ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks

0
Sign in to get full access
Overview
- Adapter tuning is a parameter-efficient approach for fine-tuning large language models on various tasks.
- The paper proposes a new adapter architecture called ELP-Adapters (Efficient Lightweight Projection Adapters) for speech processing tasks.
- ELP-Adapters achieve high performance while requiring fewer parameters to fine-tune compared to full model fine-tuning.
Plain English Explanation
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks explores a new way to adapt large language models to perform different speech-related tasks, like automatic speech recognition, speaker verification, emotion recognition, and intent detection.
The key idea is to use "adapters" - small neural network layers that are inserted into the larger language model. These adapters can be fine-tuned on the specific speech task, while most of the language model's parameters remain frozen. This "parameter-efficient" approach requires tuning far fewer parameters compared to fine-tuning the entire language model.
The authors propose a new adapter architecture called ELP-Adapters that further improves efficiency and performance over previous adapter designs. ELP-Adapters use a lightweight projection mechanism that can learn task-specific adaptations without dramatically increasing the model size.
The paper demonstrates that ELP-Adapters achieve strong results across multiple speech processing benchmarks, while requiring only a fraction of the parameters needed for full fine-tuning. This makes them an attractive option when computational resources are limited, or when rapidly adapting a single language model to many different speech applications.
Technical Explanation
The paper investigates using adapter-based fine-tuning as a parameter-efficient approach for adapting large pre-trained language models to various speech processing tasks.
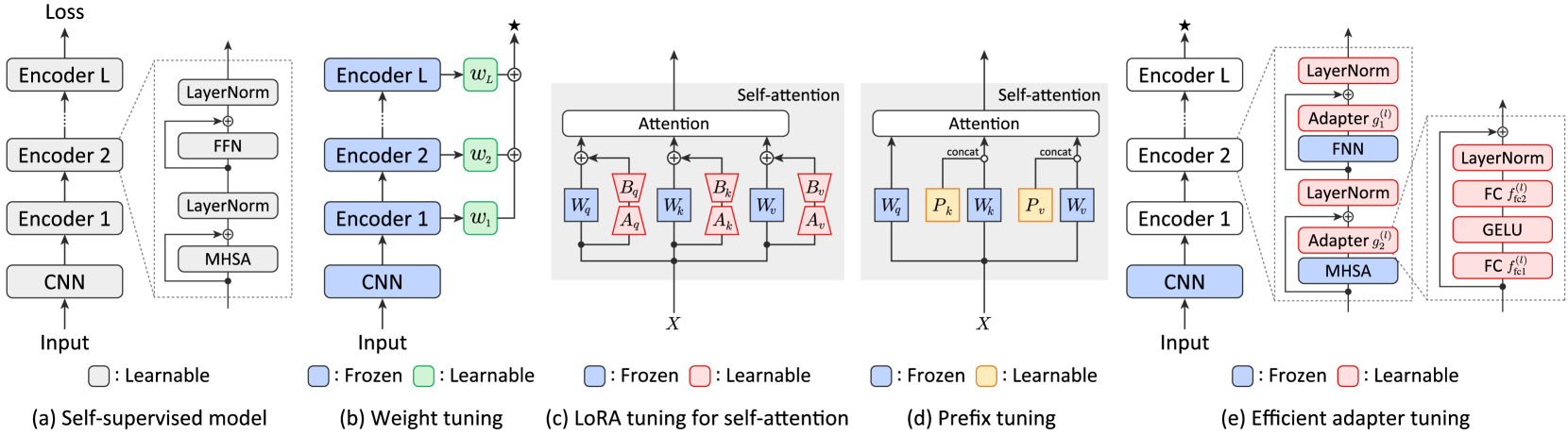
The authors propose a new adapter architecture called ELP-Adapters that utilizes a lightweight projection mechanism to learn task-specific adaptations. ELP-Adapters are inserted between the transformer layers of the base language model and can be fine-tuned on target tasks while keeping most of the language model's parameters frozen.
Experiments are conducted on automatic speech recognition, automatic speaker verification, speech emotion recognition, and speech intent recognition benchmarks. The results show that ELP-Adapters achieve strong performance, often matching or exceeding the accuracy of full model fine-tuning, while requiring significantly fewer tunable parameters.
Critical Analysis
The paper provides a thorough evaluation of ELP-Adapters on a diverse set of speech processing tasks, demonstrating their effectiveness as a parameter-efficient fine-tuning approach. However, the authors acknowledge that the performance of ELP-Adapters may be sensitive to the choice of hyperparameters and architectural details. Further research could explore ways to make the adapter design more robust and stable across different tasks and datasets.
Additionally, while the paper focuses on speech processing, the proposed ELP-Adapter architecture could potentially be applied to other domains beyond speech, such as natural language processing or computer vision. Investigating the generalizability of ELP-Adapters to a wider range of tasks and modalities could be an interesting area for future work.
Conclusion
ELP-Adapters present a promising approach for parameter-efficient fine-tuning of large language models on various speech processing tasks. The lightweight projection-based adapter architecture achieves strong performance while requiring significantly fewer tunable parameters compared to full model fine-tuning.
This work contributes to the growing body of research on adapter-based methods, which aim to make large pre-trained models more accessible and usable for a wide range of applications, even with limited computational resources. The findings in this paper suggest that ELP-Adapters could be a valuable tool for speech-based AI systems that need to be quickly adapted to new tasks or domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks
Nakamasa Inoue, Shinta Otake, Takumi Hirose, Masanari Ohi, Rei Kawakami
Self-supervised learning has emerged as a key approach for learning generic representations from speech data. Despite promising results in downstream tasks such as speech recognition, speaker verification, and emotion recognition, a significant number of parameters is required, which makes fine-tuning for each task memory-inefficient. To address this limitation, we introduce ELP-adapter tuning, a novel method for parameter-efficient fine-tuning using three types of adapter, namely encoder adapters (E-adapters), layer adapters (L-adapters), and a prompt adapter (P-adapter). The E-adapters are integrated into transformer-based encoder layers and help to learn fine-grained speech representations that are effective for speech recognition. The L-adapters create paths from each encoder layer to the downstream head and help to extract non-linguistic features from lower encoder layers that are effective for speaker verification and emotion recognition. The P-adapter appends pseudo features to CNN features to further improve effectiveness and efficiency. With these adapters, models can be quickly adapted to various speech processing tasks. Our evaluation across four downstream tasks using five backbone models demonstrated the effectiveness of the proposed method. With the WavLM backbone, its performance was comparable to or better than that of full fine-tuning on all tasks while requiring 90% fewer learnable parameters.
Read more8/1/2024
🌿
0
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
Read more5/10/2024

0
An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
Varsha Suresh, Salah Ait-Mokhtar, Caroline Brun, Ioan Calapodescu
Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
Read more6/24/2024
0
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
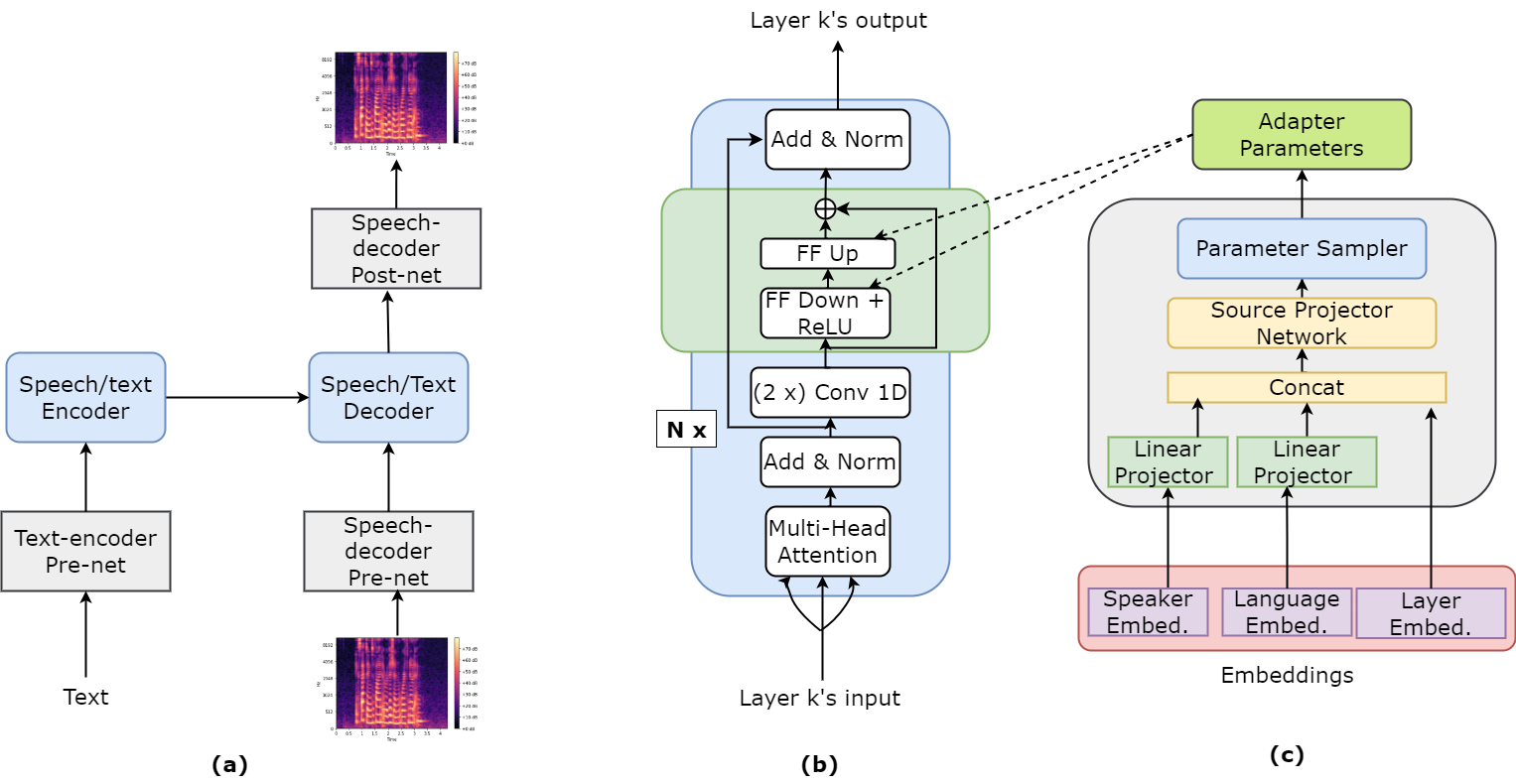
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
Read more6/26/2024