An Empirical Study of In-context Learning in LLMs for Machine Translation
2401.12097
0
0
📈
Abstract
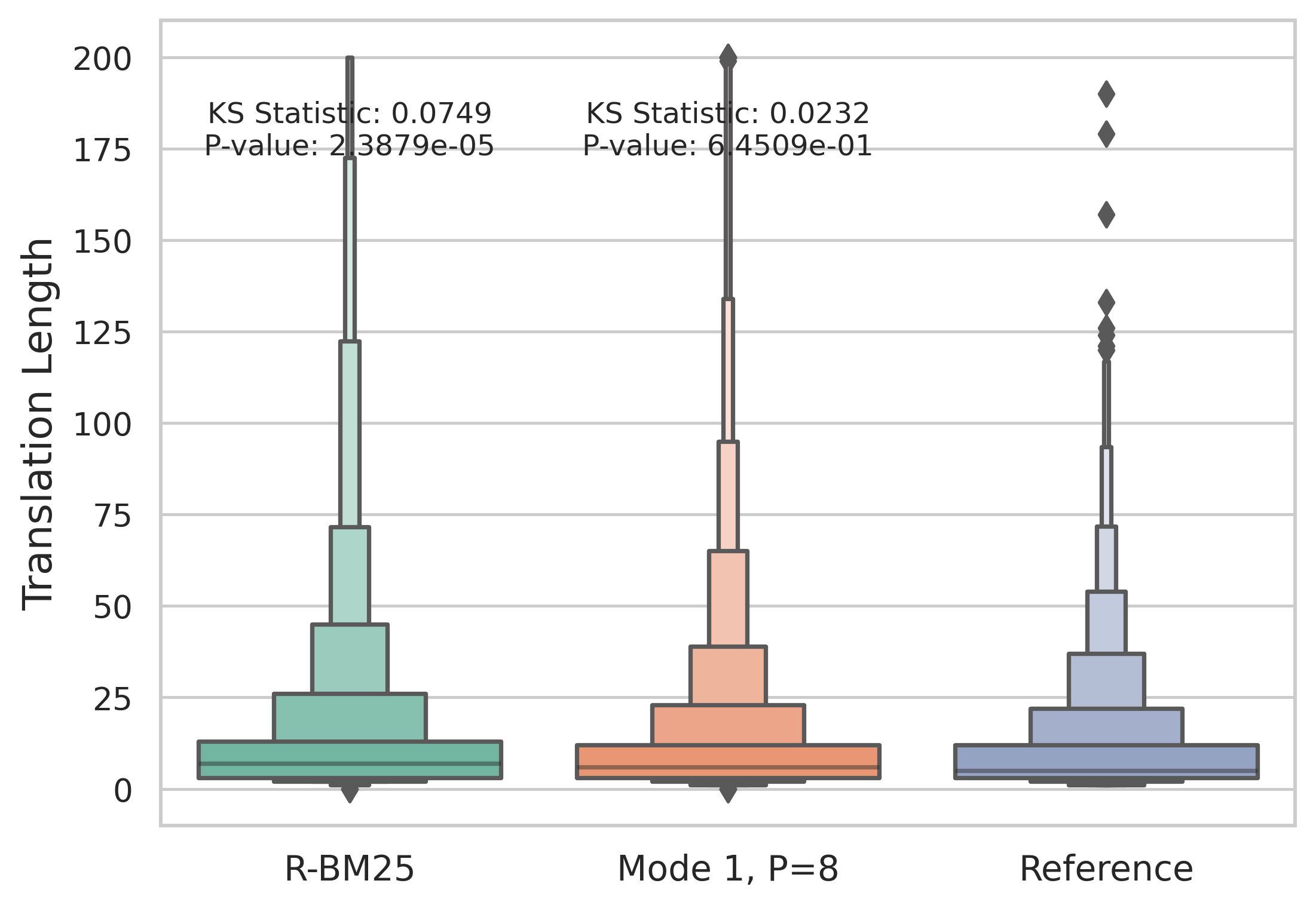
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
Create account to get full access
Overview
- The paper explores the use of Large Language Models (LLMs) for machine translation (MT) through in-context learning (ICL).
- The study focuses on understanding the specific aspects of ICL that influence translation quality, rather than just optimizing for translation quality.
- The researchers conduct an exhaustive study to understand the influence of various factors related to the examples used in ICL, such as quality, quantity, spatial proximity, and the relationship between source and target distributions.
- The study also investigates challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL.
Plain English Explanation
The researchers are interested in using a type of AI called a Large Language Model (LLM) to translate text from one language to another. This is done through a technique called in-context learning (ICL), where the LLM learns to translate by looking at example translations.
The main goal of the study is to understand what factors about these example translations influence the quality of the final translations. They look at things like how good the example translations are, how many examples there are, how closely the examples are related to the text being translated, and whether the examples come from the same task or a related one.
The researchers also explore some more challenging scenarios, where the examples don't directly match the text being translated. They want to see how well the LLM can handle these more complex situations.
Overall, the study aims to provide guidance on how to effectively use ICL for machine translation, by understanding the key factors that affect the translation quality.
Technical Explanation
The paper first establishes that ICL is primarily example-driven and not instruction-driven. The researchers then conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance.
Their analysis includes factors such as:
- Quality and quantity of demonstrations
- Spatial proximity of examples
- Relationship between source and target distributions of the examples
The study further investigates challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL.
While the researchers establish the significance of the quality of the target distribution over the source distribution of demonstrations, they also observe that perturbations sometimes act as regularizers, resulting in performance improvements.
Surprisingly, the study finds that ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient.
Critical Analysis
The paper provides a comprehensive and insightful analysis of the factors that influence the performance of in-context learning for machine translation. However, the researchers acknowledge that their study is limited to a specific set of tasks and datasets, and further research may be needed to validate the generalizability of their findings.
Additionally, the paper does not delve into potential biases or ethical considerations that may arise from the use of LLMs in machine translation. As these models are trained on large, diverse datasets, they may inherit or amplify societal biases, which could have significant implications for the fairness and inclusivity of machine translation systems.
Moreover, the paper does not address the computational and resource-intensive nature of in-context learning, which may limit its practical deployment, especially for resource-constrained environments. Exploring more efficient and scalable approaches to in-context learning could be an area for future research.
Conclusion
This study offers valuable insights into the factors that influence the performance of in-context learning for machine translation. By understanding the role of example quality, quantity, and the relationship between source and target distributions, researchers and practitioners can make more informed decisions when deploying LLMs for translation tasks.
The findings also suggest that ICL has the potential to generalize beyond the specific task or dataset, which could lead to more versatile and adaptable machine translation systems. However, further research is needed to address the potential biases and scalability challenges associated with these techniques.
Overall, this paper provides a solid foundation for further exploration and refinement of in-context learning for machine translation and other language-related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Guiding In-Context Learning of LLMs through Quality Estimation for Machine Translation
Javad Pourmostafa Roshan Sharami, Dimitar Shterionov, Pieter Spronck
0
0
The quality of output from large language models (LLMs), particularly in machine translation (MT), is closely tied to the quality of in-context examples (ICEs) provided along with the query, i.e., the text to translate. The effectiveness of these ICEs is influenced by various factors, such as the domain of the source text, the order in which the ICEs are presented, the number of these examples, and the prompt templates used. Naturally, selecting the most impactful ICEs depends on understanding how these affect the resulting translation quality, which ultimately relies on translation references or human judgment. This paper presents a novel methodology for in-context learning (ICL) that relies on a search algorithm guided by domain-specific quality estimation (QE). Leveraging the XGLM model, our methodology estimates the resulting translation quality without the need for translation references, selecting effective ICEs for MT to maximize translation quality. Our results demonstrate significant improvements over existing ICL methods and higher translation performance compared to fine-tuning a pre-trained language model (PLM), specifically mBART-50.
6/13/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
Going Beyond Word Matching: Syntax Improves In-context Example Selection for Machine Translation
Chenming Tang, Zhixiang Wang, Yunfang Wu
0
0
In-context learning (ICL) is the trending prompting strategy in the era of large language models (LLMs), where a few examples are demonstrated to evoke LLMs' power for a given task. How to select informative examples remains an open issue. Previous works on in-context example selection for machine translation (MT) focus on superficial word-level features while ignoring deep syntax-level knowledge. In this paper, we propose a syntax-based in-context example selection method for MT, by computing the syntactic similarity between dependency trees using Polynomial Distance. In addition, we propose an ensemble strategy combining examples selected by both word-level and syntax-level criteria. Experimental results between English and 6 common languages indicate that syntax can effectively enhancing ICL for MT, obtaining the highest COMET scores on 11 out of 12 translation directions.
5/30/2024
Is In-Context Learning Sufficient for Instruction Following in LLMs?
Hao Zhao, Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion
0
0
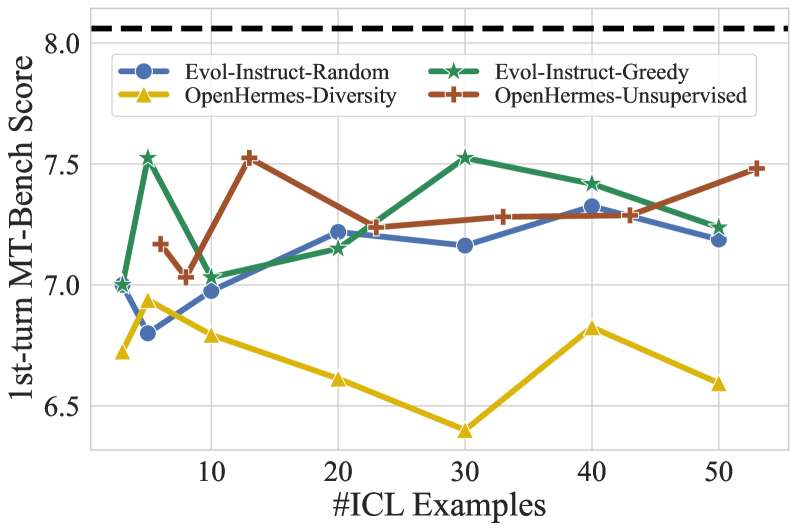
In-context learning (ICL) allows LLMs to learn from examples without changing their weights, which is a particularly promising capability for long-context LLMs that can potentially learn from many examples. Recently, Lin et al. (2024) proposed URIAL, a method using only three in-context examples to align base LLMs, achieving non-trivial instruction following performance. In this work, we show that, while effective, ICL alignment with URIAL still underperforms compared to instruction fine-tuning on established benchmarks such as MT-Bench and AlpacaEval 2.0 (LC), especially with more capable base LMs. Unlike for tasks such as classification, translation, or summarization, adding more ICL demonstrations for long-context LLMs does not systematically improve instruction following performance. To address this limitation, we derive a greedy selection approach for ICL examples that noticeably improves performance, yet without bridging the gap to instruction fine-tuning. Finally, we provide a series of ablation studies to better understand the reasons behind the remaining gap, and we show how some aspects of ICL depart from the existing knowledge and are specific to the instruction tuning setting. Overall, our work advances the understanding of ICL as an alignment technique. We provide our code at https://github.com/tml-epfl/icl-alignment.
5/31/2024