Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
2406.17257
0
0
Abstract
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
Create account to get full access
Overview
- This paper explores a parameter-efficient approach to adapting text-to-speech (TTS) models to multiple languages, which can be more practical and cost-effective than training separate models for each language.
- The researchers propose a method called HyperTTS that leverages language-specific adapters - small neural network layers that can be efficiently fine-tuned on new languages without significantly increasing the overall model size.
- HyperTTS is evaluated on several multilingual TTS benchmarks and demonstrates strong performance, matching or exceeding the quality of language-specific TTS models while requiring far fewer trainable parameters.
Plain English Explanation
HyperTTS: Parameter-Efficient Adaptation for Text-to-Speech is a technique that allows text-to-speech (TTS) models to be adapted to work with multiple languages without needing to completely retrain the entire model from scratch for each new language. This can be more practical and cost-effective than building separate TTS models for every language.
The key idea is to use small "adapter" neural network layers that can be fine-tuned on new languages. These adapters only have a fraction of the parameters of the full TTS model, so they can be trained quickly and efficiently on data for a new language. This allows the core TTS model to be reused and only the language-specific components need to be updated.
The researchers evaluated this HyperTTS approach on several multi-lingual TTS benchmarks and found that it can match or even exceed the quality of TTS models trained specifically for each individual language. But it requires far fewer trainable parameters overall, making it a more practical and cost-effective solution.
This type of parameter-efficient transfer learning for TTS could be especially valuable for deploying high-quality multilingual speech synthesis in real-world applications, where model size and training time are important constraints. The meta-learning techniques used in HyperTTS may also have broader applications beyond just TTS.
Technical Explanation
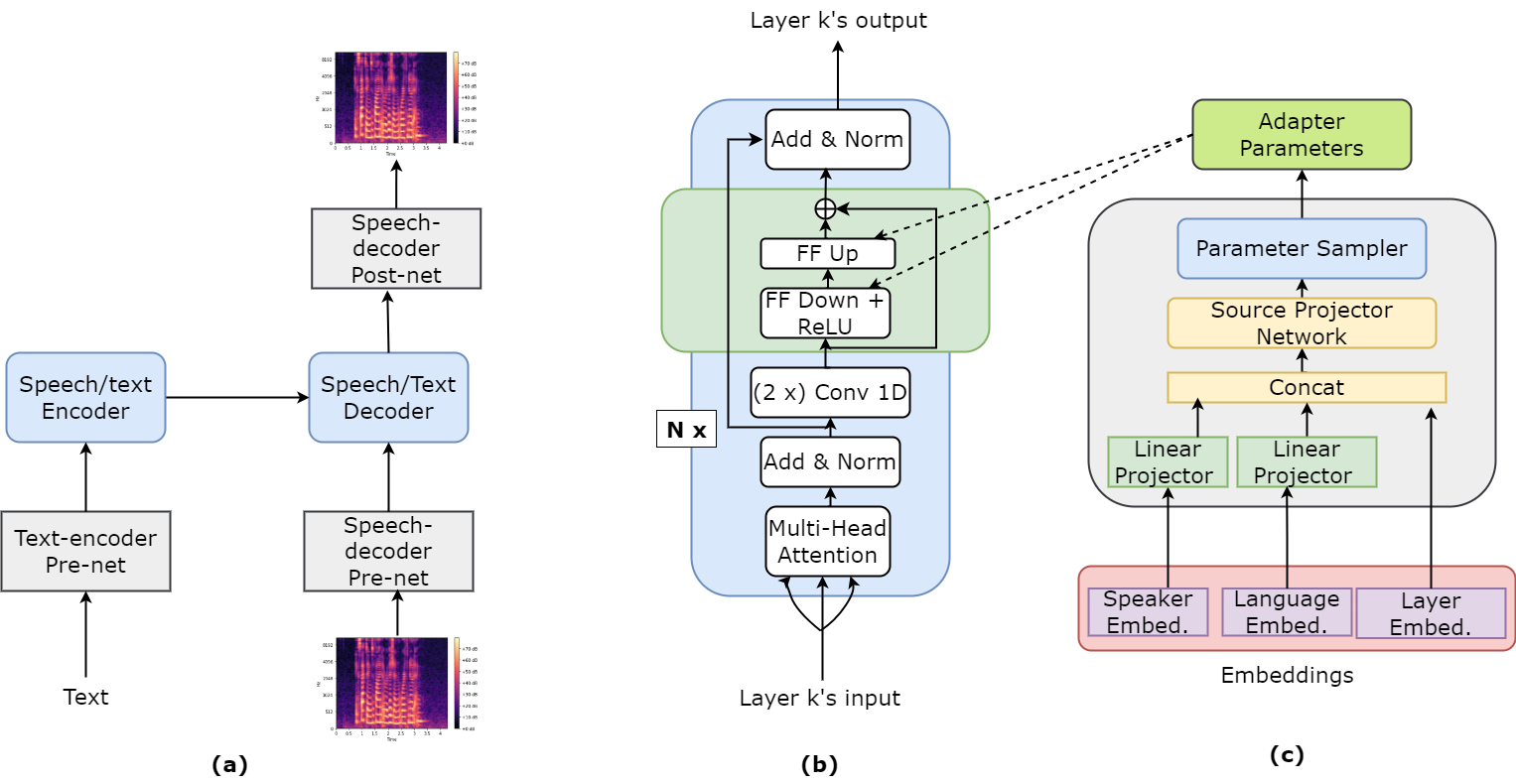
HyperTTS: Parameter-Efficient Adaptation for Text-to-Speech proposes a method for adapting text-to-speech (TTS) models to work with multiple languages without needing to completely retrain the entire model for each new language.
The key innovation is the use of language-specific "adapter" modules - small neural network layers that can be efficiently fine-tuned on new languages. These adapters only have a fraction of the parameters of the full TTS model, so they can be trained quickly on data for a new language. This allows the core TTS model to be reused, and only the language-specific components need to be updated.
The researchers evaluate HyperTTS on several multilingual TTS benchmarks, including the VCTK, LJSpeech, and M-AILABS datasets. They find that HyperTTS can match or exceed the performance of TTS models trained specifically for each individual language, while requiring far fewer trainable parameters.
This parameter-efficient transfer learning approach to multilingual TTS has several advantages. It is more practical and cost-effective than building separate TTS models for every language. The meta-learning techniques used in HyperTTS may also have broader applications beyond just TTS.
Critical Analysis
The HyperTTS paper presents a compelling approach to making text-to-speech models more practical and cost-effective for multilingual deployment. The use of compact, language-specific adapter modules is a clever way to leverage transfer learning without dramatically increasing model size.
However, the paper does not explore some potential limitations or areas for future work. For example, it's unclear how well HyperTTS would scale to a larger number of languages, or how it might handle more distant language pairs that require more substantial architectural changes.
Additionally, the evaluation is primarily focused on objective metrics like mean opinion score. It would be valuable to also assess real-world usability factors like inference speed, memory footprint, and ease of deployment, especially for resource-constrained applications.
Overall, HyperTTS represents an important step forward in making high-quality multilingual TTS more practical. But further research is needed to fully understand the strengths, weaknesses, and broader applicability of this parameter-efficient adaptation approach.
Conclusion
HyperTTS: Parameter-Efficient Adaptation for Text-to-Speech introduces a novel technique for adapting text-to-speech models to work with multiple languages. By using compact, language-specific adapter modules, HyperTTS can match or exceed the performance of language-specific TTS models while requiring far fewer trainable parameters.
This parameter-efficient transfer learning approach has significant practical advantages, making high-quality multilingual speech synthesis more feasible to deploy in real-world applications with tight resource constraints. The meta-learning techniques used in HyperTTS may also have broader applications beyond just text-to-speech.
While the paper demonstrates the promise of this approach, further research is needed to fully understand its scalability, robustness, and real-world usability. Nonetheless, HyperTTS represents an important step forward in making multilingual TTS more accessible and practical.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Yingting Li, Rishabh Bhardwaj, Ambuj Mehrish, Bo Cheng, Soujanya Poria
0
0
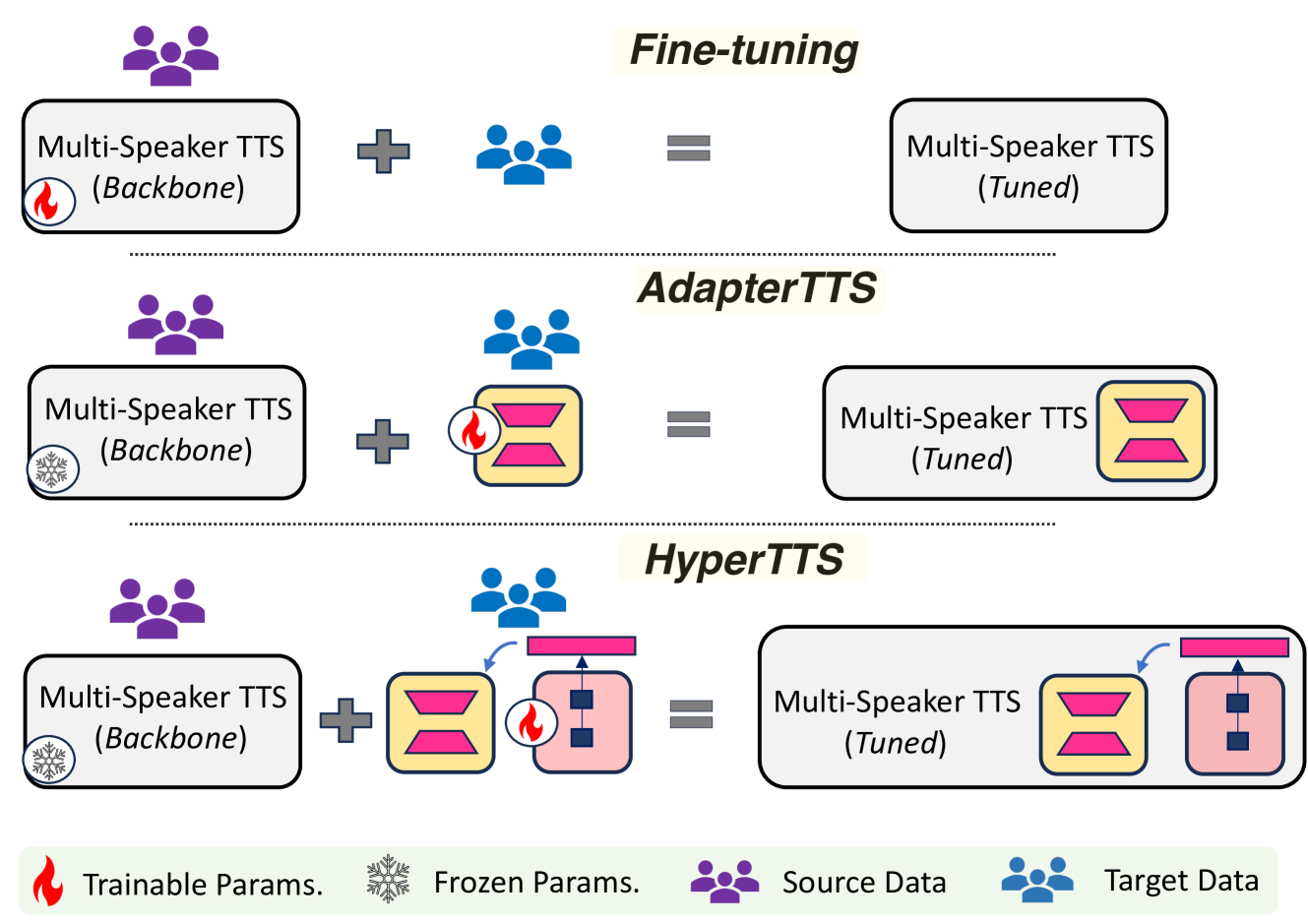
Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, hypernetwork, that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.
4/9/2024
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Cheng Gong, Erica Cooper, Xin Wang, Chunyu Qiang, Mengzhe Geng, Dan Wells, Longbiao Wang, Jianwu Dang, Marc Tessier, Aidan Pine, Korin Richmond, Junichi Yamagishi
0
0
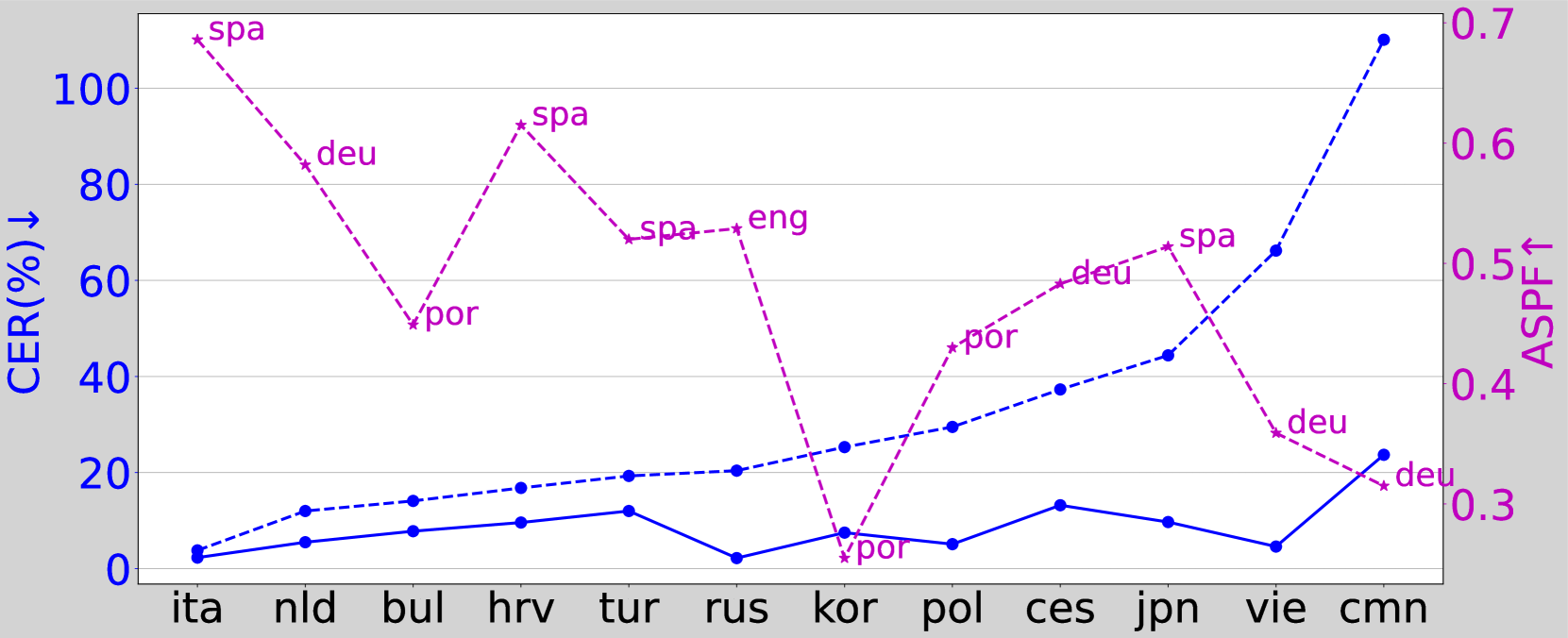
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
6/14/2024
Multilingual Prosody Transfer: Comparing Supervised & Transfer Learning
Arnav Goel, Medha Hira, Anubha Gupta
0
0
The field of prosody transfer in speech synthesis systems is rapidly advancing. This research is focused on evaluating learning methods for adapting pre-trained monolingual text-to-speech (TTS) models to multilingual conditions, i.e., Supervised Fine-Tuning (SFT) and Transfer Learning (TL). This comparison utilizes three distinct metrics: Mean Opinion Score (MOS), Recognition Accuracy (RA), and Mel Cepstral Distortion (MCD). Results demonstrate that, in comparison to SFT, TL leads to significantly enhanced performance, with an average MOS higher by 1.53 points, a 37.5% increase in RA, and approximately a 7.8-point improvement in MCD. These findings are instrumental in helping build TTS models for low-resource languages.
6/19/2024

Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Florian Lux, Sarina Meyer, Lyonel Behringer, Frank Zalkow, Phat Do, Matt Coler, Emanuel A. P. Habets, Ngoc Thang Vu
0
0
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
6/11/2024