EHRNoteQA: An LLM Benchmark for Real-World Clinical Practice Using Discharge Summaries
2402.16040
0
0

Abstract
Discharge summaries in Electronic Health Records (EHRs) are crucial for clinical decision-making, but their length and complexity make information extraction challenging, especially when dealing with accumulated summaries across multiple patient admissions. Large Language Models (LLMs) show promise in addressing this challenge by efficiently analyzing vast and complex data. Existing benchmarks, however, fall short in properly evaluating LLMs' capabilities in this context, as they typically focus on single-note information or limited topics, failing to reflect the real-world inquiries required by clinicians. To bridge this gap, we introduce EHRNoteQA, a novel benchmark built on the MIMIC-IV EHR, comprising 962 different QA pairs each linked to distinct patients' discharge summaries. Every QA pair is initially generated using GPT-4 and then manually reviewed and refined by three clinicians to ensure clinical relevance. EHRNoteQA includes questions that require information across multiple discharge summaries and covers eight diverse topics, mirroring the complexity and diversity of real clinical inquiries. We offer EHRNoteQA in two formats: open-ended and multi-choice question answering, and propose a reliable evaluation method for each. We evaluate 27 LLMs using EHRNoteQA and examine various factors affecting the model performance (e.g., the length and number of discharge summaries). Furthermore, to validate EHRNoteQA as a reliable proxy for expert evaluations in clinical practice, we measure the correlation between the LLM performance on EHRNoteQA, and the LLM performance manually evaluated by clinicians. Results show that LLM performance on EHRNoteQA have higher correlation with clinician-evaluated performance (Spearman: 0.78, Kendall: 0.62) compared to other benchmarks, demonstrating its practical relevance in evaluating LLMs in clinical settings.
Create account to get full access
Overview
- This paper presents EHRNoteQA, a new benchmark dataset for evaluating how well large language models (LLMs) can answer patient-specific questions based on electronic health record (EHR) notes.
- EHRNoteQA is designed to assess the ability of LLMs to understand and reason about clinical information, which is crucial for their use in healthcare settings.
- The dataset includes over 10,000 question-answer pairs derived from real EHR notes, covering a range of medical topics and patient scenarios.
Plain English Explanation
EHRNoteQA is a new tool that allows researchers to test how well large language models can answer questions about a patient's medical history and condition based on the notes in their electronic health record (EHR). This is important because LLMs have the potential to enhance clinical efficiency and improve patient care, but they need to be able to accurately understand and reason about complex medical information.
The EHRNoteQA dataset includes thousands of sample questions and answers based on real EHR notes, covering a wide range of medical topics and patient scenarios. Researchers can use this dataset to evaluate how well different LLMs perform at answering patient-specific questions, which will help identify the strengths and limitations of these models in a clinical setting. This could lead to improvements in how LLMs are adapted and applied in healthcare.
Technical Explanation
The EHRNoteQA dataset was constructed by collecting real EHR notes from a large healthcare system and crowdsourcing relevant questions and answers based on the information in those notes. The questions cover a variety of medical topics, such as diagnoses, treatments, and patient history, and the answers are drawn directly from the EHR content.
To create the dataset, the researchers first selected a diverse set of EHR notes representing different patient demographics and medical conditions. They then used crowdsourcing to generate high-quality question-answer pairs for each note, ensuring the questions were clinically relevant and the answers could be supported by the information in the note.
The final EHRNoteQA dataset contains over 10,000 question-answer pairs across 1,000 unique EHR notes. The researchers evaluated the performance of several state-of-the-art LLMs on this benchmark and found that while the models performed reasonably well, there is still significant room for improvement, particularly in areas requiring complex reasoning and domain-specific medical knowledge.
Critical Analysis
The EHRNoteQA benchmark represents an important step forward in evaluating the capabilities of large language models in clinical settings. By focusing on patient-specific questions, the dataset challenges LLMs to go beyond simple retrieval of information and demonstrates the need for models to truly understand and reason about medical data.
However, the authors acknowledge several limitations of the dataset. The questions and answers were generated by crowdsourced workers, which may introduce biases or inconsistencies. Additionally, the dataset only includes a subset of EHR notes from a single healthcare system, which may not be representative of the full diversity of clinical documentation.
Future research could explore ways to expand the dataset, either by including more diverse EHR notes or by developing automated methods for generating high-quality question-answer pairs. There is also a need to better understand the specific strengths and weaknesses of different LLM architectures and their suitability for various clinical tasks.
Conclusion
The EHRNoteQA benchmark represents an important advancement in the field of large language model evaluation for healthcare applications. By providing a standardized dataset for assessing how well LLMs can answer patient-specific questions, the authors have created a valuable tool for researchers and developers working to bring these powerful models into clinical settings. While the current results suggest there is still room for improvement, the EHRNoteQA dataset lays the groundwork for continued progress in this critical area of medical AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges
Hiba Ahsan, Denis Jered McInerney, Jisoo Kim, Christopher Potter, Geoffrey Young, Silvio Amir, Byron C. Wallace
0
0
Unstructured data in Electronic Health Records (EHRs) often contains critical information -- complementary to imaging -- that could inform radiologists' diagnoses. But the large volume of notes often associated with patients together with time constraints renders manually identifying relevant evidence practically infeasible. In this work we propose and evaluate a zero-shot strategy for using LLMs as a mechanism to efficiently retrieve and summarize unstructured evidence in patient EHR relevant to a given query. Our method entails tasking an LLM to infer whether a patient has, or is at risk of, a particular condition on the basis of associated notes; if so, we ask the model to summarize the supporting evidence. Under expert evaluation, we find that this LLM-based approach provides outputs consistently preferred to a pre-LLM information retrieval baseline. Manual evaluation is expensive, so we also propose and validate a method using an LLM to evaluate (other) LLM outputs for this task, allowing us to scale up evaluation. Our findings indicate the promise of LLMs as interfaces to EHR, but also highlight the outstanding challenge posed by hallucinations. In this setting, however, we show that model confidence in outputs strongly correlates with faithful summaries, offering a practical means to limit confabulations.
6/12/2024
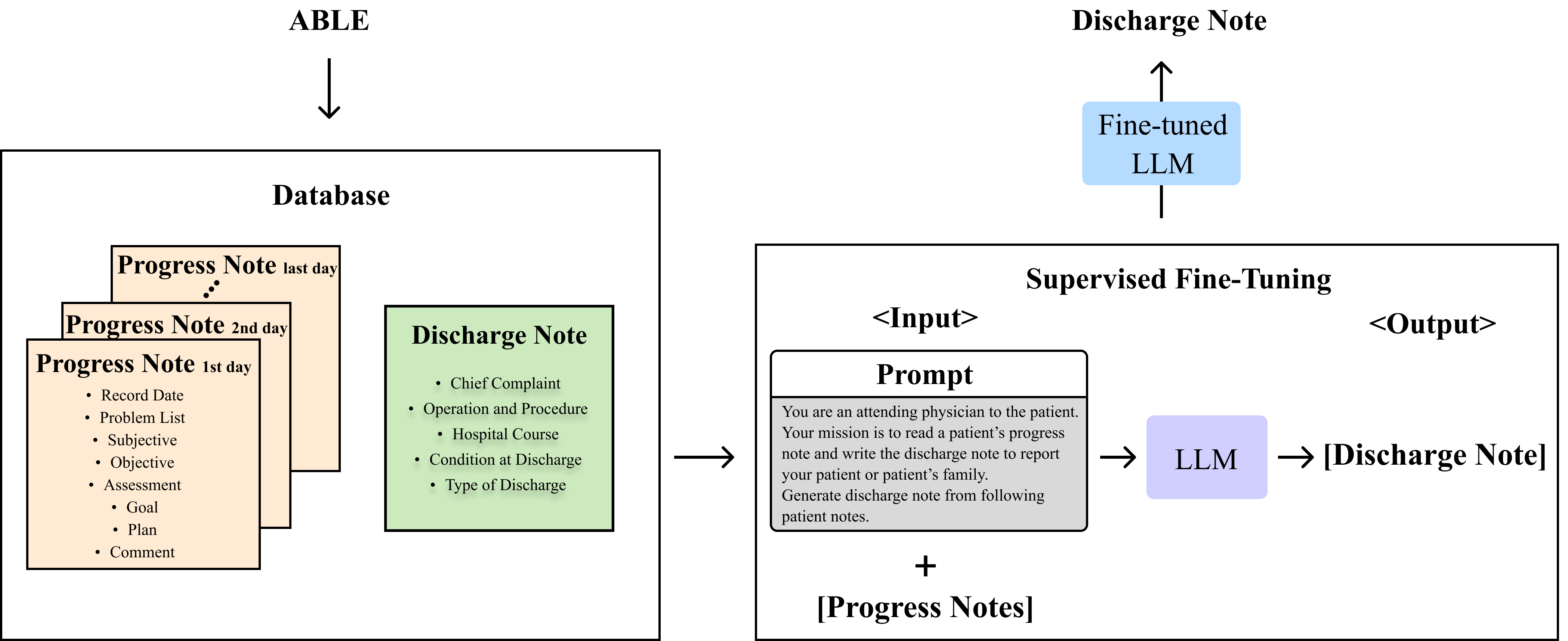
Enhancing Clinical Efficiency through LLM: Discharge Note Generation for Cardiac Patients
HyoJe Jung, Yunha Kim, Heejung Choi, Hyeram Seo, Minkyoung Kim, JiYe Han, Gaeun Kee, Seohyun Park, Soyoung Ko, Byeolhee Kim, Suyeon Kim, Tae Joon Jun, Young-Hak Kim
0
0
Medical documentation, including discharge notes, is crucial for ensuring patient care quality, continuity, and effective medical communication. However, the manual creation of these documents is not only time-consuming but also prone to inconsistencies and potential errors. The automation of this documentation process using artificial intelligence (AI) represents a promising area of innovation in healthcare. This study directly addresses the inefficiencies and inaccuracies in creating discharge notes manually, particularly for cardiac patients, by employing AI techniques, specifically large language model (LLM). Utilizing a substantial dataset from a cardiology center, encompassing wide-ranging medical records and physician assessments, our research evaluates the capability of LLM to enhance the documentation process. Among the various models assessed, Mistral-7B distinguished itself by accurately generating discharge notes that significantly improve both documentation efficiency and the continuity of care for patients. These notes underwent rigorous qualitative evaluation by medical expert, receiving high marks for their clinical relevance, completeness, readability, and contribution to informed decision-making and care planning. Coupled with quantitative analyses, these results confirm Mistral-7B's efficacy in distilling complex medical information into concise, coherent summaries. Overall, our findings illuminate the considerable promise of specialized LLM, such as Mistral-7B, in refining healthcare documentation workflows and advancing patient care. This study lays the groundwork for further integrating advanced AI technologies in healthcare, demonstrating their potential to revolutionize patient documentation and support better care outcomes.
4/9/2024
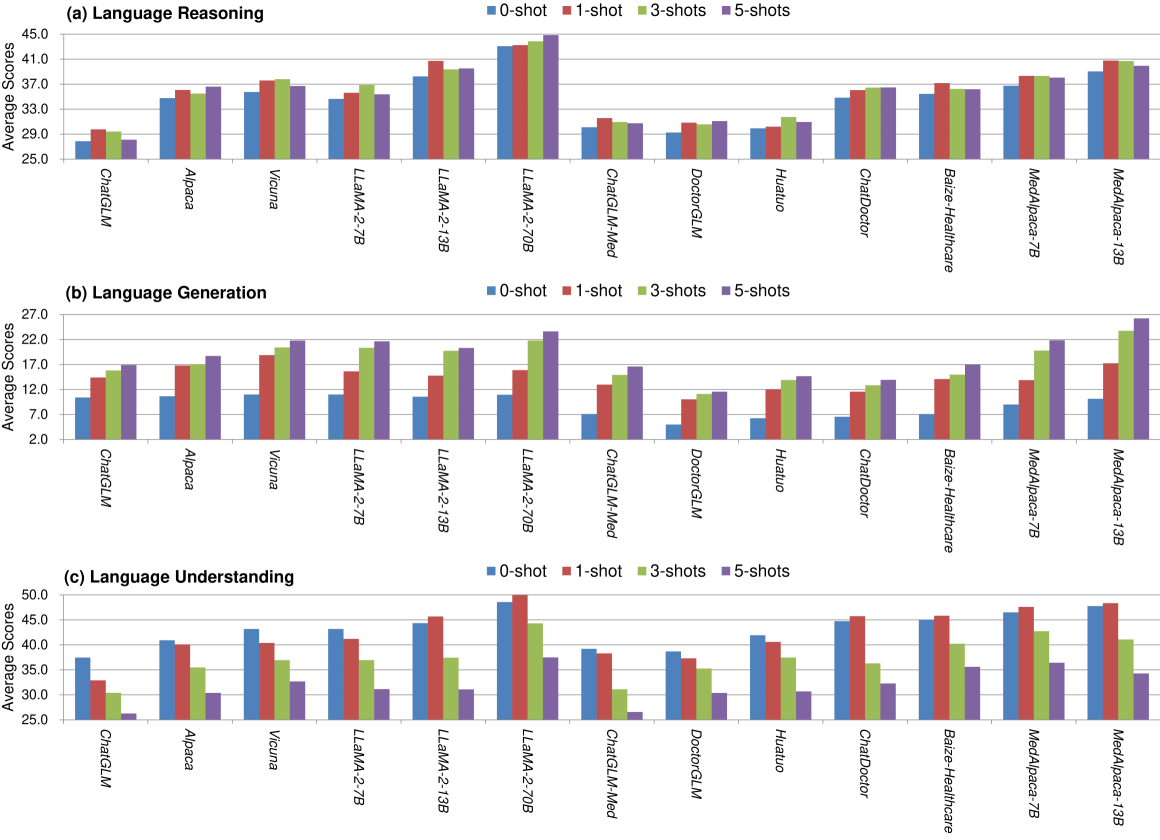
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
6/27/2024
💬
M-QALM: A Benchmark to Assess Clinical Reading Comprehension and Knowledge Recall in Large Language Models via Question Answering
Anand Subramanian, Viktor Schlegel, Abhinav Ramesh Kashyap, Thanh-Tung Nguyen, Vijay Prakash Dwivedi, Stefan Winkler
0
0
There is vivid research on adapting Large Language Models (LLMs) to perform a variety of tasks in high-stakes domains such as healthcare. Despite their popularity, there is a lack of understanding of the extent and contributing factors that allow LLMs to recall relevant knowledge and combine it with presented information in the clinical and biomedical domain: a fundamental pre-requisite for success on down-stream tasks. Addressing this gap, we use Multiple Choice and Abstractive Question Answering to conduct a large-scale empirical study on 22 datasets in three generalist and three specialist biomedical sub-domains. Our multifaceted analysis of the performance of 15 LLMs, further broken down by sub-domain, source of knowledge and model architecture, uncovers success factors such as instruction tuning that lead to improved recall and comprehension. We further show that while recently proposed domain-adapted models may lack adequate knowledge, directly fine-tuning on our collected medical knowledge datasets shows encouraging results, even generalising to unseen specialist sub-domains. We complement the quantitative results with a skill-oriented manual error analysis, which reveals a significant gap between the models' capabilities to simply recall necessary knowledge and to integrate it with the presented context. To foster research and collaboration in this field we share M-QALM, our resources, standardised methodology, and evaluation results, with the research community to facilitate further advancements in clinical knowledge representation learning within language models.
6/7/2024