EgoChoir: Capturing 3D Human-Object Interaction Regions from Egocentric Views
2405.13659
0
0
❗
Abstract
Understanding egocentric human-object interaction (HOI) is a fundamental aspect of human-centric perception, facilitating applications like AR/VR and embodied AI. For the egocentric HOI, in addition to perceiving semantics e.g., ''what'' interaction is occurring, capturing ''where'' the interaction specifically manifests in 3D space is also crucial, which links the perception and operation. Existing methods primarily leverage observations of HOI to capture interaction regions from an exocentric view. However, incomplete observations of interacting parties in the egocentric view introduce ambiguity between visual observations and interaction contents, impairing their efficacy. From the egocentric view, humans integrate the visual cortex, cerebellum, and brain to internalize their intentions and interaction concepts of objects, allowing for the pre-formulation of interactions and making behaviors even when interaction regions are out of sight. In light of this, we propose harmonizing the visual appearance, head motion, and 3D object to excavate the object interaction concept and subject intention, jointly inferring 3D human contact and object affordance from egocentric videos. To achieve this, we present EgoChoir, which links object structures with interaction contexts inherent in appearance and head motion to reveal object affordance, further utilizing it to model human contact. Additionally, a gradient modulation is employed to adopt appropriate clues for capturing interaction regions across various egocentric scenarios. Moreover, 3D contact and affordance are annotated for egocentric videos collected from Ego-Exo4D and GIMO to support the task. Extensive experiments on them demonstrate the effectiveness and superiority of EgoChoir. Code and data will be open.
Create account to get full access
Overview
- Explores egocentric human-object interaction (HOI) for applications in AR/VR and embodied AI
- Proposes a method called EgoChoir to jointly infer 3D human contact and object affordance from egocentric videos
- Leverages visual appearance, head motion, and 3D object information to excavate object interaction concepts and subject intentions
Plain English Explanation
When we interact with objects in the world, we don't just see what the object is, but also how we can use it. This research looks at understanding these interactions from the perspective of someone wearing a camera, known as the "egocentric" view.
Normally, methods try to understand interactions by observing them from the outside, but this can be ambiguous when parts of the interaction are out of view. However, humans are able to anticipate how they will interact with objects even when they can't see the full interaction.
The proposed EgoChoir method tries to mimic this human ability by looking at the object's visual appearance, the person's head movements, and the 3D structure of the object. By combining these cues, it can figure out how the person intends to interact with the object, even if the full interaction isn't visible.
This allows EgoChoir to model both the 3D region where the person will make contact with the object, as well as the "affordances" of the object - the ways it can be used. Having this information is useful for applications like augmented reality, virtual reality, and AI systems that need to understand human-object interactions.
Technical Explanation
The key innovation of EgoChoir is that it jointly models 3D human contact and object affordances from egocentric video data. Rather than relying solely on visual observations of the interaction, it also leverages the person's head motions and the 3D structure of the objects to infer the underlying interaction concepts and intentions.
The architecture consists of several components:
- Visual Appearance Modeling: Processes the visual appearance of the objects to understand their affordances
- Head Motion Modeling: Analyzes the person's head movements to infer their intentions and interaction plans
- 3D Object Modeling: Captures the 3D geometric properties of the objects
These three streams of information are then combined to predict the 3D regions where the person will make contact with the object, as well as the affordances of the object. A gradient modulation technique is used to adaptively weight the different cues based on the egocentric scenario.
The method is trained and evaluated on two new datasets: Ego-Exo4D and GIMO, which provide 3D annotations of human-object contacts and object affordances from the egocentric perspective. Experiments demonstrate the effectiveness of EgoChoir compared to previous methods.
Critical Analysis
One potential limitation of this research is the reliance on 3D annotations, which can be time-consuming and expensive to obtain. The authors mention plans to open-source the code and data, which will help facilitate further research in this area.
Additionally, the experiments were conducted on relatively controlled, pre-recorded egocentric videos. It would be valuable to see how well the method generalizes to more naturalistic, real-world egocentric interactions, such as those captured in retrieval-augmented egocentric video captioning or 3D human pose perception from egocentric stereo tasks.
Overall, this research represents an important step forward in understanding egocentric human-object interactions, with promising applications in AR/VR and embodied AI. The EgoChoir method provides a novel approach to jointly modeling 3D contact and affordances, which could inspire further innovations in this area.
Conclusion
This paper introduces EgoChoir, a method for jointly inferring 3D human contact and object affordances from egocentric video data. By harmonizing visual appearance, head motion, and 3D object information, EgoChoir is able to better excavate the underlying interaction concepts and intentions, overcoming the limitations of previous approaches that relied solely on visual observations.
The open-sourcing of the code and data, as well as the potential for real-world applications in AR/VR and embodied AI, make this research a valuable contribution to the field of egocentric human-object interaction understanding. As the technology continues to evolve, methods like EgoChoir will play an important role in bridging the gap between human and machine perception of the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?
Boshen Xu, Ziheng Wang, Yang Du, Zhinan Song, Sipeng Zheng, Qin Jin
0
0
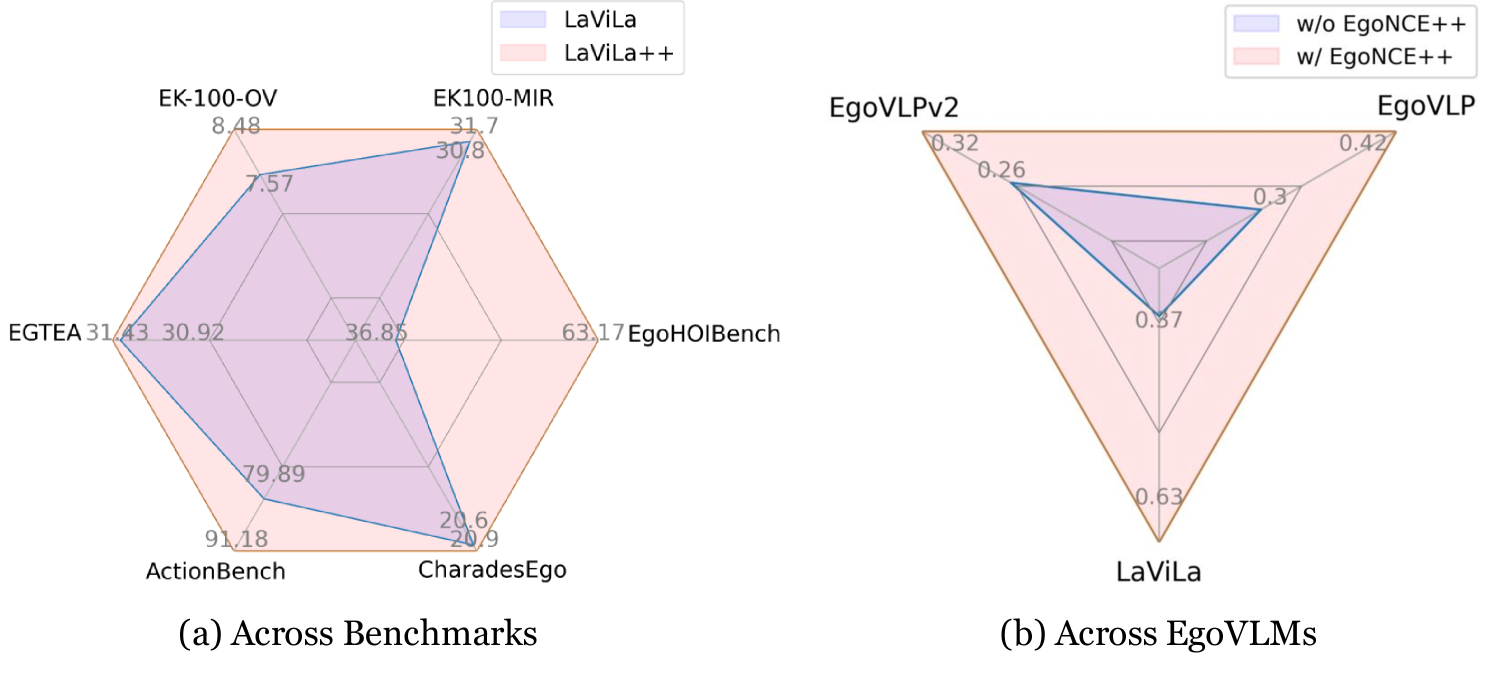
Egocentric video-language pretraining is a crucial paradigm to advance the learning of egocentric hand-object interactions (EgoHOI). Despite the great success on existing testbeds, these benchmarks focus more on closed-set visual concepts or limited scenarios. Due to the occurrence of diverse EgoHOIs in the real world, we propose an open-vocabulary benchmark named EgoHOIBench to reveal the diminished performance of current egocentric video-language models (EgoVLM) on fined-grained concepts, indicating that these models still lack a full spectrum of egocentric understanding. We attribute this performance gap to insufficient fine-grained supervision and strong bias towards understanding objects rather than temporal dynamics in current methods. To tackle these issues, we introduce a novel asymmetric contrastive objective for EgoHOI named EgoNCE++. For video-to-text loss, we enhance text supervision through the generation of negative captions by leveraging the in-context learning of large language models to perform HOI-related word substitution. For text-to-video loss, we propose an object-centric positive video sampling strategy that aggregates video representations by the same nouns. Our extensive experiments demonstrate that EgoNCE++ significantly boosts open-vocabulary HOI recognition, multi-instance retrieval, and action recognition tasks across various egocentric models, with improvements of up to +26.55%. Our code is available at https://github.com/xuboshen/EgoNCEpp.
6/4/2024
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation
Christian Diller, Angela Dai
0
0
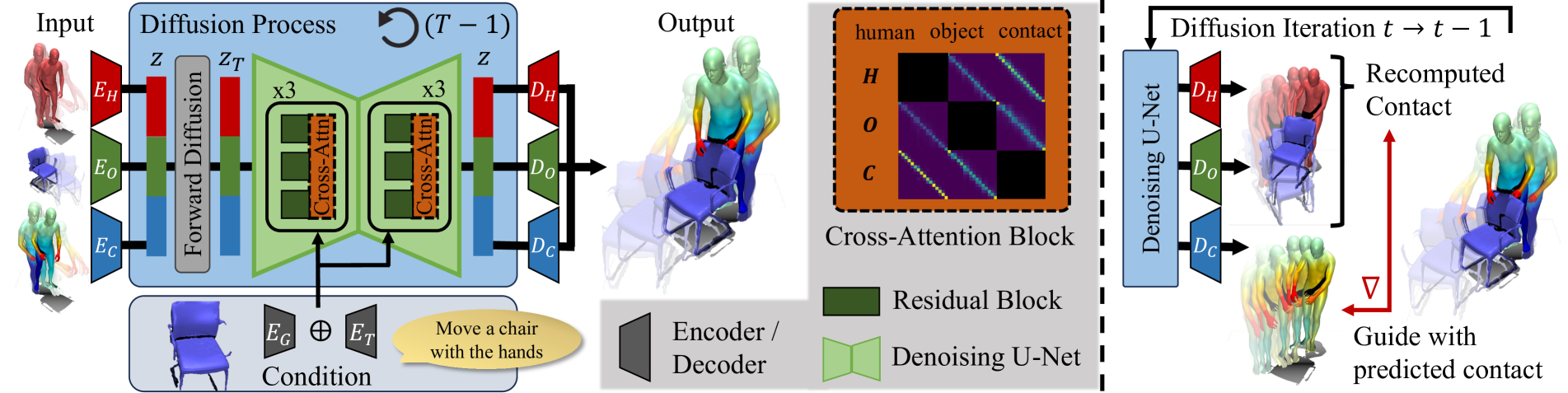
We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text. We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions. Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to bridge human and object motion enables generating more realistic and physically plausible interaction sequences, where the human body and corresponding object move in a coherent manner. Our method first learns to model human motion, object motion, and contact in a joint diffusion process, inter-correlated through cross-attention. We then leverage this learned contact for guidance during inference to synthesize realistic and coherent HOIs. Extensive evaluation shows that our joint contact-based human-object interaction approach generates realistic and physically plausible sequences, and we show two applications highlighting the capabilities of our method. Conditioned on a given object trajectory, we can generate the corresponding human motion without re-training, demonstrating strong human-object interdependency learning. Our approach is also flexible, and can be applied to static real-world 3D scene scans.
5/20/2024

HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision
Siddhant Bansal, Michael Wray, Dima Damen
0
0
Large Vision Language Models (VLMs) are now the de facto state-of-the-art for a number of tasks including visual question answering, recognising objects, and spatial referral. In this work, we propose the HOI-Ref task for egocentric images that aims to understand interactions between hands and objects using VLMs. To enable HOI-Ref, we curate the HOI-QA dataset that consists of 3.9M question-answer pairs for training and evaluating VLMs. HOI-QA includes questions relating to locating hands, objects, and critically their interactions (e.g. referring to the object being manipulated by the hand). We train the first VLM for HOI-Ref on this dataset and call it VLM4HOI. Our results demonstrate that VLMs trained for referral on third person images fail to recognise and refer hands and objects in egocentric images. When fine-tuned on our egocentric HOI-QA dataset, performance improves by 27.9% for referring hands and objects, and by 26.7% for referring interactions.
4/16/2024

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024