Embodiment: Self-Supervised Depth Estimation Based on Camera Models

0

Sign in to get full access
Overview
- This paper presents a self-supervised depth estimation method based on camera models.
- The approach leverages the inherent geometry of the camera to learn depth without requiring ground truth depth data.
- The method is evaluated on several benchmarks and achieves state-of-the-art performance in monocular depth estimation.
Plain English Explanation
In this paper, the researchers developed a new way to estimate the depth of objects in an image without needing to have the actual depth measurements. Typically, training depth estimation models requires a large dataset of images paired with their corresponding depth information. This can be challenging and expensive to obtain.
The key insight of this work is to instead use the inherent geometry of the camera itself to learn about depth. The researchers show that by modeling how the camera works, they can train a neural network to predict depth in a self-supervised way - without relying on any ground truth depth data.
The method works by having the network learn to reconstruct the input image from multiple viewpoints, which implicitly requires it to understand the 3D structure of the scene. This allows the network to learn depth in a purely self-supervised manner, without any manual labeling of depth.
The researchers evaluate their approach on several benchmark datasets for monocular depth estimation, and show that it achieves state-of-the-art performance. This is an important advance, as it means we can now train powerful depth estimation models without the need for expensive ground truth depth data.
Technical Explanation
The core of the proposed method is a self-supervised depth estimation framework that leverages camera models. Rather than relying on ground truth depth data, the approach exploits the inherent geometry of the camera to learn depth in a self-supervised manner.
The key idea is to train a neural network to reconstruct the input image from multiple viewpoints. This reconstruction task implicitly requires the network to learn the 3D structure of the scene, including the depth information. By optimizing this reconstruction objective, the network is able to predict accurate depth maps without any ground truth depth supervision.
Specifically, the method works as follows. First, the network is trained to predict the camera parameters (intrinsics and extrinsics) that relate the input image to a target view. These predicted camera parameters are then used to warp the input image to the target view, and the network is trained to minimize the reconstruction error between the warped image and the target image.
This reconstruction-based training procedure encourages the network to learn depth representations that enable accurate image warping and reconstruction. The researchers show that this self-supervised depth learning approach outperforms prior methods on several benchmark datasets for monocular depth estimation.
One key aspect of the method is its ability to handle both static and dynamic scenes. The network is able to predict accurate depth even in the presence of moving objects, by reasoning about the 3D structure of the scene beyond just the static background.
Overall, this work represents an important advance in self-supervised depth estimation, demonstrating that powerful depth prediction models can be trained without the need for expensive ground truth depth data. The insights from this research could have broad implications for 3D scene understanding in a variety of applications.
Critical Analysis
The proposed self-supervised depth estimation method has several strengths, but also some potential limitations that are worth considering.
On the positive side, the core idea of leveraging camera geometry to learn depth in a self-supervised manner is elegant and effective. By optimizing for image reconstruction from multiple viewpoints, the network is able to capture the 3D structure of the scene without any direct depth supervision. This is a clever strategy that sidesteps the challenge of obtaining ground truth depth data.
Additionally, the method's ability to handle dynamic scenes is an important capability, as many real-world applications involve non-static environments. Being robust to moving objects is a valuable property that sets this approach apart from prior self-supervised depth methods.
However, one potential limitation is that the method still requires the camera parameters (intrinsics and extrinsics) to be known or estimated. While this is a weaker requirement than needing ground truth depth, it could still be a barrier in certain scenarios where the camera calibration is unknown or difficult to obtain.
Another consideration is the computational complexity of the reconstruction-based training procedure. Warping images to multiple viewpoints and optimizing the reconstruction loss may be more resource-intensive than some other self-supervised depth approaches.
Additionally, while the paper demonstrates state-of-the-art results on standard benchmarks, it would be valuable to see how the method generalizes to more diverse real-world settings and applications. Further evaluation in challenging, uncontrolled environments could reveal additional strengths or limitations of the approach.
Overall, this work represents an important step forward in self-supervised depth estimation. The core ideas are thoughtful and the results are promising. However, as with any research, there are opportunities to explore further refinements and extensions to broaden the method's applicability and robustness.
Conclusion
This paper presents a novel self-supervised depth estimation technique that leverages the inherent geometry of the camera to learn depth without any ground truth depth data. By training the network to reconstruct images from multiple viewpoints, the method is able to capture the 3D structure of the scene in a self-supervised manner.
The key innovation is the use of camera models to enable this self-supervised depth learning, which allows the approach to handle both static and dynamic scenes. The researchers demonstrate state-of-the-art performance on several benchmark datasets for monocular depth estimation, highlighting the power and versatility of the proposed method.
This work represents an important advance in the field of self-supervised depth estimation, with the potential to significantly reduce the barrier to entry for training accurate depth prediction models. The insights from this research could have wide-ranging implications for 3D scene understanding in a variety of applications, from robotics and autonomous vehicles to augmented reality and computational photography.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Embodiment: Self-Supervised Depth Estimation Based on Camera Models
Jinchang Zhang, Praveen Kumar Reddy, Xue-Iuan Wong, Yiannis Aloimonos, Guoyu Lu
Depth estimation is a critical topic for robotics and vision-related tasks. In monocular depth estimation, in comparison with supervised learning that requires expensive ground truth labeling, self-supervised methods possess great potential due to no labeling cost. However, self-supervised learning still has a large gap with supervised learning in 3D reconstruction and depth estimation performance. Meanwhile, scaling is also a major issue for monocular unsupervised depth estimation, which commonly still needs ground truth scale from GPS, LiDAR, or existing maps to correct. In the era of deep learning, existing methods primarily rely on exploring image relationships to train unsupervised neural networks, while the physical properties of the camera itself such as intrinsics and extrinsics are often overlooked. These physical properties are not just mathematical parameters; they are embodiments of the camera's interaction with the physical world. By embedding these physical properties into the deep learning model, we can calculate depth priors for ground regions and regions connected to the ground based on physical principles, providing free supervision signals without the need for additional sensors. This approach is not only easy to implement but also enhances the effects of all unsupervised methods by embedding the camera's physical properties into the model, thereby achieving an embodied understanding of the real world.
Read more8/30/2024
📈
0
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Hoang Chuong Nguyen, Tianyu Wang, Jose M. Alvarez, Miaomiao Liu
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
Read more4/24/2024

0
Uncertainty and Self-Supervision in Single-View Depth
Javier Rodriguez-Puigvert
Single-view depth estimation refers to the ability to derive three-dimensional information per pixel from a single two-dimensional image. Single-view depth estimation is an ill-posed problem because there are multiple depth solutions that explain 3D geometry from a single view. While deep neural networks have been shown to be effective at capturing depth from a single view, the majority of current methodologies are deterministic in nature. Accounting for uncertainty in the predictions can avoid disastrous consequences when applied to fields such as autonomous driving or medical robotics. We have addressed this problem by quantifying the uncertainty of supervised single-view depth for Bayesian deep neural networks. There are scenarios, especially in medicine in the case of endoscopic images, where such annotated data is not available. To alleviate the lack of data, we present a method that improves the transition from synthetic to real domain methods. We introduce an uncertainty-aware teacher-student architecture that is trained in a self-supervised manner, taking into account the teacher uncertainty. Given the vast amount of unannotated data and the challenges associated with capturing annotated depth in medical minimally invasive procedures, we advocate a fully self-supervised approach that only requires RGB images and the geometric and photometric calibration of the endoscope. In endoscopic imaging, the camera and light sources are co-located at a small distance from the target surfaces. This setup indicates that brighter areas of the image are nearer to the camera, while darker areas are further away. Building on this observation, we exploit the fact that for any given albedo and surface orientation, pixel brightness is inversely proportional to the square of the distance. We propose the use of illumination as a strong single-view self-supervisory signal for deep neural networks.
Read more6/21/2024
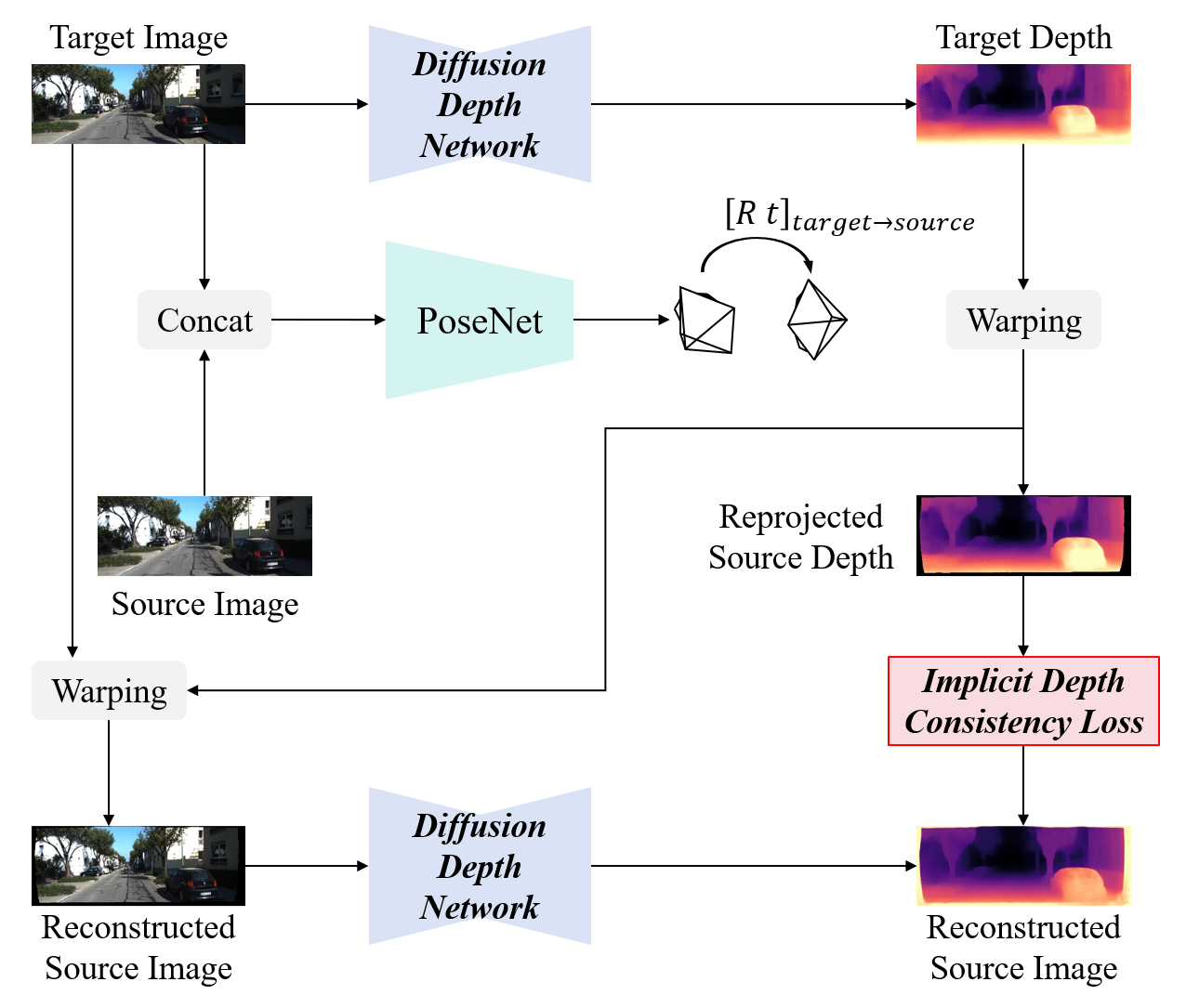
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024