Efficient and Versatile Robust Fine-Tuning of Zero-shot Models

0

Sign in to get full access
Overview
- Efficient and versatile method for fine-tuning zero-shot AI models
- Combines robust fine-tuning and parameter-efficient techniques
- Enables quick adaptation to new tasks with limited data
Plain English Explanation
This research paper presents a new approach for fine-tuning zero-shot AI models - models that can perform a wide range of tasks without needing to be retrained from scratch. The key idea is to combine robust fine-tuning techniques, which make the models more resilient to overfitting, with parameter-efficient fine-tuning methods, which only update a small portion of the model.
This allows the models to be quickly adapted to new tasks while using very little training data, making them versatile and efficient. The approach also includes a self-ensemble component, which further boosts the model's performance by combining multiple fine-tuned versions of itself.
Technical Explanation
The paper proposes a two-stage fine-tuning process. First, a set of "base" adapters are trained on the target task using a small amount of data. These adapters only update a subset of the model's parameters, making the process efficient. Second, a "self-ensemble" is created by fine-tuning the model multiple times with different random seeds and hyperparameters. The predictions from these diverse fine-tuned models are then combined to produce the final output.
The authors evaluate their approach on a variety of natural language processing tasks, including text classification, question answering, and named entity recognition. They find that their method outperforms standard fine-tuning techniques, especially when only limited training data is available. The self-ensemble component is shown to provide a significant boost in performance.
Critical Analysis
The paper provides a compelling and practical solution for fine-tuning zero-shot models, addressing key challenges such as data efficiency and model robustness. The authors demonstrate the effectiveness of their approach across multiple tasks, which is a strength.
However, the paper does not delve deeply into the underlying reasons why the proposed method works so well. More analysis of the learned adapter representations and the impact of the self-ensemble would be helpful to fully understand the mechanics of the approach.
Additionally, the paper does not discuss potential limitations or failure cases of the method. It would be valuable to understand the scenarios where the technique may not perform as well, or if there are any specific requirements or assumptions that need to be met for it to be effective.
Overall, this research represents an important advancement in the field of parameter-efficient fine-tuning, with promising real-world applications. Further exploration of the method's properties and limitations could lead to even more robust and versatile fine-tuning techniques.
Conclusion
This paper introduces an efficient and versatile approach for fine-tuning zero-shot AI models, combining robust fine-tuning and parameter-efficient techniques. The method enables quick adaptation to new tasks with limited data, making it a valuable tool for a wide range of applications. The strong empirical results demonstrate the effectiveness of the proposed approach, which could have significant impact on how AI models are fine-tuned and deployed in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient and Versatile Robust Fine-Tuning of Zero-shot Models
Sungyeon Kim, Boseung Jeong, Donghyun Kim, Suha Kwak
Large-scale image-text pre-trained models enable zero-shot classification and provide consistent accuracy across various data distributions. Nonetheless, optimizing these models in downstream tasks typically requires fine-tuning, which reduces generalization to out-of-distribution (OOD) data and demands extensive computational resources. We introduce Robust Adapter (R-Adapter), a novel method for fine-tuning zero-shot models to downstream tasks while simultaneously addressing both these issues. Our method integrates lightweight modules into the pre-trained model and employs novel self-ensemble techniques to boost OOD robustness and reduce storage expenses substantially. Furthermore, we propose MPM-NCE loss designed for fine-tuning on vision-language downstream tasks. It ensures precise alignment of multiple image-text pairs and discriminative feature learning. By extending the benchmark for robust fine-tuning beyond classification to include diverse tasks such as cross-modal retrieval and open vocabulary segmentation, we demonstrate the broad applicability of R-Adapter. Our extensive experiments demonstrate that R-Adapter achieves state-of-the-art performance across a diverse set of tasks, tuning only 13% of the parameters of the CLIP encoders.
Read more8/13/2024
0
Pre-trained Model Guided Fine-Tuning for Zero-Shot Adversarial Robustness
Sibo Wang, Jie Zhang, Zheng Yuan, Shiguang Shan
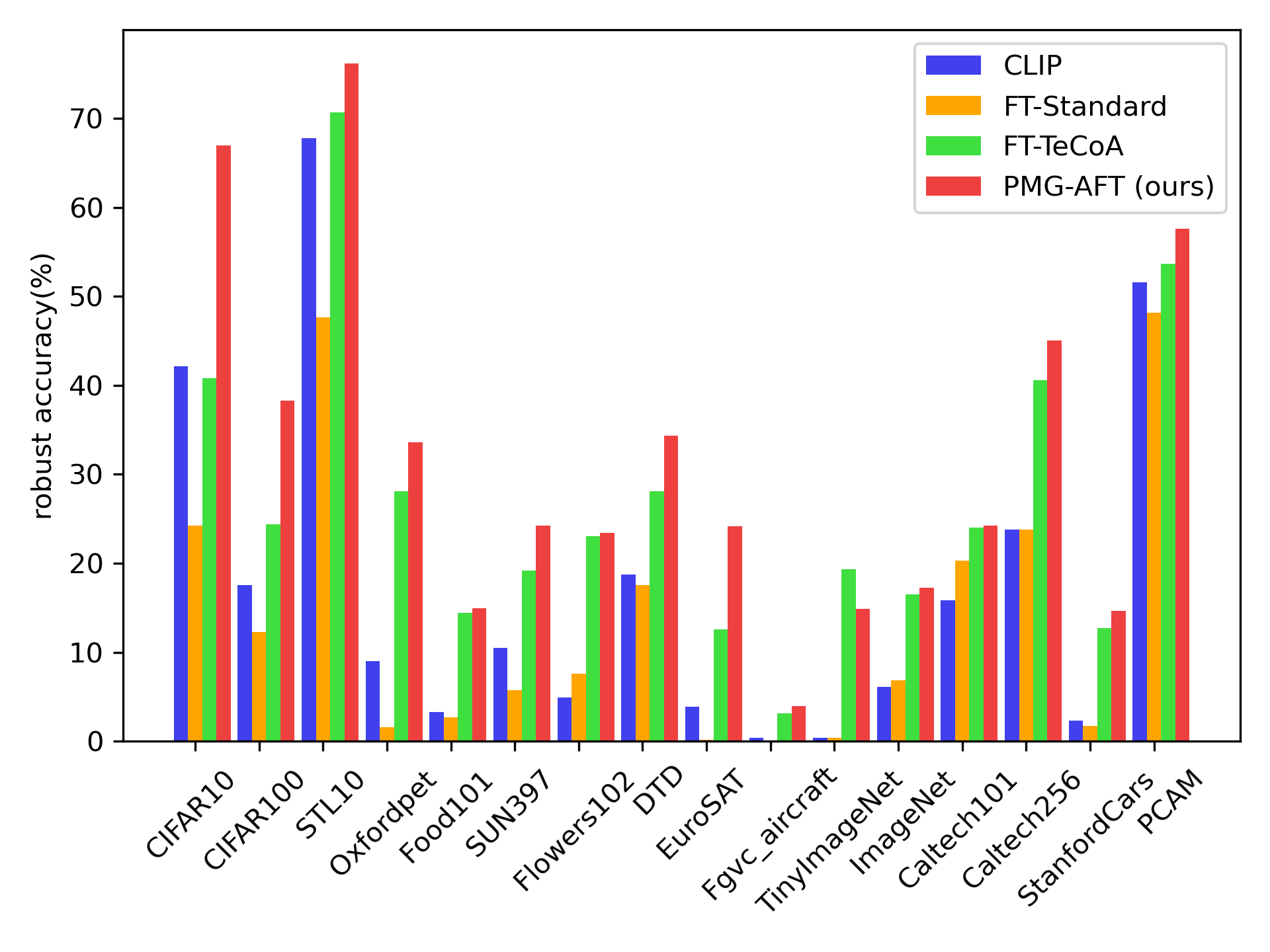
Large-scale pre-trained vision-language models like CLIP have demonstrated impressive performance across various tasks, and exhibit remarkable zero-shot generalization capability, while they are also vulnerable to imperceptible adversarial examples. Existing works typically employ adversarial training (fine-tuning) as a defense method against adversarial examples. However, direct application to the CLIP model may result in overfitting, compromising the model's capacity for generalization. In this paper, we propose Pre-trained Model Guided Adversarial Fine-Tuning (PMG-AFT) method, which leverages supervision from the original pre-trained model by carefully designing an auxiliary branch, to enhance the model's zero-shot adversarial robustness. Specifically, PMG-AFT minimizes the distance between the features of adversarial examples in the target model and those in the pre-trained model, aiming to preserve the generalization features already captured by the pre-trained model. Extensive Experiments on 15 zero-shot datasets demonstrate that PMG-AFT significantly outperforms the state-of-the-art method, improving the top-1 robust accuracy by an average of 4.99%. Furthermore, our approach consistently improves clean accuracy by an average of 8.72%. Our code is available at https://github.com/serendipity1122/Pre-trained-Model-Guided-Fine-Tuning-for-Zero-Shot-Adversarial-Robustness.
Read more4/11/2024

0
Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Minglei Li, Peng Ye, Yongqi Huang, Lin Zhang, Tao Chen, Tong He, Jiayuan Fan, Wanli Ouyang
Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
Read more6/7/2024

0
An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
Varsha Suresh, Salah Ait-Mokhtar, Caroline Brun, Ioan Calapodescu
Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
Read more6/24/2024