Adapting Large Language Models for Document-Level Machine Translation
2401.06468
0
0

Abstract
Large language models (LLMs) have significantly advanced various natural language processing (NLP) tasks. Recent research indicates that moderately-sized LLMs often outperform larger ones after task-specific fine-tuning. This study focuses on adapting LLMs for document-level machine translation (DocMT) for specific language pairs. We first investigate the impact of prompt strategies on translation performance and then conduct extensive experiments using two fine-tuning methods, three LLM backbones, and 18 translation tasks across nine language pairs. Our results show that specialized models can sometimes surpass GPT-4 in translation performance but still face issues like off-target translation due to error propagation in decoding. We provide an in-depth analysis of these LLMs tailored for DocMT, examining translation errors, discourse phenomena, training strategies, the scaling law of parallel documents, recent test set evaluations, and zero-shot crosslingual transfer. Our findings highlight the strengths and limitations of LLM-based DocMT models and provide a foundation for future research.
Create account to get full access
Overview
- This paper explores adapting large language models (LLMs) for document-level machine translation (MT), which aims to translate entire documents rather than just individual sentences.
- The researchers investigate how to effectively fine-tune LLMs like GPT-3 and T5 to perform document-level MT, addressing challenges like preserving document context and generating coherent translations.
- They propose several techniques, including document-level fine-tuning, cross-attention layer initialization, and prompt engineering, and evaluate the performance of their approaches on various benchmark datasets.
Plain English Explanation
Machine translation (MT) is the process of automatically translating text from one language to another. Traditional MT systems have typically focused on translating individual sentences, which can miss important context and lead to less coherent translations.
This paper explores a new approach to MT that aims to translate entire documents instead of just sentences. The researchers want to adapt powerful large language models (LLMs) like GPT-3 and T5 to perform this "document-level" machine translation. LLMs are AI systems that have been trained on massive amounts of text data, allowing them to generate human-like language.
The key challenges the researchers tackle are:
- Preserving the context and meaning of the entire document during translation, rather than just translating each sentence in isolation.
- Generating translated text that flows naturally and coherently, rather than a patchwork of disjointed sentences.
To address these challenges, the researchers experiment with several techniques:
- Document-level fine-tuning: They fine-tune the LLMs on complete translated documents, rather than just individual sentences, to help the models understand document-level context.
- Cross-attention layer initialization: They initialize certain model layers in a way that encourages the LLMs to attend to the broader document context when generating translations.
- Prompt engineering: They carefully design the prompts (instructions) given to the LLMs to steer them towards producing more coherent, document-level translations.
The researchers evaluate these approaches on standard benchmarks for document-level machine translation, and find that their techniques can significantly improve translation quality compared to sentence-level baselines. This suggests that adapting powerful LLMs could be a promising direction for advancing the state-of-the-art in document-level machine translation.
Technical Explanation
The paper explores adapting large language models for document-level machine translation. The researchers investigate techniques for fine-tuning large language models (LLMs) like GPT-3 and T5 to perform document-level machine translation (MT), going beyond the typical sentence-level approach.
The key challenges addressed are preserving document-level context and generating coherent, fluent translations, rather than just translating individual sentences in isolation. To this end, the researchers propose several techniques:
-
Document-level fine-tuning: Instead of fine-tuning the LLMs on individual sentence pairs, they fine-tune on complete translated document pairs. This encourages the models to learn document-level translation patterns.
-
Cross-attention layer initialization: The researchers initialize certain model layers (the cross-attention layers) in a way that biases the LLMs to attend to the broader document context when generating translations.
-
Prompt engineering: The team carefully designs the prompts (instructions) given to the LLMs to steer them towards producing more coherent, document-level translations.
The researchers evaluate these techniques on standard benchmarks for document-level machine translation, including the DocEssayMT and DocREDE datasets. They find that their approaches can significantly outperform sentence-level translation baselines, indicating that adapting powerful LLMs is a promising direction for advancing the state-of-the-art in document-level MT.
Critical Analysis
The paper presents a thoughtful and well-designed approach to adapting large language models for document-level machine translation. The core ideas, such as document-level fine-tuning and cross-attention layer initialization, are well-motivated and show promising empirical results.
However, the paper does acknowledge some limitations and areas for further research. For instance, the document-level fine-tuning approach relies on the availability of high-quality translated document pairs, which may not always be readily available. Additionally, the prompt engineering technique requires careful manual curation, which could limit scalability.
It would be interesting to see further research exploring more automated or unsupervised methods for adapting LLMs to document-level MT, perhaps drawing inspiration from approaches that aim to elicit translation ability in LLMs or techniques for guiding LLMs to perform post-editing. Incorporating more feedback and interaction with human translators could also help refine the document-level translation capabilities of these models.
Overall, this paper represents an important step forward in leveraging the power of large language models for more holistic, context-aware machine translation. The proposed techniques and insights could serve as a valuable foundation for further advancements in this area.
Conclusion
This paper explores novel techniques for adapting powerful large language models (LLMs) to perform document-level machine translation (MT), going beyond the traditional sentence-level approach. The researchers propose several methods, including document-level fine-tuning, cross-attention layer initialization, and prompt engineering, to help LLMs preserve document-level context and generate more coherent, fluent translations.
The empirical results demonstrate that these approaches can significantly improve translation quality on standard benchmarks, suggesting that adapting LLMs is a promising direction for advancing the state-of-the-art in document-level MT. While the paper acknowledges some limitations, such as the need for high-quality document-level training data, the insights and techniques presented could serve as a valuable foundation for further research in this area.
As LLMs continue to grow in capability and become more widely adopted, their application to challenging language tasks like document-level machine translation will be an important area of exploration. This paper represents an important step forward in unlocking the potential of these powerful AI systems for more holistic, context-aware language translation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024
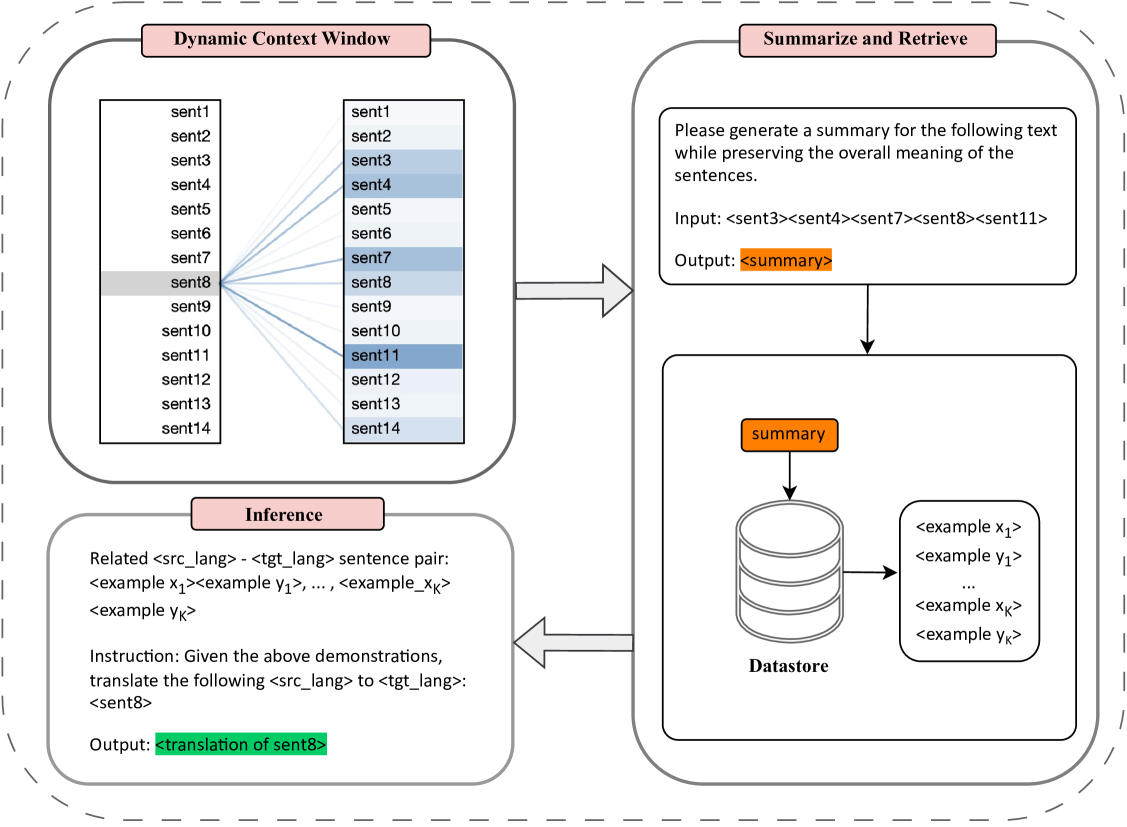
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
0
0
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
6/12/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024
💬
A Paradigm Shift: The Future of Machine Translation Lies with Large Language Models
Chenyang Lyu, Zefeng Du, Jitao Xu, Yitao Duan, Minghao Wu, Teresa Lynn, Alham Fikri Aji, Derek F. Wong, Siyou Liu, Longyue Wang
0
0
Machine Translation (MT) has greatly advanced over the years due to the developments in deep neural networks. However, the emergence of Large Language Models (LLMs) like GPT-4 and ChatGPT is introducing a new phase in the MT domain. In this context, we believe that the future of MT is intricately tied to the capabilities of LLMs. These models not only offer vast linguistic understandings but also bring innovative methodologies, such as prompt-based techniques, that have the potential to further elevate MT. In this paper, we provide an overview of the significant enhancements in MT that are influenced by LLMs and advocate for their pivotal role in upcoming MT research and implementations. We highlight several new MT directions, emphasizing the benefits of LLMs in scenarios such as Long-Document Translation, Stylized Translation, and Interactive Translation. Additionally, we address the important concern of privacy in LLM-driven MT and suggest essential privacy-preserving strategies. By showcasing practical instances, we aim to demonstrate the advantages that LLMs offer, particularly in tasks like translating extended documents. We conclude by emphasizing the critical role of LLMs in guiding the future evolution of MT and offer a roadmap for future exploration in the sector.
4/3/2024