Emergent Open-Vocabulary Semantic Segmentation from Off-the-shelf Vision-Language Models
2311.17095
0
0

Abstract
From image-text pairs, large-scale vision-language models (VLMs) learn to implicitly associate image regions with words, which prove effective for tasks like visual question answering. However, leveraging the learned association for open-vocabulary semantic segmentation remains a challenge. In this paper, we propose a simple, yet extremely effective, training-free technique, Plug-and-Play Open-Vocabulary Semantic Segmentation (PnP-OVSS) for this task. PnP-OVSS leverages a VLM with direct text-to-image cross-attention and an image-text matching loss. To balance between over-segmentation and under-segmentation, we introduce Salience Dropout; by iteratively dropping patches that the model is most attentive to, we are able to better resolve the entire extent of the segmentation mask. PnP-OVSS does not require any neural network training and performs hyperparameter tuning without the need for any segmentation annotations, even for a validation set. PnP-OVSS demonstrates substantial improvements over comparable baselines (+26.2% mIoU on Pascal VOC, +20.5% mIoU on MS COCO, +3.1% mIoU on COCO Stuff and +3.0% mIoU on ADE20K). Our codebase is at https://github.com/letitiabanana/PnP-OVSS.
Create account to get full access
Introduction
The paper discusses open-vocabulary semantic segmentation (OVSS), which aims to identify and localize arbitrary object categories in images without relying on predefined object sets or dense pixel-level annotations. The authors propose leveraging the cross-attention layers of large vision-language models (VLMs) pretrained on image-text pairs for this task. These models have demonstrated impressive performance on multimodal tasks like image description and question answering, suggesting they possess an inherent ability to localize objects.
However, directly applying cross-attention between the class name and image patches leads to over-segmentation, where the masks include irrelevant regions. To address this, the authors propose an iterative approach called Salience DropOut. It uses GradCAM attention scores to identify the most discriminative regions and then drops those image patches, forcing the model to attend to less discriminative but still relevant object parts. This process aims to acquire complete object masks, overcoming the under-segmentation issue observed when using only the most discriminative regions.
The key aspects covered in the summary include open-vocabulary semantic segmentation, leveraging cross-attention layers of VLMs, the challenges of over-segmentation and under-segmentation, and the proposed Salience DropOut method to iteratively refine the object masks.
The paper proposes Plug-and-Play Open-vocabulary Semantic Segmentation (PnP-OVSS), a simple and training-free framework to extract semantic segmentations from vision-language models (VLMs). The key aspects are:
-
It combines text-to-image attention, GradCAM, and Salience DropOut to iteratively acquire accurate segmentation masks for arbitrary classes from pretrained VLMs.
-
It replaces the need for densely annotated validation sets by introducing a weakly-supervised reward function based on CLIP. This function contrasts the extracted object regions with a blank image and rewards higher similarity to the target class name.
-
Hyperparameters are tuned using a simple random search optimized for this reward function, eliminating the need for pixel-level annotations.
The proposed method requires no additional training and delivers high performance, outperforming most recent techniques that require extensive finetuning. It hints at a new direction for open-vocabulary segmentation tasks leveraging large vision-language models without relying on dense annotations.
Related Work
This section discusses large-scale vision-language models (VLMs) and zero-shot semantic segmentation approaches. It mentions that VLMs can be trained on millions of image-text pairs and are useful for multimodal tasks like visual question answering and image captioning. Common architectures involve aligning visual and textual representations through methods like cross-attention or self-attention over all tokens from both modalities. Loss functions used for training VLMs include image-text contrastive learning, image-text matching, masked token/patch prediction, and language modeling.
The paper utilizes models with unimodal encoders followed by cross-attention fusion, as they work well with high-level features and can accurately attend to relevant image patches. The image-text matching loss gradient is used to sharpen segmentation masks.
Zero-shot semantic segmentation aims to predict segmentation masks for objects described by text prompts, without prior exposure to class-specific annotations during training. Traditional methods train classifiers to distinguish seen and unseen visual features obtained from generative models. Recent methods leverage knowledge from VLMs to better match visual and textual features.
The section then compares various zero-shot semantic segmentation methods based on the type of supervision required during training/fine-tuning. Some methods require fine-tuning on image-text pairs, while others can operate without additional supervision but involve fine-tuning on pseudo-labels. The proposed PnP-OVSS method does not require any fine-tuning or additional paired image-text annotations and can directly distill segmentations from VLMs with cross-attention and image-text matching loss.
Method
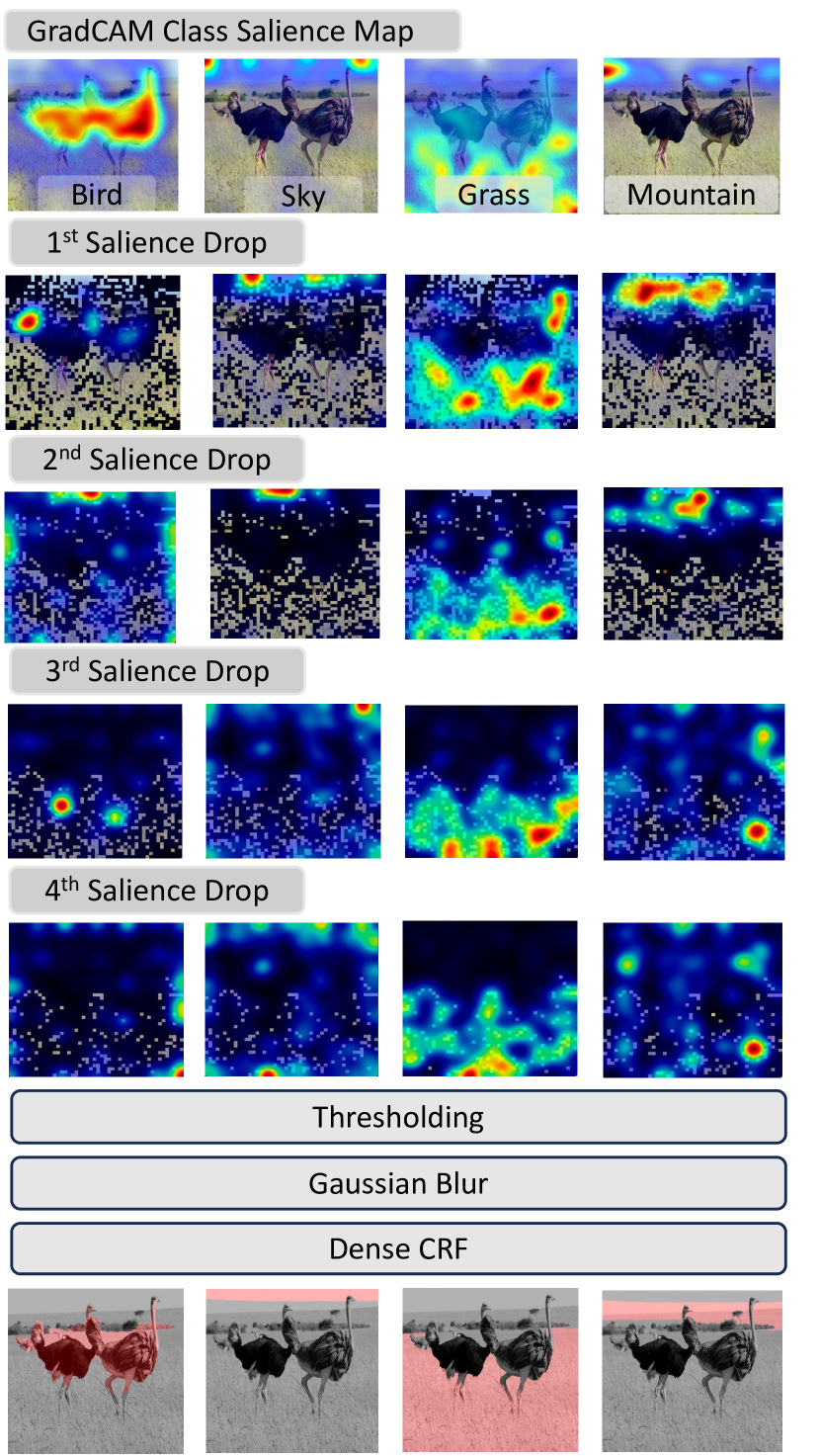
The paper describes a method called PnP-OVSS (Plug-and-Play Open-Vocabulary Semantic Segmentation) for zero-shot semantic segmentation using pre-trained vision-language models. The key steps are:
-
Extract cross-attention maps from the vision-language model for each object class specified in a text prompt.
-
Sharpen the attention maps using a GradCAM-style technique with the image-text matching loss.
-
Apply Salience DropOut, an iterative process that forces the model to attend to less discriminative regions by progressively dropping out high-salience patches.
-
Apply Dense CRF for fine-grained boundary refinement.
The paper also proposes a weakly-supervised reward function to tune hyperparameters like the cross-attention layer, attention head, and threshold for binarizing salience maps. This reward function only requires image-level class labels, not pixel-wise annotations.
The method aims to perform open-vocabulary semantic segmentation without per-dataset training by leveraging the knowledge stored in large vision-language models in a plug-and-play manner.
Experiments
The section discusses the datasets, implementation details, and experimental results for the proposed PnP-OVSS (Plug-and-Play Open-Vocabulary Semantic Segmentation) method.
Key points:
- Evaluated on Pascal VOC 2012, Pascal Context, COCO Object, and COCO Stuff datasets for zero-shot semantic segmentation.
- Applied PnP-OVSS to two vision-language models (VLMs): BLIP and BridgeTower.
- Performed random search to tune hyperparameters like layers, heads, attention thresholds, and gaussian blur.
- Compared against recent baselines that either require finetuning on image-text data (Group 1), finetuning without image-text data (Group 2), or no finetuning (Group 3 - most relevant).
- PnP-OVSS outperformed Group 3 baselines by large margins on all datasets under equal resolutions.
- Also outperformed many baselines from Groups 1 and 2, despite not using additional training data.
- An ablation study showed the positive impact of each component like GradCAM, Salience DropOut, Gaussian blur, and Dense CRF.
- Analysis revealed significant performance variations across layers and attention heads, highlighting the importance of proper selection.
The section demonstrates the effectiveness of the proposed PnP-OVSS method for zero-shot open-vocabulary semantic segmentation without requiring additional training or dense annotations.
Conclusions
The paper proposes a technique called PnP-OVSS (Plug-and-Play Open-Vocabulary Semantic Segmentation) that can extract the semantic segmentation capability from large vision-language models (VLMs). PnP-OVSS is easy to use, does not require additional fine-tuning, and delivers high performance, surpassing all baselines that do not require fine-tuning as well as those that do not use image-text pairs during fine-tuning. The success of PnP-OVSS suggests a new direction for open-vocabulary segmentation tasks by leveraging the power of large VLMs.
Additional Qualitative Results
The paper presents additional qualitative results from images in the Pascal Context and COCO Stuff datasets. It notes that in one image, the proposed method PnP-OVSS correctly recognizes four loaves of bread, while the ground truth only annotates one. The rightmost column in the bottom three rows shows failure cases. One example contains multiple small instances of the same class, which is challenging. Another example has multiple instances of people, causing difficulties for PnP-OVSS to cover all objects. Images with a clutter of different objects and complex textures often lead to a drop in performance.

Qualitative Results in the Wild
The provided text discusses qualitative results showcased in Figures 5 and 6 of the paper. These figures demonstrate the model's capability to segment fictional and cartoon characters like Batman, Ironman, Minions, and Gru. Notably, these character types are considered out-of-distribution objects that are not commonly found in semantic segmentation datasets used for training. Despite this challenge, the model exhibits promising performance in segmenting these unconventional object classes.
PnP-OVSS Implementation Detail
The text provides implementation details for different components used in the experiments:
BLIP: The ITM branch of BLIP-large is used, which employs ViT-L/16 as the image encoder, BERT as the text encoder, and an extra cross-attention layer for each BERT transformer block. Positional embedding is interpolated to allow 768x768 input resolution. Pretrained weights from COCO and Flickr image retrieval checkpoints are adopted.
BridgeTower: The ITM branch of BridgeTower-large is used, with ViT-L/14 as the image encoder, RoBERTa-large as the text encoder, and a 6-layer cross-attention encoder. Each cross-attention layer has a hidden size of 1,024 and 16 attention heads. Positional embedding is interpolated for 770x770 input resolution. The model weights are from the Hugging Face checkpoint 'bridgetowerlarge-itm-mlm-itc'.
Random Search: The random search routine from the Gradient-Free-Optimizers library is adopted, using the reward metric described in Section 3.4. The search space is divided into three groups, each running on a GPU, with 34 iterations per group. The best hyperparameter set across the three groups is selected.
Class Split: For densely supervised models, the class split follows common settings, with specific classes held out as unseen for Pascal VOC, Pascal Context, and COCO Stuff datasets.
Vil-Seg Evaluation Detail
The paper evaluates the proposed Vil-Seg method on a subset of datasets rather than requiring weakly supervised finetuning on image-text data like other methods. Specifically, Vil-Seg is evaluated on 5 out of 20 object categories in PASCAL VOC (potted plant, sheep, sofa, train, tv-monitor), 4 out of 59 object categories in PASCAL Context (cow, motorbike, sofa, cat), and 15 out of 171 object categories in COCO Stuff (frisbee, skateboard, cardboard, carrot, scissors, suitcase, giraffe, cow, road, wall concrete, tree, grass, river, clouds, playing-field).
Details of Zero-shot Semantic Segmentation Techniques
The paper discusses various methods for zero-shot semantic segmentation and compares them through a table (Tab 7). It covers the type of supervision used in each method, whether pre-training and fine-tuning are required, the pre-trained weights employed, the data used for fine-tuning, and the total data size utilized. This tabular representation allows for a straightforward comparison between the different approaches to zero-shot semantic segmentation.
PnP-OVSS with ALBEF and mPLUG
The paper applies the proposed PnP-OVSS method to two other vision language models, ALBEF and mPLUG, in addition to BLIP and BridgeTower. However, the performance on these models is not as good as BLIP or BridgeTower.
ALBEF is pretrained on a smaller dataset of 14M images with a ViT-B architecture, while BLIP and BridgeTower use larger pretraining datasets of 129M and 404M images respectively with a ViT-L architecture. The authors speculate that vision language models require sufficient parameters and pretraining data to acquire localization capability.
mPLUG is another vision language model pretrained on 14M images with ViT-L, but it is trained for both image and video tasks. With a relatively smaller pretraining dataset compared to BLIP and BridgeTower, as well as dual-modality objectives for images and videos, mPLUG also does not perform well in image object localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Sina Hajimiri, Ismail Ben Ayed, Jose Dolz
0
0
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
4/15/2024

A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
Thomas Stegmuller, Tim Lebailly, Nikola Dukic, Behzad Bozorgtabar, Tinne Tuytelaars, Jean-Philippe Thiran
0
0
Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
7/2/2024
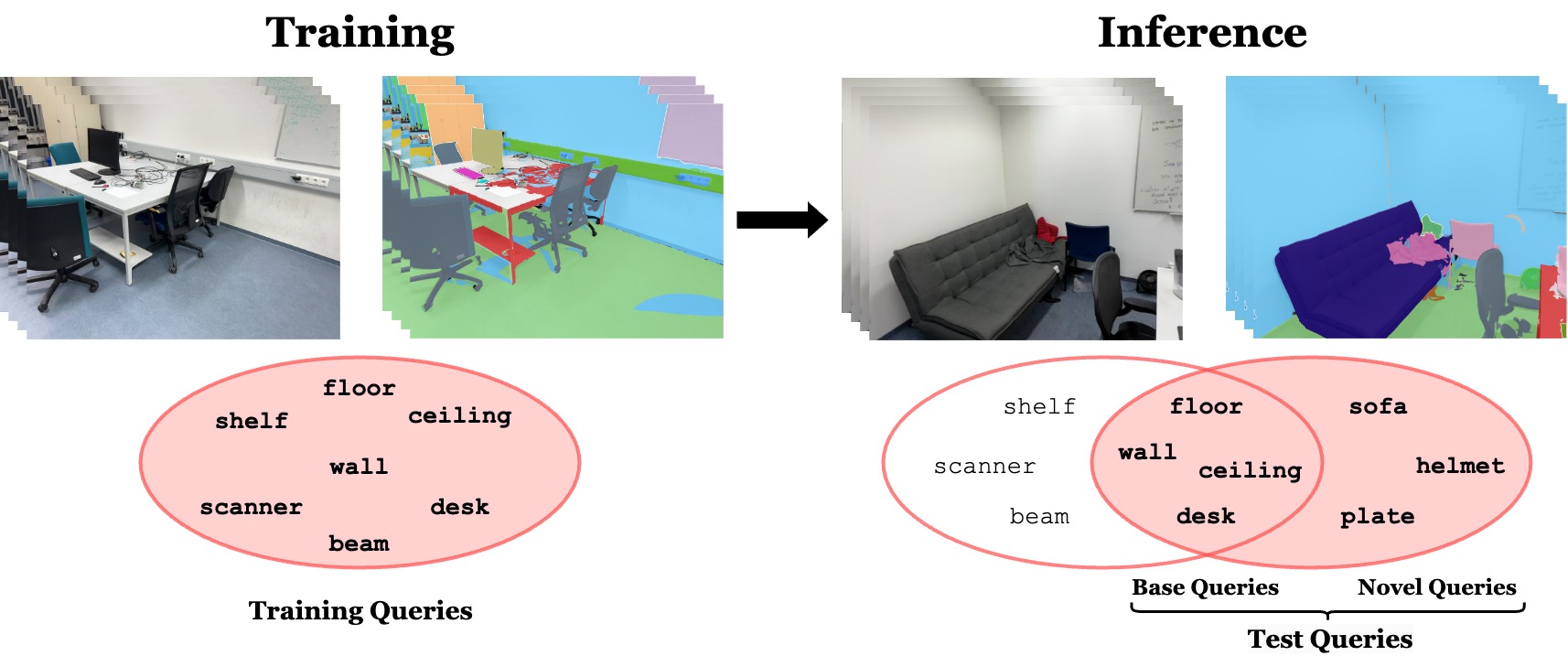
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
0
0
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
5/31/2024
🏋️
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
Shuyang Sun, Runjia Li, Philip Torr, Xiuye Gu, Siyang Li
0
0
Existing open-vocabulary image segmentation methods require a fine-tuning step on mask labels and/or image-text datasets. Mask labels are labor-intensive, which limits the number of categories in segmentation datasets. Consequently, the vocabulary capacity of pre-trained VLMs is severely reduced after fine-tuning. However, without fine-tuning, VLMs trained under weak image-text supervision tend to make suboptimal mask predictions. To alleviate these issues, we introduce a novel recurrent framework that progressively filters out irrelevant texts and enhances mask quality without training efforts. The recurrent unit is a two-stage segmenter built upon a frozen VLM. Thus, our model retains the VLM's broad vocabulary space and equips it with segmentation ability. Experiments show that our method outperforms not only the training-free counterparts, but also those fine-tuned with millions of data samples, and sets the new state-of-the-art records for both zero-shot semantic and referring segmentation. Concretely, we improve the current record by 28.8, 16.0, and 6.9 mIoU on Pascal VOC, COCO Object, and Pascal Context.
5/8/2024