Evolving Subnetwork Training for Large Language Models

0
Sign in to get full access
Overview
- This paper introduces a technique called "Evolving Subnetwork Training" (EST) for training large language models more efficiently.
- The key idea is to identify and train a smaller "subnetwork" within the larger model, rather than training the entire model from scratch.
- The authors show that EST can achieve comparable performance to training the full model, while being significantly more computationally efficient.
Plain English Explanation
Large language models like GPT-3 and BERT have become incredibly powerful, but they are also very computationally expensive to train from scratch. The Efficient Pruning for Large Language Models with Adaptive Estimation and Super Tiny Language Models papers have explored ways to make training more efficient by pruning or distilling these large models.
The Evolving Subnetwork Training (EST) technique introduced in this paper builds on those ideas. The key insight is that within a large language model, there may be a smaller "subnetwork" of neurons and connections that are actually doing most of the work. Rather than training the entire model, EST tries to identify and train just this critical subnetwork.
The authors show that by focusing on this subnetwork, they can achieve comparable performance to training the full model, but do so in a much more computationally efficient way. This could make it more feasible to train large language models, especially for researchers and organizations with limited computational resources.
The Multi-Level Framework for Accelerating Training of Transformer Models paper has also explored techniques for more efficient transformer training, so EST could be seen as complementary to that work.
Technical Explanation
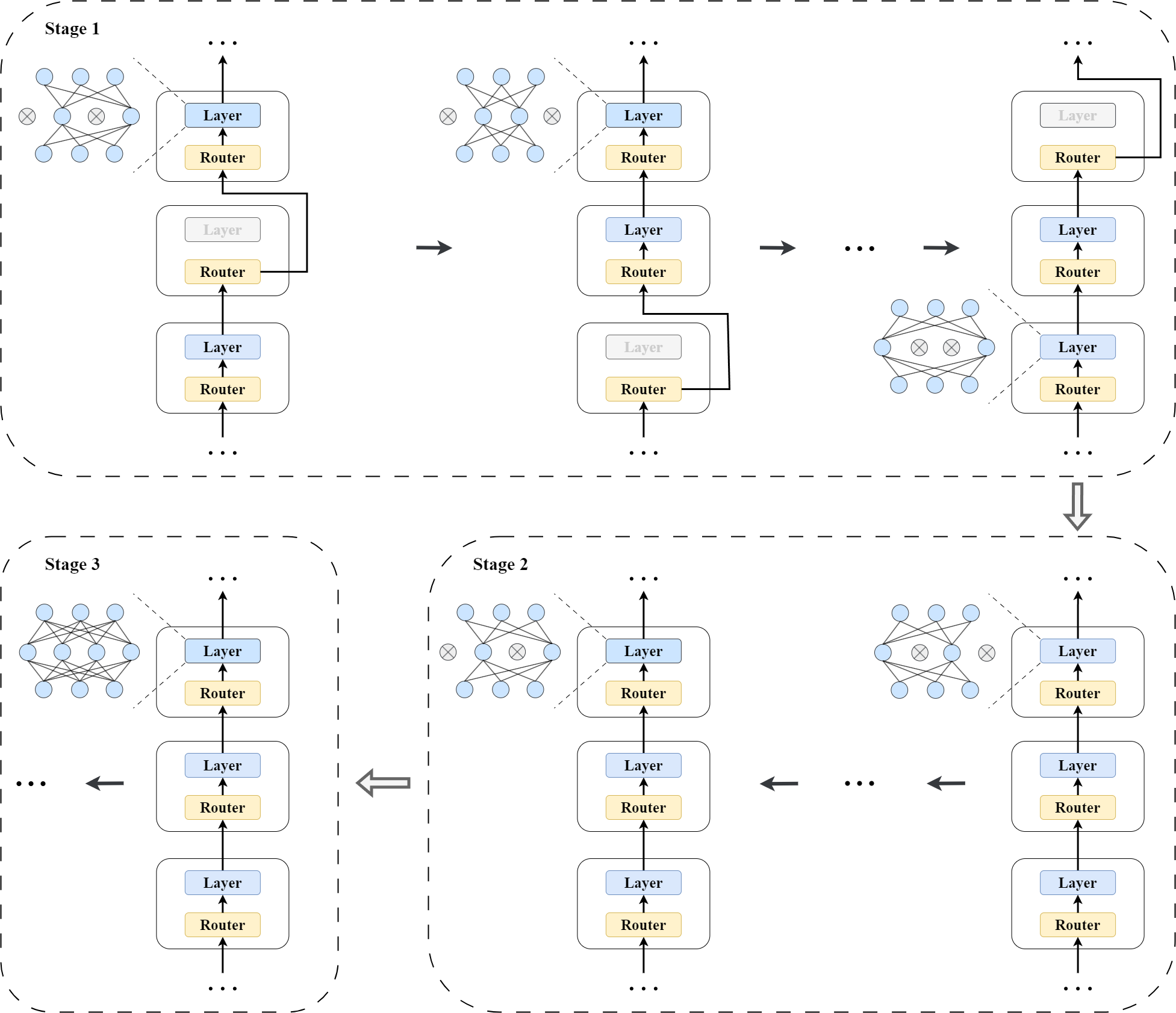
The core idea behind Evolving Subnetwork Training (EST) is to identify a smaller "subnetwork" within a large language model and train only that subnetwork, rather than training the entire model from scratch.
The authors propose an iterative process where they:
- Train the full model for some initial steps
- Prune the model to identify the most important subnetwork
- Fine-tune only the subnetwork
- Repeat steps 2-3, gradually expanding the subnetwork over time
This allows the model to focus its training on the most critical parts, rather than wasting compute on less important connections. The authors show that this can achieve comparable performance to training the full model, while being significantly more computationally efficient.
Importantly, the authors also introduce a novel pruning technique called "Weighted Gradient Magnitude Pruning" that helps identify the most important subnetwork. This outperforms simpler pruning methods like magnitude pruning.
The Towards a Better Theoretical Understanding of Independent Subnetwork Training and Heuristic for Core Understanding of Subnetwork Generalization in Pretrained Language Models papers provide useful theoretical frameworks for understanding subnetwork training, which likely helped inform the EST approach.
Critical Analysis
The EST technique represents an interesting and promising approach for making large language model training more computationally efficient. By focusing training on a critical subnetwork, the authors are able to achieve comparable performance while using significantly less compute.
That said, the paper does not address some important limitations and potential issues with the approach:
- The authors only evaluate EST on relatively small language models (e.g. GPT-2). It's unclear if the benefits would scale to truly massive models like GPT-3 or Megatron-LLM.
- The iterative pruning and fine-tuning process adds significant complexity. In practice, this may be challenging to implement and tune effectively.
- The paper does not explore the generalization properties of the subnetworks identified by EST. It's possible that these subnetworks may not transfer as well to new tasks or domains.
Ultimately, while EST is an intriguing idea, more research is needed to fully understand its strengths, weaknesses, and practical implications for training large language models. Readers should think critically about the tradeoffs and limitations of this approach as they consider its applicability to their own work.
Conclusion
The Evolving Subnetwork Training (EST) technique introduced in this paper represents an interesting and potentially impactful approach for making large language model training more computationally efficient. By identifying and training a critical subnetwork within the larger model, the authors show that comparable performance can be achieved with significantly less compute.
While EST shows promise, the paper also highlights important areas for further research and exploration. Scaling the technique to truly massive language models, understanding the generalization properties of the identified subnetworks, and managing the complexity of the iterative pruning and fine-tuning process are all important challenges that warrant additional investigation.
Nonetheless, the core ideas behind EST could have significant implications for the field of large language model development, potentially making these powerful models more accessible to a wider range of researchers and organizations. As the machine learning community continues to push the boundaries of what is possible with language models, techniques like EST may prove invaluable for pushing the state of the art in a more efficient and sustainable way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evolving Subnetwork Training for Large Language Models
Hanqi Li, Lu Chen, Da Ma, Zijian Wu, Su Zhu, Kai Yu
Large language models have ushered in a new era of artificial intelligence research. However, their substantial training costs hinder further development and widespread adoption. In this paper, inspired by the redundancy in the parameters of large language models, we propose a novel training paradigm: Evolving Subnetwork Training (EST). EST samples subnetworks from the layers of the large language model and from commonly used modules within each layer, Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP). By gradually increasing the size of the subnetworks during the training process, EST can save the cost of training. We apply EST to train GPT2 model and TinyLlama model, resulting in 26.7% FLOPs saving for GPT2 and 25.0% for TinyLlama without an increase in loss on the pre-training dataset. Moreover, EST leads to performance improvements in downstream tasks, indicating that it benefits generalization. Additionally, we provide intuitive theoretical studies based on training dynamics and Dropout theory to ensure the feasibility of EST. Our code is available at https://github.com/OpenDFM/EST.
Read more6/12/2024
👨🏫
0
Efficient Stitchable Task Adaptation
Haoyu He, Zizheng Pan, Jing Liu, Jianfei Cai, Bohan Zhuang
The paradigm of pre-training and fine-tuning has laid the foundation for deploying deep learning models. However, most fine-tuning methods are designed to meet a specific resource budget. Recently, considering diverse deployment scenarios with various resource budgets, SN-Net is introduced to quickly obtain numerous new networks (stitches) from the pre-trained models (anchors) in a model family via model stitching. Although promising, SN-Net confronts new challenges when adapting it to new target domains, including huge memory and storage requirements and a long and sub-optimal multistage adaptation process. In this work, we present a novel framework, Efficient Stitchable Task Adaptation (ESTA), to efficiently produce a palette of fine-tuned models that adhere to diverse resource constraints. Specifically, we first tailor parameter-efficient fine-tuning to share low-rank updates among the stitches while maintaining independent bias terms. In this way, we largely reduce fine-tuning memory burdens and mitigate the interference among stitches that arises in task adaptation. Furthermore, we streamline a simple yet effective one-stage deployment pipeline, which estimates the important stitches to deploy with training-time gradient statistics. By assigning higher sampling probabilities to important stitches, we also get a boosted Pareto frontier. Extensive experiments on 25 downstream visual recognition tasks demonstrate that our ESTA is capable of generating stitches with smooth accuracy-efficiency trade-offs and surpasses the direct SN-Net adaptation by remarkable margins with significantly lower training time and fewer trainable parameters. Furthermore, we demonstrate the flexibility and scalability of our ESTA framework by stitching LLMs from LLaMA family, obtaining chatbot stitches of assorted sizes. Source code is available at https://github.com/ziplab/Stitched_LLaMA
Read more7/10/2024

0
Search for Efficient Large Language Models
Xuan Shen, Pu Zhao, Yifan Gong, Zhenglun Kong, Zheng Zhan, Yushu Wu, Ming Lin, Chao Wu, Xue Lin, Yanzhi Wang
Large Language Models (LLMs) have long held sway in the realms of artificial intelligence research. Numerous efficient techniques, including weight pruning, quantization, and distillation, have been embraced to compress LLMs, targeting memory reduction and inference acceleration, which underscore the redundancy in LLMs. However, most model compression techniques concentrate on weight optimization, overlooking the exploration of optimal architectures. Besides, traditional architecture search methods, limited by the elevated complexity with extensive parameters, struggle to demonstrate their effectiveness on LLMs. In this paper, we propose a training-free architecture search framework to identify optimal subnets that preserve the fundamental strengths of the original LLMs while achieving inference acceleration. Furthermore, after generating subnets that inherit specific weights from the original LLMs, we introduce a reformation algorithm that utilizes the omitted weights to rectify the inherited weights with a small amount of calibration data. Compared with SOTA training-free structured pruning works that can generate smaller networks, our method demonstrates superior performance across standard benchmarks. Furthermore, our generated subnets can directly reduce the usage of GPU memory and achieve inference acceleration.
Read more9/27/2024
🧠
0
Neural Subnetwork Ensembles
Tim Whitaker
Neural network ensembles have been effectively used to improve generalization by combining the predictions of multiple independently trained models. However, the growing scale and complexity of deep neural networks have led to these methods becoming prohibitively expensive and time consuming to implement. Low-cost ensemble methods have become increasingly important as they can alleviate the need to train multiple models from scratch while retaining the generalization benefits that traditional ensemble learning methods afford. This dissertation introduces and formalizes a low-cost framework for constructing Subnetwork Ensembles, where a collection of child networks are formed by sampling, perturbing, and optimizing subnetworks from a trained parent model. We explore several distinct methodologies for generating child networks and we evaluate their efficacy through a variety of ablation studies and established benchmarks. Our findings reveal that this approach can greatly improve training efficiency, parametric utilization, and generalization performance while minimizing computational cost. Subnetwork Ensembles offer a compelling framework for exploring how we can build better systems by leveraging the unrealized potential of deep neural networks.
Read more7/9/2024