The Elephant in the Room -- Why AI Safety Demands Diverse Teams

0
🤖
Sign in to get full access
Overview
- The paper discusses the importance of having diverse teams in AI safety research to address potential biases and blind spots.
- It argues that the field of AI alignment has been dominated by a relatively homogeneous group of researchers, which can lead to overlooking critical issues.
- The paper suggests that incorporating diverse perspectives, backgrounds, and experiences is crucial for developing robust and inclusive AI safety strategies.
Plain English Explanation
Building safe and reliable AI systems is a critical challenge facing the technology industry. One key aspect of this challenge is
The authors point out that the field of AI alignment has been dominated by a relatively homogeneous group of researchers with similar backgrounds and perspectives. This raises concerns that important issues and considerations may be overlooked due to shared biases or blind spots within this group.
To address this, the paper emphasizes the need for more pluralistic and diverse perspectives in AI safety research. By bringing together people with different experiences, expertise, and worldviews, the authors believe the community can better identify and mitigate potential misalignments between AI systems and human values.
The authors acknowledge the inherent challenges in achieving this diversity, as the field itself may attract a relatively homogeneous group of researchers. However, they argue that overcoming these challenges is essential for [developing a more comprehensive and holistic approach to AI safety.
Technical Explanation
The paper presents a thoughtful analysis of the role that diversity plays in AI alignment research. The authors begin by highlighting the current state of the field, which they describe as being dominated by a relatively homogeneous group of researchers. They argue that this lack of diversity can lead to significant blind spots and overlooked considerations in the development of AI alignment strategies.
To support this claim, the paper cites previous research on social choice theory and its implications for AI alignment, as well as work on the importance of pluralistic perspectives in this domain. The authors also draw on literature related to quantifying misalignment between AI agents and human values and the inherent challenges of achieving alignment.
Throughout the paper, the authors emphasize the need for a more holistic and comprehensive approach to AI safety, one that incorporates diverse perspectives and experiences. They argue that this diversity is crucial for identifying and addressing potential blind spots, as well as developing robust and inclusive alignment strategies.
Critical Analysis
The paper makes a compelling case for the importance of diversity in AI alignment research, highlighting how a homogeneous group of researchers can lead to the overlooking of critical issues and considerations. The authors' emphasis on the need for pluralistic perspectives and their grounding in relevant literature is a strength of the paper.
However, the authors also acknowledge the inherent challenges in achieving this diversity, as the field itself may attract a relatively homogeneous group of researchers. This raises questions about the practical implementation of their recommendations and the potential barriers that need to be overcome.
Additionally, while the paper discusses the importance of diverse perspectives, it could have delved deeper into the specific types of diversity (e.g., demographic, disciplinary, cultural) that are most critical for AI alignment research. This could have provided more concrete guidance for how to build truly diverse and inclusive research teams.
Furthermore, the paper could have explored potential trade-offs or tensions that may arise when incorporating diverse viewpoints, and how to navigate these effectively. Addressing these nuances could have strengthened the overall analysis and recommendations.
Conclusion
The central argument of this paper - that diversity is essential for robust and inclusive AI safety research - is compelling and well-supported. By highlighting the potential blind spots and biases that can arise from a homogeneous research community, the authors make a strong case for the need to incorporate diverse perspectives, backgrounds, and experiences.
Ultimately, the paper underscores the importance of moving beyond the "elephant in the room" and actively addressing the lack of diversity in AI alignment research. As the field continues to evolve and the stakes of AI safety grow, heeding the authors' call for a more pluralistic approach could be crucial for developing effective and equitable strategies to ensure the responsible development of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
The Elephant in the Room -- Why AI Safety Demands Diverse Teams
David Rostcheck, Lara Scheibling
We consider that existing approaches to AI safety and alignment may not be using the most effective tools, teams, or approaches. We suggest that an alternative and better approach to the problem may be to treat alignment as a social science problem, since the social sciences enjoy a rich toolkit of models for understanding and aligning motivation and behavior, much of which could be repurposed to problems involving AI models, and enumerate reasons why this is so. We introduce an alternate alignment approach informed by social science tools and characterized by three steps: 1. defining a positive desired social outcome for human/AI collaboration as the goal or North Star, 2. properly framing knowns and unknowns, and 3. forming diverse teams to investigate, observe, and navigate emerging challenges in alignment.
Read more7/16/2024
0
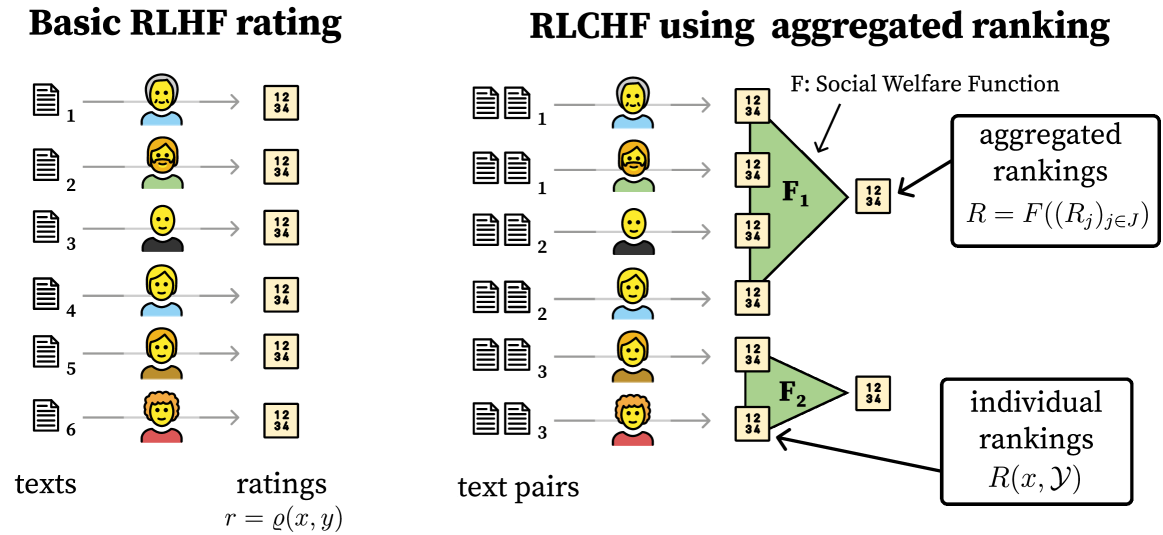
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, such as helping to commit crimes or producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about collective preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Read more6/5/2024
0
Quantifying Misalignment Between Agents
Aidan Kierans, Avijit Ghosh, Hananel Hazan, Shiri Dori-Hacohen
Existing work on the alignment problem has focused mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a monolith. Recent sociotechnical approaches highlight the need to understand complex misalignment among multiple human and AI agents. We address this gap by adapting a computational social science model of human contention to the alignment problem. Our model quantifies misalignment in large, diverse agent groups with potentially conflicting goals across various problem areas. Misalignment scores in our framework depend on the observed agent population, the domain in question, and conflict between agents' weighted preferences. Through simulations, we demonstrate how our model captures intuitive aspects of misalignment across different scenarios. We then apply our model to two case studies, including an autonomous vehicle setting, showcasing its practical utility. Our approach offers enhanced explanatory power for complex sociotechnical environments and could inform the design of more aligned AI systems in real-world applications.
Read more9/10/2024

0
A Roadmap to Pluralistic Alignment
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell Gordon, Niloofar Mireshghallah, Christopher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, Tim Althoff, Yejin Choi
With increased power and prevalence of AI systems, it is ever more critical that AI systems are designed to serve all, i.e., people with diverse values and perspectives. However, aligning models to serve pluralistic human values remains an open research question. In this piece, we propose a roadmap to pluralistic alignment, specifically using language models as a test bed. We identify and formalize three possible ways to define and operationalize pluralism in AI systems: 1) Overton pluralistic models that present a spectrum of reasonable responses; 2) Steerably pluralistic models that can steer to reflect certain perspectives; and 3) Distributionally pluralistic models that are well-calibrated to a given population in distribution. We also formalize and discuss three possible classes of pluralistic benchmarks: 1) Multi-objective benchmarks, 2) Trade-off steerable benchmarks, which incentivize models to steer to arbitrary trade-offs, and 3) Jury-pluralistic benchmarks which explicitly model diverse human ratings. We use this framework to argue that current alignment techniques may be fundamentally limited for pluralistic AI; indeed, we highlight empirical evidence, both from our own experiments and from other work, that standard alignment procedures might reduce distributional pluralism in models, motivating the need for further research on pluralistic alignment.
Read more8/22/2024