and then fine-tuned for specific tasks. However, most fine-tuning methods are designed to meet a specific resource budget, like memory or storage requirements. This can be limiting when deploying models in diverse scenarios with varying resource constraints.
SN-Net was introduced to address this by quickly generating numerous new "stitched" models from pre-trained "anchor" models. But SN-Net faced challenges when adapting to new domains, including high memory/storage needs and a complex, multi-stage adaptation process.
ESTA solves these problems with two key innovations:
-
Parameter-efficient fine-tuning: ESTA uses a technique that allows the stitched models to share low-rank updates while maintaining independent bias terms. This reduces the memory burden and interference between stitches during adaptation.
-
Streamlined one-stage deployment: ESTA estimates the important stitches to deploy using training-time gradient statistics. This simple yet effective pipeline boosts the accuracy-efficiency trade-off of the generated stitches.
By applying these techniques, ESTA can efficiently produce a range of fine-tuned models that meet diverse resource constraints, outperforming the direct adaptation of SN-Net with less training time and fewer parameters.
The researchers also demonstrate ESTA's flexibility by using it to stitch large language models (LLMs) from the LLaMA family, generating chatbot stitches of varying sizes.
Technical Explanation
The key technical contributions of ESTA are:
-
Parameter-efficient fine-tuning: ESTA adapts low-rank fine-tuning techniques to the model stitching scenario. This allows the stitches to share low-rank parameter updates while maintaining independent bias terms. This reduces the memory burden and interference between stitches during adaptation.
-
Streamlined one-stage deployment pipeline: ESTA estimates the important stitches to deploy using training-time gradient statistics. By assigning higher sampling probabilities to these important stitches, ESTA can generate a boosted Pareto frontier of accuracy-efficiency trade-offs.
The researchers evaluate ESTA on 25 downstream visual recognition tasks and show that it can generate stitches with smooth accuracy-efficiency trade-offs, outperforming the direct adaptation of SN-Net by significant margins. ESTA also requires less training time and fewer trainable parameters.
Furthermore, the researchers demonstrate ESTA's flexibility and scalability by using it to stitch LLMs from the LLaMA family, obtaining chatbot stitches of assorted sizes.
Critical Analysis
The paper presents a well-designed and comprehensive framework in ESTA to efficiently generate fine-tuned models for diverse resource constraints. The key innovations, including parameter-efficient fine-tuning and the streamlined deployment pipeline, are well-motivated and rigorously evaluated.
However, the paper does not discuss the potential limitations or caveats of the ESTA framework. For example, it would be helpful to understand the performance of ESTA on tasks beyond visual recognition, such as natural language processing or speech, to assess its broader applicability.
Additionally, the paper could have explored the sensitivity of ESTA's performance to factors like the choice of pre-trained anchor models or the specifics of the resource constraints. Analyzing these aspects would provide a more well-rounded understanding of the framework's strengths and weaknesses.
Overall, the ESTA framework represents a significant advancement in the efficient deployment of fine-tuned deep learning models. With further research to address potential limitations, it could become a valuable tool for deploying models in diverse real-world scenarios.
Conclusion
The ESTA framework introduced in this paper offers a novel approach to efficiently generating fine-tuned deep learning models that adhere to diverse resource constraints. By leveraging parameter-efficient fine-tuning and a streamlined deployment pipeline, ESTA can produce a range of accurate and efficient stitched models, outperforming previous methods.
The flexibility and scalability of ESTA, demonstrated by its application to stitching large language models, suggest its potential to have a broad impact on the deployment of deep learning systems in a variety of domains. As the field of deep learning continues to advance, frameworks like ESTA will become increasingly important for ensuring that the benefits of these powerful models can be realized in real-world applications with varying resource requirements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Efficient Stitchable Task Adaptation
Haoyu He, Zizheng Pan, Jing Liu, Jianfei Cai, Bohan Zhuang
The paradigm of pre-training and fine-tuning has laid the foundation for deploying deep learning models. However, most fine-tuning methods are designed to meet a specific resource budget. Recently, considering diverse deployment scenarios with various resource budgets, SN-Net is introduced to quickly obtain numerous new networks (stitches) from the pre-trained models (anchors) in a model family via model stitching. Although promising, SN-Net confronts new challenges when adapting it to new target domains, including huge memory and storage requirements and a long and sub-optimal multistage adaptation process. In this work, we present a novel framework, Efficient Stitchable Task Adaptation (ESTA), to efficiently produce a palette of fine-tuned models that adhere to diverse resource constraints. Specifically, we first tailor parameter-efficient fine-tuning to share low-rank updates among the stitches while maintaining independent bias terms. In this way, we largely reduce fine-tuning memory burdens and mitigate the interference among stitches that arises in task adaptation. Furthermore, we streamline a simple yet effective one-stage deployment pipeline, which estimates the important stitches to deploy with training-time gradient statistics. By assigning higher sampling probabilities to important stitches, we also get a boosted Pareto frontier. Extensive experiments on 25 downstream visual recognition tasks demonstrate that our ESTA is capable of generating stitches with smooth accuracy-efficiency trade-offs and surpasses the direct SN-Net adaptation by remarkable margins with significantly lower training time and fewer trainable parameters. Furthermore, we demonstrate the flexibility and scalability of our ESTA framework by stitching LLMs from LLaMA family, obtaining chatbot stitches of assorted sizes. Source code is available at https://github.com/ziplab/Stitched_LLaMA
Read more7/10/2024
0
Evolving Subnetwork Training for Large Language Models
Hanqi Li, Lu Chen, Da Ma, Zijian Wu, Su Zhu, Kai Yu
Large language models have ushered in a new era of artificial intelligence research. However, their substantial training costs hinder further development and widespread adoption. In this paper, inspired by the redundancy in the parameters of large language models, we propose a novel training paradigm: Evolving Subnetwork Training (EST). EST samples subnetworks from the layers of the large language model and from commonly used modules within each layer, Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP). By gradually increasing the size of the subnetworks during the training process, EST can save the cost of training. We apply EST to train GPT2 model and TinyLlama model, resulting in 26.7% FLOPs saving for GPT2 and 25.0% for TinyLlama without an increase in loss on the pre-training dataset. Moreover, EST leads to performance improvements in downstream tasks, indicating that it benefits generalization. Additionally, we provide intuitive theoretical studies based on training dynamics and Dropout theory to ensure the feasibility of EST. Our code is available at https://github.com/OpenDFM/EST.
Read more6/12/2024

0
Localize-and-Stitch: Efficient Model Merging via Sparse Task Arithmetic
Yifei He, Yuzheng Hu, Yong Lin, Tong Zhang, Han Zhao
Model merging offers an effective strategy to combine the strengths of multiple finetuned models into a unified model that preserves the specialized capabilities of each. Existing methods merge models in a global manner, performing arithmetic operations across all model parameters. However, such global merging often leads to task interference, degrading the performance of the merged model. In this work, we introduce Localize-and-Stitch, a novel approach that merges models in a localized way. Our algorithm works in two steps: i) Localization: identify tiny ($1%$ of the total parameters) localized regions in the finetuned models containing essential skills for the downstream tasks, and ii) Stitching: reintegrate only these essential regions back into the pretrained model for task synergy. We demonstrate that our approach effectively locates sparse regions responsible for finetuned performance, and the localized regions could be treated as compact and interpretable representations of the finetuned models (tasks). Empirically, we evaluate our method on various vision and language benchmarks, showing that it outperforms existing model merging methods under different data availability scenarios. Beyond strong empirical performance, our algorithm also facilitates model compression and preserves pretrained knowledge, enabling flexible and continual skill composition from multiple finetuned models with minimal storage and computational overhead. Our code is available at https://github.com/yifei-he/Localize-and-Stitch.
Read more8/27/2024

0
PartSTAD: 2D-to-3D Part Segmentation Task Adaptation
Hyunjin Kim, Minhyuk Sung
We introduce PartSTAD, a method designed for the task adaptation of 2D-to-3D segmentation lifting. Recent studies have highlighted the advantages of utilizing 2D segmentation models to achieve high-quality 3D segmentation through few-shot adaptation. However, previous approaches have focused on adapting 2D segmentation models for domain shift to rendered images and synthetic text descriptions, rather than optimizing the model specifically for 3D segmentation. Our proposed task adaptation method finetunes a 2D bounding box prediction model with an objective function for 3D segmentation. We introduce weights for 2D bounding boxes for adaptive merging and learn the weights using a small additional neural network. Additionally, we incorporate SAM, a foreground segmentation model on a bounding box, to improve the boundaries of 2D segments and consequently those of 3D segmentation. Our experiments on the PartNet-Mobility dataset show significant improvements with our task adaptation approach, achieving a 7.0%p increase in mIoU and a 5.2%p improvement in mAP@50 for semantic and instance segmentation compared to the SotA few-shot 3D segmentation model.
Read more7/22/2024