EGTR: Extracting Graph from Transformer for Scene Graph Generation

0

Sign in to get full access
Overview
- The paper proposes a new method called EGTR (Extracting Graph from Transformer) for generating scene graphs from images.
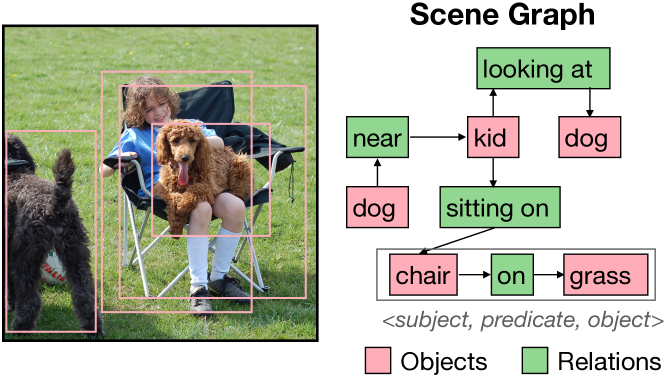
- Scene graphs are visual representations that capture the objects, their attributes, and the relationships between them in an image.
- EGTR leverages the power of transformer models to extract graph-structured information directly from the image without requiring additional post-processing steps.
Plain English Explanation
EGTR is a novel approach to generating scene graphs, which are visual diagrams that show the objects, their properties, and how they are connected in an image. Traditional methods usually require multiple steps to first detect the objects, then classify their attributes, and finally determine the relationships between them. EGTR streamlines this process by using a transformer model - a type of neural network that excels at understanding complex patterns - to extract the graph-structured information directly from the image in a single step.
The key innovation of EGTR is that it can learn to represent the scene graph as a set of interconnected nodes and edges, without needing to first segment the image into individual objects. This allows the model to capture the holistic structure of the scene more effectively. By using a transformer architecture, EGTR can also better understand the contextual relationships between different elements in the image, leading to more accurate and comprehensive scene graph generation.
Technical Explanation
The EGTR model consists of a transformer encoder that takes an image as input and produces a set of feature representations. These features are then passed through a graph decoder module that predicts the nodes (objects) and edges (relationships) of the scene graph.
The graph decoder uses a novel attention mechanism to directly extract the graph structure from the image features. It learns to attend to the relevant parts of the image to identify the objects and their relationships, without requiring an explicit object detection step. This end-to-end approach allows EGTR to generate scene graphs more efficiently compared to previous methods that relied on multiple sequential processing stages.
The authors evaluate EGTR on several benchmark scene graph generation datasets and show that it outperforms state-of-the-art approaches in terms of accuracy and inference speed. They also provide detailed ablation studies to understand the contribution of different components of the model.
Critical Analysis
The paper provides a compelling technical solution to the challenge of scene graph generation. By directly extracting the graph structure from the visual features, EGTR avoids the need for complex post-processing pipelines required by previous methods. This streamlining of the process leads to efficiency gains in both accuracy and inference time.
However, the authors do acknowledge several limitations of the current EGTR approach. For instance, the model may struggle to handle complex occlusions or rare object-relationship combinations that are not well represented in the training data. Additionally, the paper does not explore the model's robustness to noisy or adversarial inputs, which would be an important consideration for real-world deployment.
Further research could also investigate the interpretability of the EGTR model's internal representations and decision-making process. Understanding how the transformer encoder and graph decoder modules collaborate to extract the scene graph structure could lead to additional insights and potential improvements.
Conclusion
The EGTR method represents a significant advancement in the field of scene graph generation. By leveraging the power of transformer models, the authors have developed a streamlined approach that can directly extract rich, graph-structured representations from images. This innovation has the potential to enable more efficient and accurate visual understanding systems, with applications in areas such as image captioning, visual question answering, and robotic perception.
As the authors continue to refine and expand upon the EGTR framework, it will be exciting to see how this research can further push the boundaries of what is possible in the realm of scene understanding and visual reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EGTR: Extracting Graph from Transformer for Scene Graph Generation
Jinbae Im, JeongYeon Nam, Nokyung Park, Hyungmin Lee, Seunghyun Park
Scene Graph Generation (SGG) is a challenging task of detecting objects and predicting relationships between objects. After DETR was developed, one-stage SGG models based on a one-stage object detector have been actively studied. However, complex modeling is used to predict the relationship between objects, and the inherent relationship between object queries learned in the multi-head self-attention of the object detector has been neglected. We propose a lightweight one-stage SGG model that extracts the relation graph from the various relationships learned in the multi-head self-attention layers of the DETR decoder. By fully utilizing the self-attention by-products, the relation graph can be extracted effectively with a shallow relation extraction head. Considering the dependency of the relation extraction task on the object detection task, we propose a novel relation smoothing technique that adjusts the relation label adaptively according to the quality of the detected objects. By the relation smoothing, the model is trained according to the continuous curriculum that focuses on object detection task at the beginning of training and performs multi-task learning as the object detection performance gradually improves. Furthermore, we propose a connectivity prediction task that predicts whether a relation exists between object pairs as an auxiliary task of the relation extraction. We demonstrate the effectiveness and efficiency of our method for the Visual Genome and Open Image V6 datasets. Our code is publicly available at https://github.com/naver-ai/egtr.
Read more6/26/2024

0
Leveraging Predicate and Triplet Learning for Scene Graph Generation
Jiankai Li, Yunhong Wang, Xiefan Guo, Ruijie Yang, Weixin Li
Scene Graph Generation (SGG) aims to identify entities and predict the relationship triplets textit{textless subject, predicate, objecttextgreater } in visual scenes. Given the prevalence of large visual variations of subject-object pairs even in the same predicate, it can be quite challenging to model and refine predicate representations directly across such pairs, which is however a common strategy adopted by most existing SGG methods. We observe that visual variations within the identical triplet are relatively small and certain relation cues are shared in the same type of triplet, which can potentially facilitate the relation learning in SGG. Moreover, for the long-tail problem widely studied in SGG task, it is also crucial to deal with the limited types and quantity of triplets in tail predicates. Accordingly, in this paper, we propose a Dual-granularity Relation Modeling (DRM) network to leverage fine-grained triplet cues besides the coarse-grained predicate ones. DRM utilizes contexts and semantics of predicate and triplet with Dual-granularity Constraints, generating compact and balanced representations from two perspectives to facilitate relation recognition. Furthermore, a Dual-granularity Knowledge Transfer (DKT) strategy is introduced to transfer variation from head predicates/triplets to tail ones, aiming to enrich the pattern diversity of tail classes to alleviate the long-tail problem. Extensive experiments demonstrate the effectiveness of our method, which establishes new state-of-the-art performance on Visual Genome, Open Image, and GQA datasets. Our code is available at url{https://github.com/jkli1998/DRM}
Read more6/5/2024
0
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Naitik Khandelwal, Xiao Liu, Mengmi Zhang
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Read more4/15/2024

0
Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection
Tim Salzmann, Markus Ryll, Alex Bewley, Matthias Minderer
Visual relationship detection aims to identify objects and their relationships in images. Prior methods approach this task by adding separate relationship modules or decoders to existing object detection architectures. This separation increases complexity and hinders end-to-end training, which limits performance. We propose a simple and highly efficient decoder-free architecture for open-vocabulary visual relationship detection. Our model consists of a Transformer-based image encoder that represents objects as tokens and models their relationships implicitly. To extract relationship information, we introduce an attention mechanism that selects object pairs likely to form a relationship. We provide a single-stage recipe to train this model on a mixture of object and relationship detection data. Our approach achieves state-of-the-art relationship detection performance on Visual Genome and on the large-vocabulary GQA benchmark at real-time inference speeds. We provide ablations, real-world qualitative examples, and analyses of zero-shot performance.
Read more7/22/2024