EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?
2405.17719
0
0
Abstract
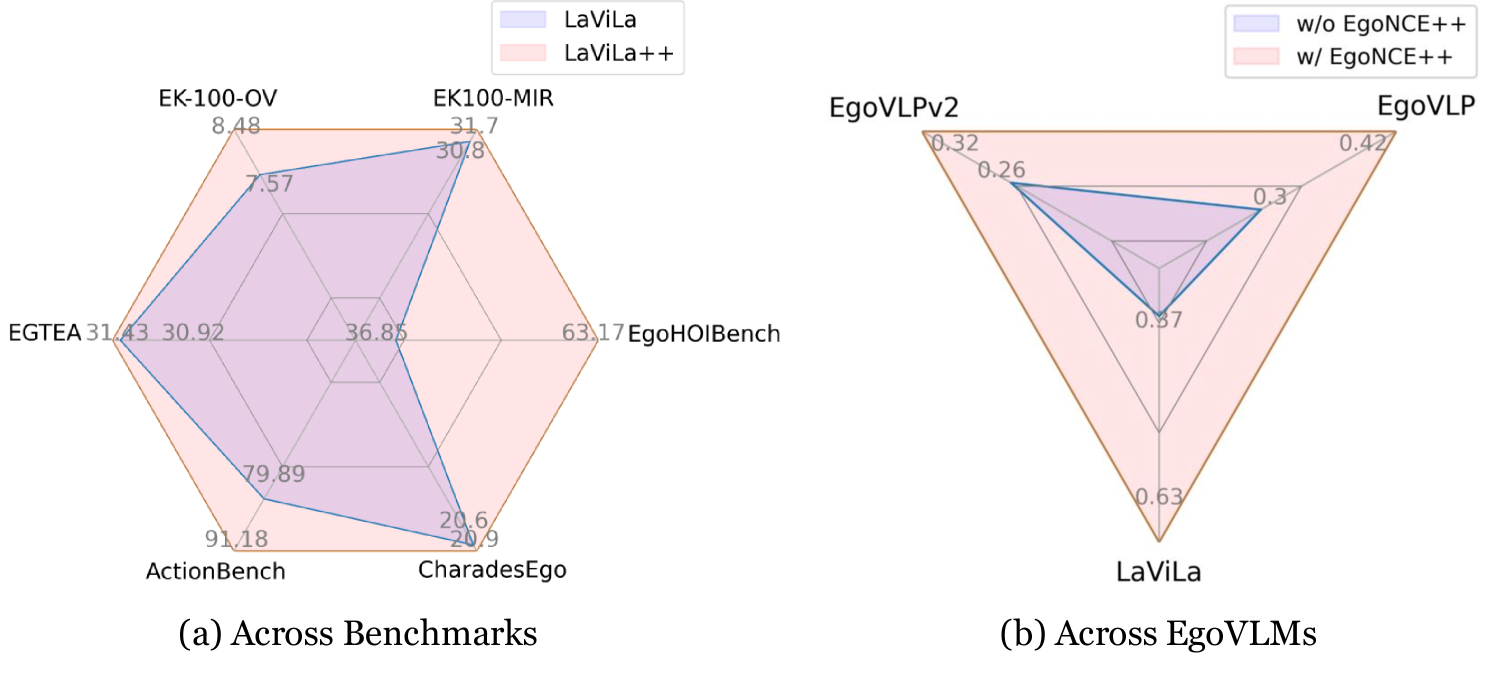
Egocentric video-language pretraining is a crucial paradigm to advance the learning of egocentric hand-object interactions (EgoHOI). Despite the great success on existing testbeds, these benchmarks focus more on closed-set visual concepts or limited scenarios. Due to the occurrence of diverse EgoHOIs in the real world, we propose an open-vocabulary benchmark named EgoHOIBench to reveal the diminished performance of current egocentric video-language models (EgoVLM) on fined-grained concepts, indicating that these models still lack a full spectrum of egocentric understanding. We attribute this performance gap to insufficient fine-grained supervision and strong bias towards understanding objects rather than temporal dynamics in current methods. To tackle these issues, we introduce a novel asymmetric contrastive objective for EgoHOI named EgoNCE++. For video-to-text loss, we enhance text supervision through the generation of negative captions by leveraging the in-context learning of large language models to perform HOI-related word substitution. For text-to-video loss, we propose an object-centric positive video sampling strategy that aggregates video representations by the same nouns. Our extensive experiments demonstrate that EgoNCE++ significantly boosts open-vocabulary HOI recognition, multi-instance retrieval, and action recognition tasks across various egocentric models, with improvements of up to +26.55%. Our code is available at https://github.com/xuboshen/EgoNCEpp.
Create account to get full access
Overview
- This paper, titled "EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?", examines the ability of egocentric video-language models to understand and reason about hand-object interactions.
- The researchers investigate whether these models can accurately localize and describe hand-object interactions in first-person (egocentric) video data.
- The paper introduces a new dataset, EgoNCE++, which builds upon previous egocentric datasets to provide a more comprehensive evaluation of hand-object interaction understanding.
Plain English Explanation
The paper explores whether AI models that are trained on videos and language can truly understand the interactions between hands and objects in first-person (or "egocentric") videos. These models are trained on large datasets of videos and text, and they are designed to be able to describe what's happening in new videos using natural language.
The researchers wanted to see if these models can accurately identify and describe the specific ways that hands are interacting with objects in the videos, such as grasping, touching, or manipulating them. To do this, they created a new dataset called EgoNCE++, which has more detailed information about hand-object interactions than previous datasets.
By testing the AI models on this new dataset, the researchers can evaluate whether the models truly understand the nuances of how hands and objects interact, or if they are just making educated guesses based on patterns in the training data. This could help us understand the limitations of current video-language AI systems and identify areas for improvement.
Technical Explanation
The paper introduces the EgoNCE++ dataset, which builds upon previous egocentric datasets like EgoNCE and EgoChair. EgoNCE++ provides more detailed annotations for hand-object interactions, including the specific types of interactions (e.g. grasping, touching) and the spatial extents of the hands and objects.
The researchers then evaluate several state-of-the-art video-language models, including CLIP and GPT4Ego, on their ability to localize and describe the hand-object interactions in the EgoNCE++ dataset. They analyze the models' performance on tasks like hand-object interaction detection, interaction type classification, and referring expression generation.
The results suggest that while these models show some ability to reason about hand-object interactions, they still struggle with more fine-grained understanding and localization of these interactions. The paper identifies several limitations of the current models and discusses directions for future research to improve their hand-object interaction understanding.
Critical Analysis
The paper provides a thorough evaluation of state-of-the-art video-language models on the task of understanding hand-object interactions in egocentric video. The introduction of the EgoNCE++ dataset is a valuable contribution, as it allows for a more comprehensive assessment of these models' capabilities in this domain.
One limitation noted in the paper is that the EgoNCE++ dataset, while more detailed than previous datasets, still may not capture the full complexity of real-world hand-object interactions. The researchers acknowledge that further dataset expansion and diversification may be needed to fully test the models' understanding.
Additionally, the paper raises the question of whether current video-language models are truly learning to reason about the underlying physical and semantic relationships between hands and objects, or if they are mainly relying on statistical patterns in the training data. Addressing this challenge will be an important area for future research.
The paper also highlights the need for more robust evaluation metrics that can better capture the nuances of hand-object interaction understanding. The metrics used in this study, while informative, may not fully reflect the models' true capabilities.
Overall, this paper makes a valuable contribution to the understanding of video-language models' abilities and limitations in the context of hand-object interactions. The insights provided can help guide future research and development in this important area of AI.
Conclusion
The paper "EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?" investigates the extent to which current video-language models can accurately localize and describe hand-object interactions in egocentric video data.
The introduction of the EgoNCE++ dataset, with its more detailed annotations, allows for a more comprehensive evaluation of these models' capabilities in this domain. The results suggest that while the models show some ability to reason about hand-object interactions, they still struggle with more fine-grained understanding and localization.
The paper identifies several directions for future research, including further dataset expansion, the development of more robust evaluation metrics, and the exploration of techniques to help models better learn the underlying physical and semantic relationships between hands and objects. Addressing these challenges can lead to significant advancements in the field of video-language understanding and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision
Siddhant Bansal, Michael Wray, Dima Damen
0
0
Large Vision Language Models (VLMs) are now the de facto state-of-the-art for a number of tasks including visual question answering, recognising objects, and spatial referral. In this work, we propose the HOI-Ref task for egocentric images that aims to understand interactions between hands and objects using VLMs. To enable HOI-Ref, we curate the HOI-QA dataset that consists of 3.9M question-answer pairs for training and evaluating VLMs. HOI-QA includes questions relating to locating hands, objects, and critically their interactions (e.g. referring to the object being manipulated by the hand). We train the first VLM for HOI-Ref on this dataset and call it VLM4HOI. Our results demonstrate that VLMs trained for referral on third person images fail to recognise and refer hands and objects in egocentric images. When fine-tuned on our egocentric HOI-QA dataset, performance improves by 27.9% for referring hands and objects, and by 26.7% for referring interactions.
4/16/2024

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024
❗
EgoChoir: Capturing 3D Human-Object Interaction Regions from Egocentric Views
Yuhang Yang, Wei Zhai, Chengfeng Wang, Chengjun Yu, Yang Cao, Zheng-Jun Zha
0
0
Understanding egocentric human-object interaction (HOI) is a fundamental aspect of human-centric perception, facilitating applications like AR/VR and embodied AI. For the egocentric HOI, in addition to perceiving semantics e.g., ''what'' interaction is occurring, capturing ''where'' the interaction specifically manifests in 3D space is also crucial, which links the perception and operation. Existing methods primarily leverage observations of HOI to capture interaction regions from an exocentric view. However, incomplete observations of interacting parties in the egocentric view introduce ambiguity between visual observations and interaction contents, impairing their efficacy. From the egocentric view, humans integrate the visual cortex, cerebellum, and brain to internalize their intentions and interaction concepts of objects, allowing for the pre-formulation of interactions and making behaviors even when interaction regions are out of sight. In light of this, we propose harmonizing the visual appearance, head motion, and 3D object to excavate the object interaction concept and subject intention, jointly inferring 3D human contact and object affordance from egocentric videos. To achieve this, we present EgoChoir, which links object structures with interaction contexts inherent in appearance and head motion to reveal object affordance, further utilizing it to model human contact. Additionally, a gradient modulation is employed to adopt appropriate clues for capturing interaction regions across various egocentric scenarios. Moreover, 3D contact and affordance are annotated for egocentric videos collected from Ego-Exo4D and GIMO to support the task. Extensive experiments on them demonstrate the effectiveness and superiority of EgoChoir. Code and data will be open.
5/24/2024
📈
EgoVideo: Exploring Egocentric Foundation Model and Downstream Adaptation
Baoqi Pei, Guo Chen, Jilan Xu, Yuping He, Yicheng Liu, Kanghua Pan, Yifei Huang, Yali Wang, Tong Lu, Limin Wang, Yu Qiao
0
0
In this report, we present our solutions to the EgoVis Challenges in CVPR 2024, including five tracks in the Ego4D challenge and three tracks in the EPIC-Kitchens challenge. Building upon the video-language two-tower model and leveraging our meticulously organized egocentric video data, we introduce a novel foundation model called EgoVideo. This model is specifically designed to cater to the unique characteristics of egocentric videos and provides strong support for our competition submissions. In the Ego4D challenges, we tackle various tasks including Natural Language Queries, Step Grounding, Moment Queries, Short-term Object Interaction Anticipation, and Long-term Action Anticipation. In addition, we also participate in the EPIC-Kitchens challenge, where we engage in the Action Recognition, Multiple Instance Retrieval, and Domain Adaptation for Action Recognition tracks. By adapting EgoVideo to these diverse tasks, we showcase its versatility and effectiveness in different egocentric video analysis scenarios, demonstrating the powerful representation ability of EgoVideo as an egocentric foundation model. Our codebase and pretrained models are publicly available at https://github.com/OpenGVLab/EgoVideo.
7/1/2024