Efficient4D: Fast Dynamic 3D Object Generation from a Single-view Video

0

Sign in to get full access
Overview
- This paper presents a method for fast dynamic 3D object generation from a single-view video.
- It addresses the challenge of creating high-quality 3D animations from limited input data.
- The approach combines techniques like 3D reconstruction, texturing, and motion estimation to generate detailed 4D representations of moving objects.
Plain English Explanation
The paper describes a way to create 3D animations of moving objects using just a single video as input. This is a difficult task because converting 2D video into 3D models with realistic motion is very complex.
The key idea is to combine different computer vision techniques to reconstruct the 3D shape of an object, apply realistic textures to it, and then estimate how it moves over time. This allows generating a complete 4D representation - the 3D object changing and moving in a natural way across the video.
The method aims to do this quickly and efficiently, without requiring extensive manual work or expensive 3D scanning equipment. It could enable new applications like creating dynamic virtual environments from simple videos.
Technical Explanation
The paper proposes a pipeline for generating dynamic 3D objects from a single-view video. It first uses structure-from-motion and depth estimation techniques to reconstruct the 3D shape of the object. Next, it applies texture mapping to add detailed appearance information. Finally, it estimates the object's motion over time using optical flow and other motion analysis methods.
This 4D representation (3D shape plus time-varying motion) is then used to synthesize new videos of the object moving realistically. The researchers demonstrate results on various object categories, showing plausible animations generated from just a few seconds of input footage.
The key technical innovations include an efficient optimization scheme for 3D reconstruction, novel texture blending approaches, and motion estimation techniques tailored for non-rigid dynamic objects. Extensive experiments validate the quality and speed of the proposed method compared to prior work.
Critical Analysis
The paper makes a compelling case for the value of this technology, but also acknowledges some limitations. The 3D reconstructions and motion estimates are not perfect, and may have visible artifacts or implausible movements in some cases. The method also assumes a single, isolated moving object in the input video, which may not always be the case in real-world scenes.
Additionally, the evaluations primarily focus on synthetic or controlled datasets, so further research is needed to understand how well the approach generalizes to more complex real-world videos. Integrating this technique with higher-level scene understanding could also be an interesting direction for future work.
Overall, the paper represents an impressive step forward in efficient 4D content generation from minimal input data. With further refinements, it could enable new applications in areas like virtual/augmented reality, visual effects, and interactive entertainment.
Conclusion
This paper introduces a novel method for fast dynamic 3D object generation from single-view videos. By combining 3D reconstruction, texturing, and motion estimation techniques, the approach can create plausible 4D representations of moving objects.
The key advantages are the speed and efficiency of the pipeline, which could enable new applications in areas like virtual environments and visual effects. While the results have some limitations, the research represents an important advancement in the field of 4D content creation from limited input data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient4D: Fast Dynamic 3D Object Generation from a Single-view Video
Zijie Pan, Zeyu Yang, Xiatian Zhu, Li Zhang
Generating dynamic 3D object from a single-view video is challenging due to the lack of 4D labeled data. An intuitive approach is to extend previous image-to-3D pipelines by transferring off-the-shelf image generation models such as score distillation sampling.However, this approach would be slow and expensive to scale due to the need for back-propagating the information-limited supervision signals through a large pretrained model. To address this, we propose an efficient video-to-4D object generation framework called Efficient4D. It generates high-quality spacetime-consistent images under different camera views, and then uses them as labeled data to directly reconstruct the 4D content through a 4D Gaussian splatting model. Importantly, our method can achieve real-time rendering under continuous camera trajectories. To enable robust reconstruction under sparse views, we introduce inconsistency-aware confidence-weighted loss design, along with a lightly weighted score distillation loss. Extensive experiments on both synthetic and real videos show that Efficient4D offers a remarkable 10-fold increase in speed when compared to prior art alternatives while preserving the quality of novel view synthesis. For example, Efficient4D takes only 10 minutes to model a dynamic object, vs 120 minutes by the previous art model Consistent4D.
Read more7/23/2024
0
EG4D: Explicit Generation of 4D Object without Score Distillation
Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Shengming Yin, Wengang Zhou, Jing Liao, Houqiang Li
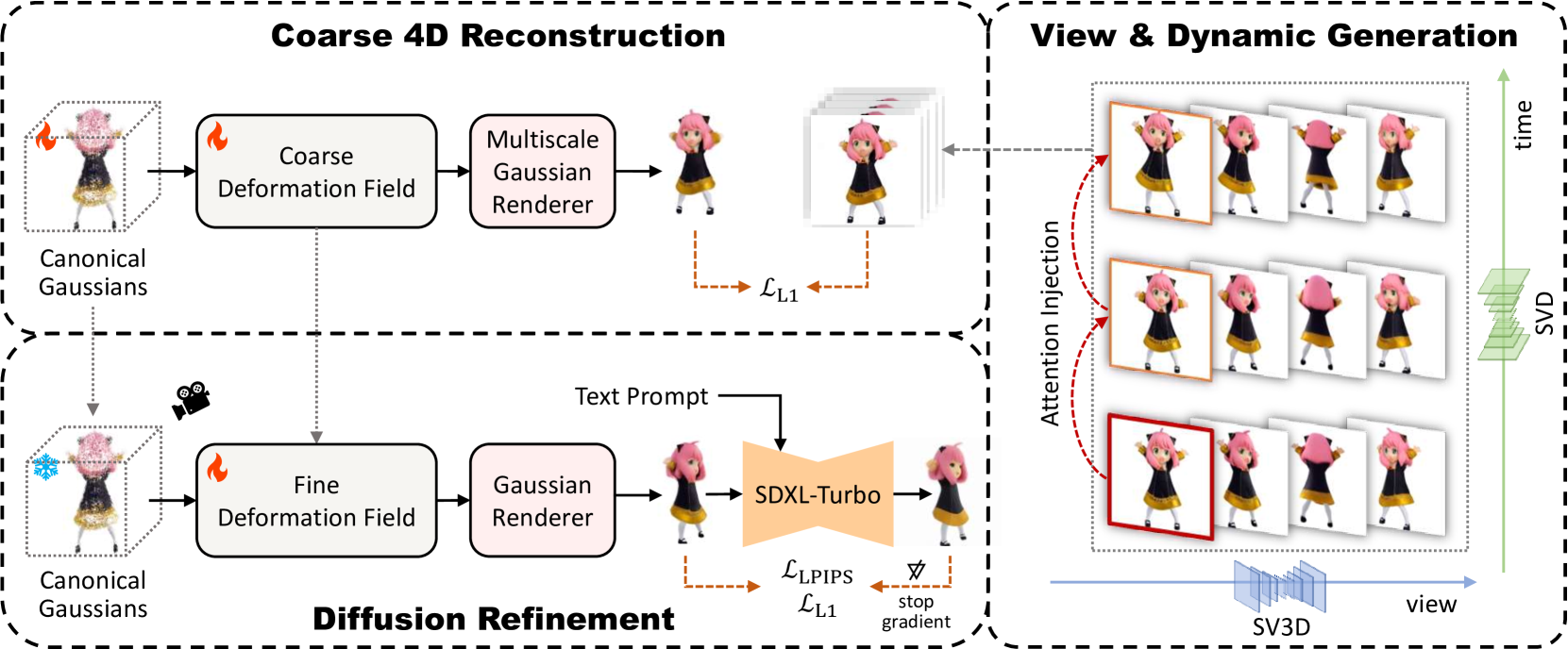
In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at url{https://github.com/jasongzy/EG4D}.
Read more5/29/2024

0
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, Varun Jampani
We present Stable Video 4D (SV4D), a latent video diffusion model for multi-frame and multi-view consistent dynamic 3D content generation. Unlike previous methods that rely on separately trained generative models for video generation and novel view synthesis, we design a unified diffusion model to generate novel view videos of dynamic 3D objects. Specifically, given a monocular reference video, SV4D generates novel views for each video frame that are temporally consistent. We then use the generated novel view videos to optimize an implicit 4D representation (dynamic NeRF) efficiently, without the need for cumbersome SDS-based optimization used in most prior works. To train our unified novel view video generation model, we curated a dynamic 3D object dataset from the existing Objaverse dataset. Extensive experimental results on multiple datasets and user studies demonstrate SV4D's state-of-the-art performance on novel-view video synthesis as well as 4D generation compared to prior works.
Read more7/25/2024
0
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, Xiang Bai
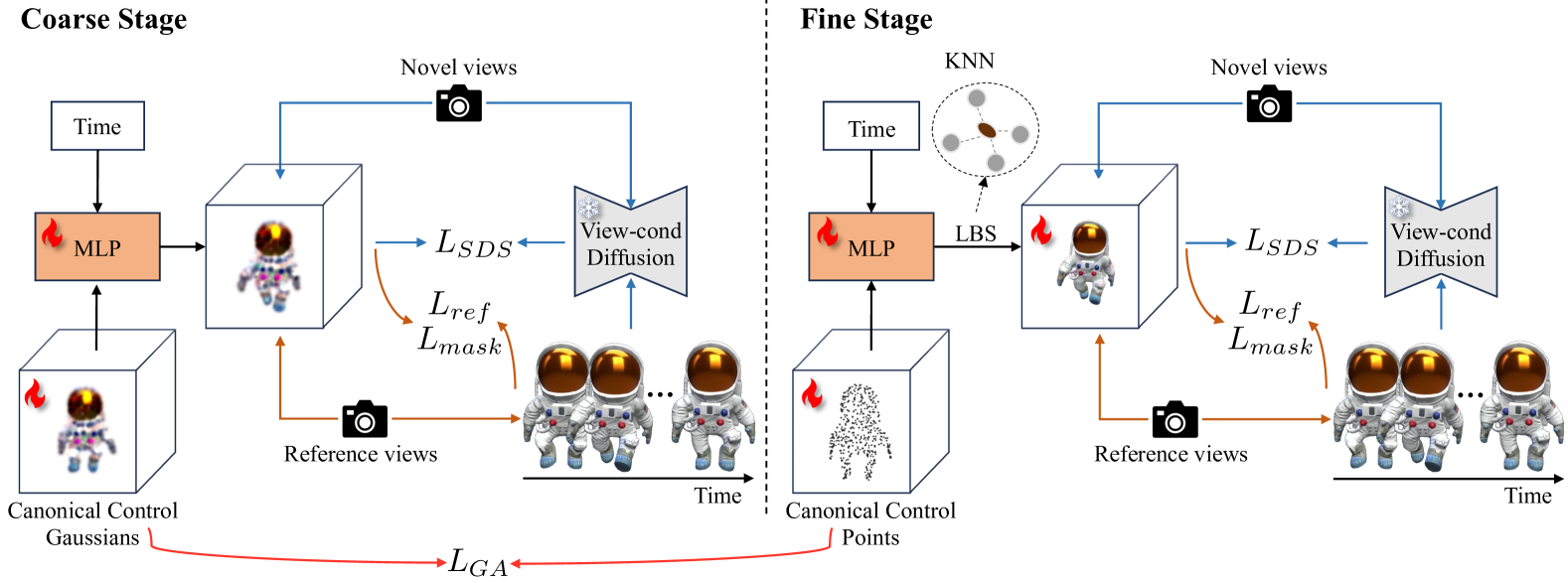
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
Read more8/15/2024