Emergency Department Decision Support using Clinical Pseudo-notes

0
Sign in to get full access
Overview
- This paper presents a novel approach to generating "multimodal clinical pseudo-notes" for use in emergency department prediction tasks.
- The method utilizes a "Multiple Embedding Model for EHR (MEME)" to effectively leverage different data modalities from electronic health records (EHRs).
- The goal is to improve the performance of machine learning models on various clinical prediction tasks, such as predicting patient outcomes or resource utilization.
Plain English Explanation
In the medical field, electronic health records (EHRs) contain a wealth of information about patients, including things like test results, diagnoses, and treatments. Researchers have been exploring ways to use this data to build better machine learning models that can help healthcare providers make more informed decisions.
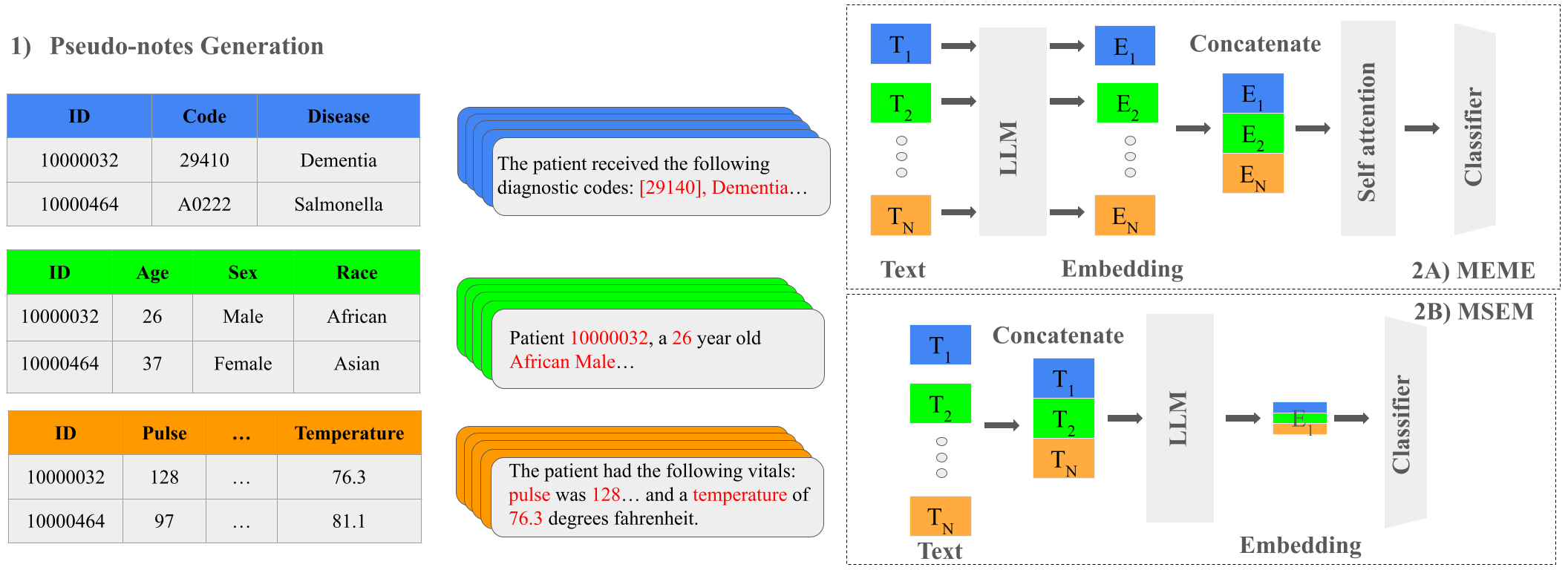
This paper introduces a new technique called "multimodal clinical pseudo-notes" that aims to improve the performance of these models. The key idea is to combine different types of data from the EHRs, such as text, images, and structured medical codes, into a single, more comprehensive representation of the patient's medical history.
The researchers developed a "Multiple Embedding Model for EHR (MEME)" to effectively capture and integrate these different data modalities. By using this approach, they were able to create "pseudo-notes" that contain richer information about the patients, which can then be used to train machine learning models for tasks like predicting patient outcomes or resource utilization in the emergency department.
Technical Explanation
The key innovation in this paper is the "Multiple Embedding Model for EHR (MEME)" architecture, which the authors use to generate the multimodal clinical pseudo-notes. MEME consists of multiple sub-models, each designed to encode a specific data modality from the EHR, such as text, images, and structured medical codes.
These sub-models are then combined into a single, unified representation of the patient's medical history. The authors experiment with different techniques for fusing the sub-model outputs, including concatenation, attention mechanisms, and meta-learning approaches.
The resulting multimodal pseudo-notes are then used as input to various machine learning models, which are trained and evaluated on a range of emergency department prediction tasks. The authors demonstrate that this approach outperforms using individual data modalities or simpler fusion methods, highlighting the benefits of their MEME architecture.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed MEME approach, exploring its performance across multiple prediction tasks and comparing it to various baselines. The authors also discuss several limitations and potential areas for future research.
One potential limitation is the reliance on "pseudo-notes" rather than the original EHR data. While the pseudo-notes are designed to capture the key information, there may be some loss of nuance or context compared to using the raw data. Additionally, the authors note that the performance of the MEME model is dependent on the quality and completeness of the underlying EHR data.
Another area for further exploration is the generalizability of the MEME approach. The experiments in this paper focus on emergency department prediction tasks, but it would be valuable to see how the method performs on a broader range of clinical prediction problems, such as clinical named entity recognition or patient recruitment for clinical trials.
Overall, this paper represents a significant contribution to the field of clinical machine learning, demonstrating the potential of multimodal approaches to improve the performance of predictive models in healthcare.
Conclusion
The "Multimodal Clinical Pseudo-notes for Emergency Department Prediction Tasks using Multiple Embedding Model for EHR (MEME)" paper presents a novel and promising approach to leveraging the rich data available in electronic health records. By combining multiple data modalities into a unified representation using the MEME architecture, the researchers were able to develop more accurate predictive models for various emergency department tasks.
This work highlights the importance of exploring multimodal approaches in clinical machine learning and the potential benefits of integrating diverse data sources to gain a more comprehensive understanding of patient health. As the field continues to evolve, techniques like MEME may become increasingly valuable in supporting healthcare providers, improving patient outcomes, and advancing the state of the art in medical artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Emergency Department Decision Support using Clinical Pseudo-notes
Simon A. Lee, Sujay Jain, Alex Chen, Kyoka Ono, Jennifer Fang, Akos Rudas, Jeffrey N. Chiang
In this work, we introduce the Multiple Embedding Model for EHR (MEME), an approach that serializes multimodal EHR tabular data into text using pseudo-notes, mimicking clinical text generation. This conversion not only preserves better representations of categorical data and learns contexts but also enables the effective employment of pretrained foundation models for rich feature representation. To address potential issues with context length, our framework encodes embeddings for each EHR modality separately. We demonstrate the effectiveness of MEME by applying it to several decision support tasks within the Emergency Department across multiple hospital systems. Our findings indicate that MEME outperforms traditional machine learning, EHR-specific foundation models, and general LLMs, highlighting its potential as a general and extendible EHR representation strategy.
Read more5/1/2024

0
MEDFuse: Multimodal EHR Data Fusion with Masked Lab-Test Modeling and Large Language Models
Thao Minh Nguyen Phan, Cong-Tinh Dao, Chenwei Wu, Jian-Zhe Wang, Shun Liu, Jun-En Ding, David Restrepo, Feng Liu, Fang-Ming Hung, Wen-Chih Peng
Electronic health records (EHRs) are multimodal by nature, consisting of structured tabular features like lab tests and unstructured clinical notes. In real-life clinical practice, doctors use complementary multimodal EHR data sources to get a clearer picture of patients' health and support clinical decision-making. However, most EHR predictive models do not reflect these procedures, as they either focus on a single modality or overlook the inter-modality interactions/redundancy. In this work, we propose MEDFuse, a Multimodal EHR Data Fusion framework that incorporates masked lab-test modeling and large language models (LLMs) to effectively integrate structured and unstructured medical data. MEDFuse leverages multimodal embeddings extracted from two sources: LLMs fine-tuned on free clinical text and masked tabular transformers trained on structured lab test results. We design a disentangled transformer module, optimized by a mutual information loss to 1) decouple modality-specific and modality-shared information and 2) extract useful joint representation from the noise and redundancy present in clinical notes. Through comprehensive validation on the public MIMIC-III dataset and the in-house FEMH dataset, MEDFuse demonstrates great potential in advancing clinical predictions, achieving over 90% F1 score in the 10-disease multi-label classification task.
Read more7/18/2024

0
EMERGE: Integrating RAG for Improved Multimodal EHR Predictive Modeling
Yinghao Zhu, Changyu Ren, Zixiang Wang, Xiaochen Zheng, Shiyun Xie, Junlan Feng, Xi Zhu, Zhoujun Li, Liantao Ma, Chengwei Pan
The integration of multimodal Electronic Health Records (EHR) data has notably advanced clinical predictive capabilities. However, current models that utilize clinical notes and multivariate time-series EHR data often lack the necessary medical context for precise clinical tasks. Previous methods using knowledge graphs (KGs) primarily focus on structured knowledge extraction. To address this, we propose EMERGE, a Retrieval-Augmented Generation (RAG) driven framework aimed at enhancing multimodal EHR predictive modeling. Our approach extracts entities from both time-series data and clinical notes by prompting Large Language Models (LLMs) and aligns them with professional PrimeKG to ensure consistency. Beyond triplet relationships, we include entities' definitions and descriptions to provide richer semantics. The extracted knowledge is then used to generate task-relevant summaries of patients' health statuses. These summaries are fused with other modalities utilizing an adaptive multimodal fusion network with cross-attention. Extensive experiments on the MIMIC-III and MIMIC-IV datasets for in-hospital mortality and 30-day readmission tasks demonstrate the superior performance of the EMERGE framework compared to baseline models. Comprehensive ablation studies and analyses underscore the efficacy of each designed module and the framework's robustness to data sparsity. EMERGE significantly enhances the use of multimodal EHR data in healthcare, bridging the gap with nuanced medical contexts crucial for informed clinical predictions.
Read more6/4/2024
💬
0
Large Language Multimodal Models for 5-Year Chronic Disease Cohort Prediction Using EHR Data
Jun-En Ding, Phan Nguyen Minh Thao, Wen-Chih Peng, Jian-Zhe Wang, Chun-Cheng Chug, Min-Chen Hsieh, Yun-Chien Tseng, Ling Chen, Dongsheng Luo, Chi-Te Wang, Pei-fu Chen, Feng Liu, Fang-Ming Hung
Chronic diseases such as diabetes are the leading causes of morbidity and mortality worldwide. Numerous research studies have been attempted with various deep learning models in diagnosis. However, most previous studies had certain limitations, including using publicly available datasets (e.g. MIMIC), and imbalanced data. In this study, we collected five-year electronic health records (EHRs) from the Taiwan hospital database, including 1,420,596 clinical notes, 387,392 laboratory test results, and more than 1,505 laboratory test items, focusing on research pre-training large language models. We proposed a novel Large Language Multimodal Models (LLMMs) framework incorporating multimodal data from clinical notes and laboratory test results for the prediction of chronic disease risk. Our method combined a text embedding encoder and multi-head attention layer to learn laboratory test values, utilizing a deep neural network (DNN) module to merge blood features with chronic disease semantics into a latent space. In our experiments, we observe that clinicalBERT and PubMed-BERT, when combined with attention fusion, can achieve an accuracy of 73% in multiclass chronic diseases and diabetes prediction. By transforming laboratory test values into textual descriptions and employing the Flan T-5 model, we achieved a 76% Area Under the ROC Curve (AUROC), demonstrating the effectiveness of leveraging numerical text data for training and inference in language models. This approach significantly improves the accuracy of early-stage diabetes prediction.
Read more9/2/2024