Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection

0

Sign in to get full access
Overview
- The provided paper presents a novel approach for detecting relationships between objects in images.
- The key idea is to utilize a detector-agnostic relationship detection model that can work with any underlying object detection system.
- The model leverages contextual information and learns to capture inter-object relationships in a flexible, generalizable manner.
- Experiments demonstrate the effectiveness of the proposed approach on various benchmarks, outperforming existing methods.
Plain English Explanation
The paper tackles the challenge of detecting relationships between objects in images. For example, if an image shows a person sitting on a chair, the system should be able to recognize that the "person" and "chair" objects are related in a "sitting on" relationship.
The researchers developed a novel model that can work with any underlying object detection system. This "detector-agnostic" approach means the relationship detection model is flexible and can be used with different object detectors, rather than being tied to a specific one.
The key innovation is that the model learns to capture the contextual information around objects, such as their positions, sizes, and visual features. By understanding this context, the model can infer the relationships between the detected objects, even if it hasn't seen those exact objects and relationships before.
Through experiments on various benchmarks, the researchers show that their approach outperforms existing methods for detecting object relationships. This suggests the model is able to learn generalizable patterns and apply them effectively to new scenarios.
Technical Explanation
The paper introduces a detector-agnostic relationship detection model that can work with any underlying object detection system. The key idea is to leverage the contextual information around detected objects, such as their positions, sizes, and visual features, to infer the relationships between them.
The model consists of a context encoder that learns to represent the contextual information for each object, and a relationship classifier that uses these representations to predict the relationships between pairs of objects.
The context encoder is implemented as a neural network that takes in the visual features of an object, as well as its spatial coordinates and size, and outputs a compact representation capturing the relevant contextual information. The relationship classifier is another neural network that takes the context representations of two objects and predicts the relationship between them.
The model is trained end-to-end on a dataset of images annotated with object bounding boxes and relationship labels. During inference, the model can be used with any object detection system to predict the relationships between the detected objects.
Experiments on various benchmarks show that the proposed detector-agnostic relationship detection model outperforms existing methods, demonstrating its ability to learn generalizable patterns and apply them effectively to new scenarios.
Critical Analysis
The paper presents a compelling approach to relationship detection that addresses some of the limitations of previous methods. By utilizing a detector-agnostic model, the researchers ensure their solution is flexible and can be easily integrated with different object detection systems.
One potential caveat is that the model's performance may still depend on the quality of the underlying object detection system. If the object detection is poor, the relationship detection may also suffer. The paper does not discuss the model's robustness to noisy or incomplete object detections.
Additionally, the paper focuses on pairwise relationships between objects, but real-world scenes often involve more complex, higher-order relationships (e.g., "person sitting on chair next to table"). Extending the model to handle these richer, contextual relationships could be an interesting direction for future research.
Overall, the paper presents a thoughtful and well-executed approach to detector-agnostic relationship detection. The strong experimental results suggest the model's potential for practical applications in areas like scene understanding and image captioning.
Conclusion
The presented paper introduces a novel detector-agnostic relationship detection model that can effectively capture the contextual relationships between objects in images. By learning to represent and leverage the contextual information around detected objects, the model is able to infer relationships in a flexible and generalizable manner.
The key contributions of this work are the detector-agnostic approach, the novel context encoder and relationship classifier architectures, and the strong experimental results demonstrating the model's effectiveness on various benchmarks.
This research has the potential to significantly impact applications that rely on scene understanding, such as image captioning, visual question answering, and robotic perception. Further exploring extensions to handle more complex, contextual relationships could be a promising direction for future work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection
Tim Salzmann, Markus Ryll, Alex Bewley, Matthias Minderer
Visual relationship detection aims to identify objects and their relationships in images. Prior methods approach this task by adding separate relationship modules or decoders to existing object detection architectures. This separation increases complexity and hinders end-to-end training, which limits performance. We propose a simple and highly efficient decoder-free architecture for open-vocabulary visual relationship detection. Our model consists of a Transformer-based image encoder that represents objects as tokens and models their relationships implicitly. To extract relationship information, we introduce an attention mechanism that selects object pairs likely to form a relationship. We provide a single-stage recipe to train this model on a mixture of object and relationship detection data. Our approach achieves state-of-the-art relationship detection performance on Visual Genome and on the large-vocabulary GQA benchmark at real-time inference speeds. We provide ablations, real-world qualitative examples, and analyses of zero-shot performance.
Read more7/22/2024

0
Towards Flexible Visual Relationship Segmentation
Fangrui Zhu, Jianwei Yang, Huaizu Jiang
Visual relationship understanding has been studied separately in human-object interaction(HOI) detection, scene graph generation(SGG), and referring relationships(RR) tasks. Given the complexity and interconnectedness of these tasks, it is crucial to have a flexible framework that can effectively address these tasks in a cohesive manner. In this work, we propose FleVRS, a single model that seamlessly integrates the above three aspects in standard and promptable visual relationship segmentation, and further possesses the capability for open-vocabulary segmentation to adapt to novel scenarios. FleVRS leverages the synergy between text and image modalities, to ground various types of relationships from images and use textual features from vision-language models to visual conceptual understanding. Empirical validation across various datasets demonstrates that our framework outperforms existing models in standard, promptable, and open-vocabulary tasks, e.g., +1.9 $mAP$ on HICO-DET, +11.4 $Acc$ on VRD, +4.7 $mAP$ on unseen HICO-DET. Our FleVRS represents a significant step towards a more intuitive, comprehensive, and scalable understanding of visual relationships.
Read more8/16/2024

0
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Botao Ren, Botian Xu, Yifan Pu, Jingyi Wang, Zhidong Deng
In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
Read more4/8/2024
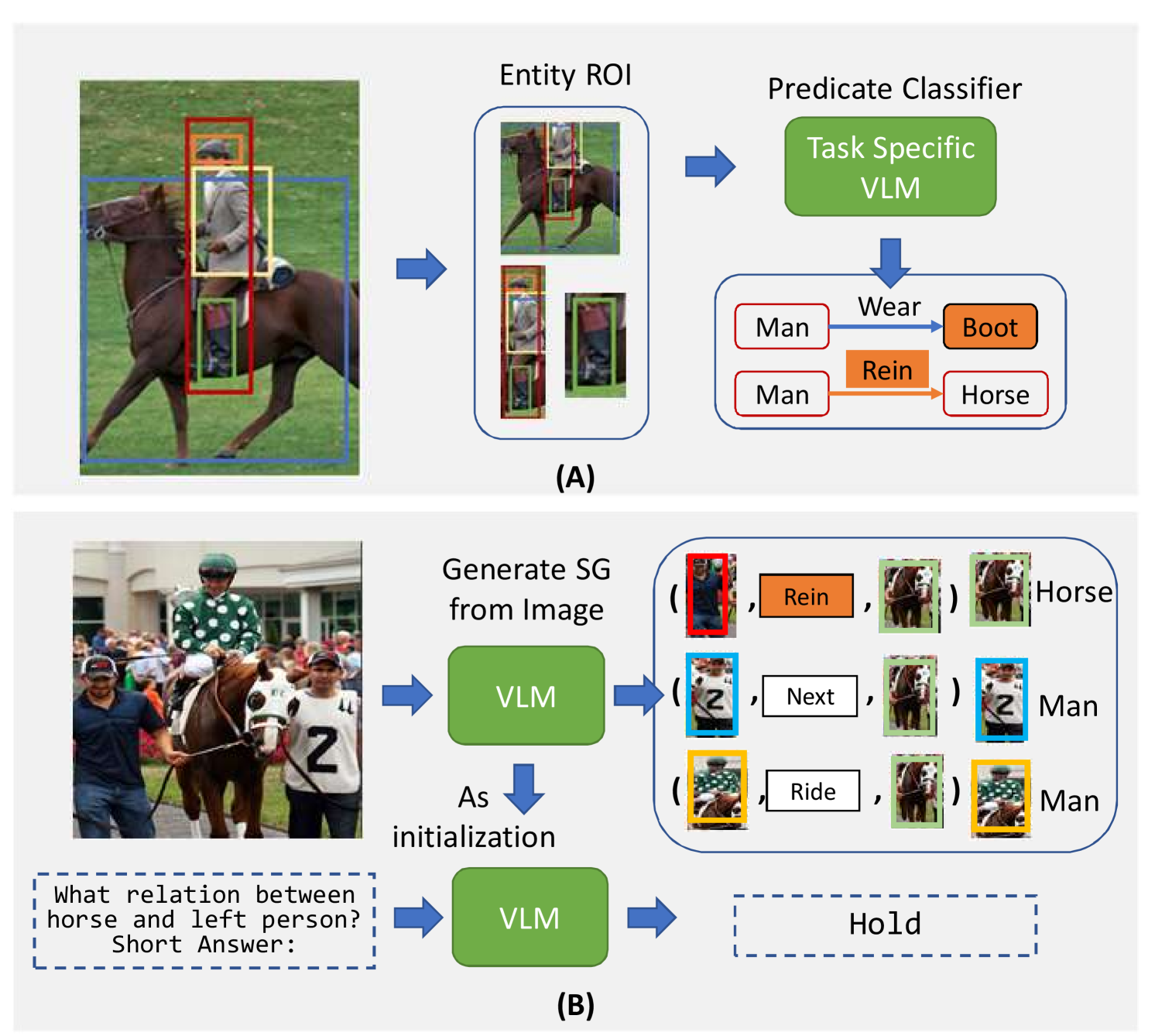
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024