An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
2406.14747
0
0

Abstract
Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
Create account to get full access
Overview
- This paper presents an adapter-based unified model for multiple spoken language processing tasks, such as speech recognition, language understanding, and dialogue management.
- The model leverages parameter-efficient fine-tuning of a pre-trained language model and can be easily adapted to different tasks and languages.
- The authors demonstrate the model's effectiveness on various tasks, including Universal Spoken Language Understanding (UniSpeech), Dual-Task Learning, and Fine-Grained Controllability in Speech Generation.
Plain English Explanation
The paper introduces a new way to build AI models that can handle multiple spoken language processing tasks, like understanding speech, translating languages, and managing conversations. The key idea is to start with a pre-trained language model, which is a powerful AI system that has been trained on a vast amount of text data, and then adapt it to different tasks and languages using a technique called "adapter-based fine-tuning."
This approach is more efficient than building a separate model for each task or language, as it allows the model to reuse the knowledge it has already acquired. The authors show that this adapter-based model performs well on a variety of tasks, including some state-of-the-art systems like UniSpeech, Dual-Task Learning, and Fine-Grained Controllability in Speech Generation.
The benefit of this approach is that it makes it easier to build versatile AI systems that can handle multiple spoken language processing tasks, which could be useful for a wide range of applications, such as virtual assistants, translation services, and voice-based interfaces.
Technical Explanation
The paper presents an adapter-based unified model for multiple spoken language processing tasks, building on the concept of parameter-efficient fine-tuning using adapters. The authors start with a pre-trained language model, such as BERT or RoBERTa, and add task-specific adapter modules to the model. These adapter modules can be trained efficiently on different tasks and languages, allowing the model to be easily adapted to new domains without significantly increasing the number of parameters.
The authors evaluate the performance of their adapter-based model on various spoken language processing tasks, including speech recognition, language understanding, and dialogue management. They demonstrate that their approach outperforms or matches the performance of task-specific models, while requiring significantly fewer parameters to be trained.
One key aspect of the model is its ability to handle multi-task learning, where the model is trained on multiple tasks simultaneously. The authors show that this multi-task learning can lead to improved performance on individual tasks, as the model is able to leverage shared representations and transfer knowledge across tasks.
The paper also explores the use of the adapter-based model for language adaptation in text-to-speech (TTS) systems, demonstrating the model's flexibility and broad applicability to different types of spoken language processing tasks.
Critical Analysis
The paper presents a promising approach for building versatile and efficient AI models for spoken language processing, but there are a few potential limitations and areas for further research:
- The paper focuses on relatively high-resource languages and tasks, and it's unclear how well the adapter-based approach would scale to low-resource languages or niche domains.
- The authors only evaluate the model on a limited set of tasks, and additional research is needed to understand the model's performance on a wider range of spoken language processing challenges.
- The paper does not provide a detailed analysis of the computational and memory efficiency of the adapter-based model, which would be important for real-world deployment, especially on resource-constrained devices.
- The paper does not address potential ethical concerns, such as the model's robustness to biases or its ability to handle sensitive or personal information in spoken language interactions.
Overall, the paper presents an interesting and potentially impactful approach to building more versatile and efficient AI systems for spoken language processing. By continuing to explore the limits and potential applications of this adapter-based approach, researchers can contribute to the ongoing progress in this important field of AI.
Conclusion
The paper introduces an adapter-based unified model for multiple spoken language processing tasks, which leverages parameter-efficient fine-tuning to adapt a pre-trained language model to different domains and languages. The authors demonstrate the model's effectiveness on a range of tasks, including state-of-the-art systems like UniSpeech, Dual-Task Learning, and Fine-Grained Controllability in Speech Generation.
This adapter-based approach has the potential to simplify the development of versatile AI systems for a wide range of spoken language processing applications, such as virtual assistants, translation services, and voice-based interfaces. By continuing to explore the capabilities and limitations of this model, researchers can contribute to the ongoing progress in this important field of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
0
0
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
5/10/2024
💬
UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
Siddhant Arora, Hayato Futami, Jee-weon Jung, Yifan Peng, Roshan Sharma, Yosuke Kashiwagi, Emiru Tsunoo, Karen Livescu, Shinji Watanabe
0
0
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
4/4/2024
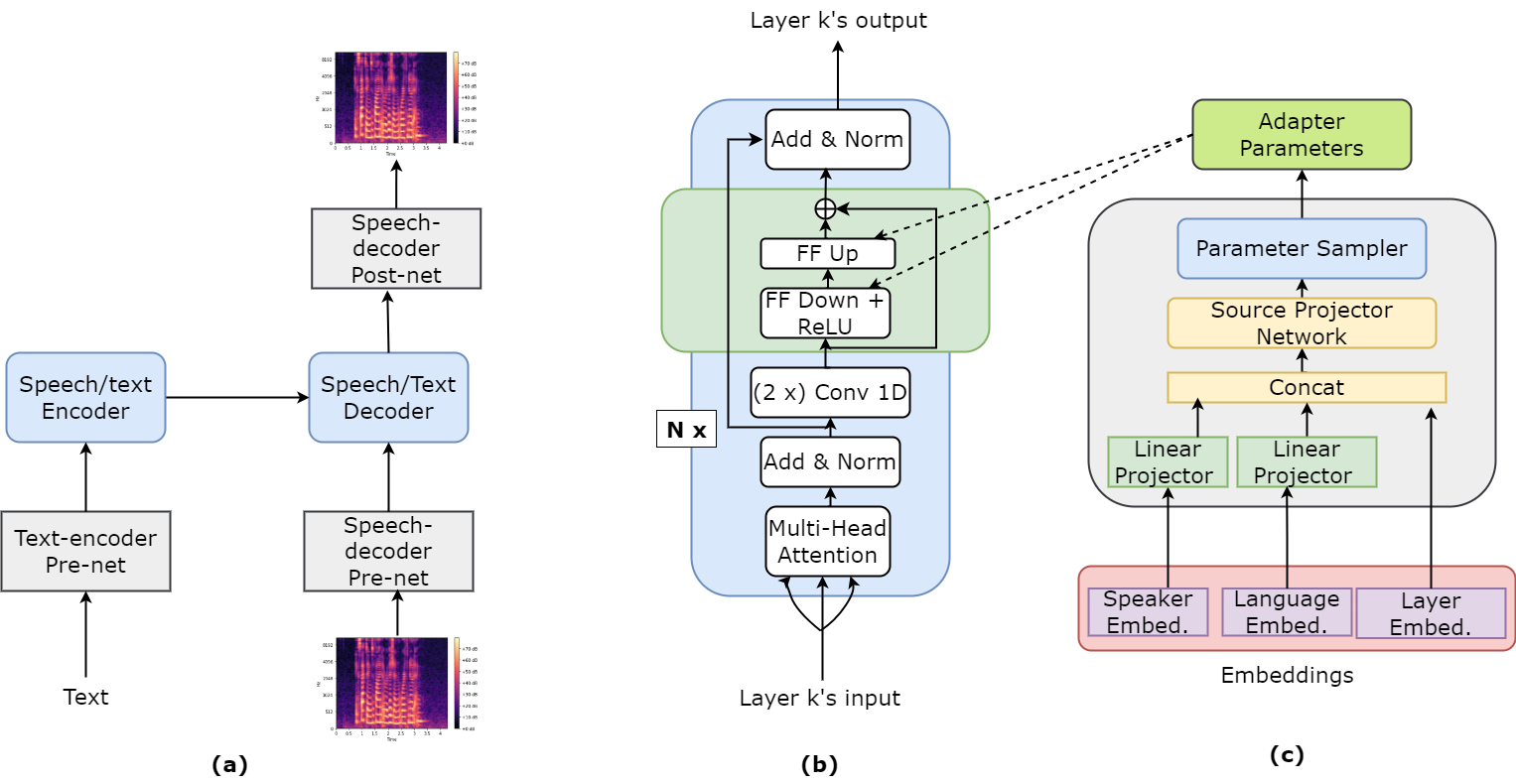
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
0
0
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
6/26/2024
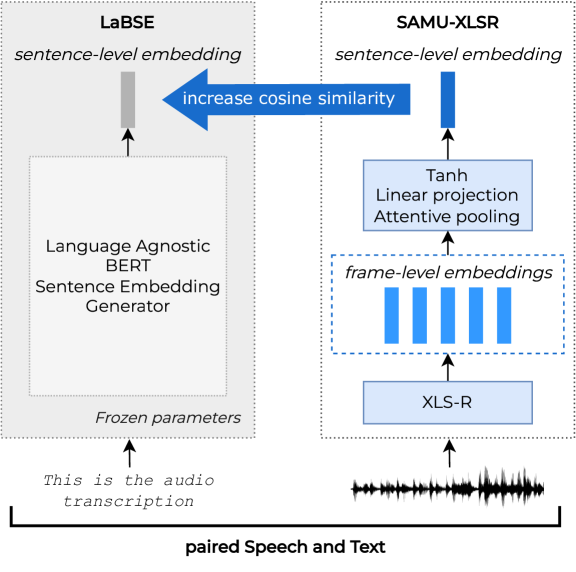
A dual task learning approach to fine-tune a multilingual semantic speech encoder for Spoken Language Understanding
Gaelle Laperri`ere, Sahar Ghannay, Bassam Jabaian, Yannick Est`eve
0
0
Self-Supervised Learning is vastly used to efficiently represent speech for Spoken Language Understanding, gradually replacing conventional approaches. Meanwhile, textual SSL models are proposed to encode language-agnostic semantics. SAMU-XLSR framework employed this semantic information to enrich multilingual speech representations. A recent study investigated SAMU-XLSR in-domain semantic enrichment by specializing it on downstream transcriptions, leading to state-of-the-art results on a challenging SLU task. This study's interest lies in the loss of multilingual performances and lack of specific-semantics training induced by such specialization in close languages without any SLU implication. We also consider SAMU-XLSR's loss of initial cross-lingual abilities due to a separate SLU fine-tuning. Therefore, this paper proposes a dual task learning approach to improve SAMU-XLSR semantic enrichment while considering distant languages for multilingual and language portability experiments.
6/19/2024