Emergent Visual-Semantic Hierarchies in Image-Text Representations

0

Sign in to get full access
Overview
- This paper explores the emergence of visual-semantic hierarchies in image-text representation models.
- The researchers investigate how high-level visual and semantic concepts are encoded and organized within these multi-modal models.
- The findings shed light on the inner workings of state-of-the-art vision-language models and have implications for multi-modal representation learning.
Plain English Explanation
The paper examines how advanced AI models that combine visual and textual information (like VISTA) organize their understanding of the world. Rather than just memorizing individual facts, these models develop hierarchical knowledge structures, similar to how the human brain organizes concepts.
The researchers looked "under the hood" of these models to see how higher-level visual and semantic ideas (like "animal," "vehicle," "person") emerge and relate to each other. This sheds light on how these models build rich representations of the world by discovering patterns and relationships in the data they are trained on.
Understanding these internal knowledge structures is important for improving vision-language models and making them more robust, interpretable, and aligned with human understanding. It also has implications for enhancing multi-modal learning in areas like robotics, content understanding, and user assistance.
Technical Explanation
The researchers used techniques from representational similarity analysis to study the hierarchical structure of visual and semantic concepts encoded in state-of-the-art vision-language models. They analyzed the similarity relationships between the internal representations of different visual and textual inputs to reveal how higher-level abstractions emerge.
The experiments showed that these models spontaneously develop semantic hierarchies, organizing visual and linguistic concepts into taxonomies. For example, the model learns that "dog" and "cat" are more similar to each other than to "car," and that these animal categories are subordinate to the more general concept of "living thing."
This hierarchical structure mirrors findings from cognitive science about how humans build conceptual knowledge. The models appear to discover these relationships by discovering statistical patterns in the training data, rather than being explicitly programmed with this knowledge.
The researchers also found that the visual and semantic hierarchies learned by the models are tightly coupled, with visual features like shape and texture informing the semantic groupings, and vice versa. This synergy between the visual and linguistic understanding is a key strength of these multi-modal architectures.
Critical Analysis
The paper provides a valuable window into the inner workings of state-of-the-art vision-language models, but the analysis is limited to a single model architecture (ViLT) on a fixed set of benchmark tasks. Further research is needed to understand how these hierarchical structures emerge across a wider range of model types, training regimes, and application domains.
Additionally, the study focuses on analyzing the model's representations at a single, static point in time. An interesting avenue for future work would be to investigate how these hierarchies develop and evolve as the model is trained on more and more data over time.
Finally, while the paper demonstrates the emergence of meaningful conceptual structures, it does not address potential biases or limitations in the knowledge acquired by these models. As these systems become more widely deployed, it will be important to scrutinize their representations for issues like skewed perceptions or text-centric blindspots.
Conclusion
This paper provides valuable insights into the internal organization of knowledge in state-of-the-art vision-language models. By revealing the emergence of hierarchical visual-semantic representations, the findings shed light on how these models build rich, structured understandings of the world.
Understanding these internal knowledge structures is crucial for improving the robustness, interpretability, and real-world applicability of multi-modal learning systems. As these technologies become more widely adopted, further research is needed to fully characterize their strengths, limitations, and biases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Emergent Visual-Semantic Hierarchies in Image-Text Representations
Morris Alper, Hadar Averbuch-Elor
While recent vision-and-language models (VLMs) like CLIP are a powerful tool for analyzing text and images in a shared semantic space, they do not explicitly model the hierarchical nature of the set of texts which may describe an image. Conversely, existing multimodal hierarchical representation learning methods require costly training from scratch, failing to leverage the knowledge encoded by state-of-the-art multimodal foundation models. In this work, we study the knowledge of existing foundation models, finding that they exhibit emergent understanding of visual-semantic hierarchies despite not being directly trained for this purpose. We propose the Radial Embedding (RE) framework for probing and optimizing hierarchical understanding, and contribute the HierarCaps dataset, a benchmark facilitating the study of hierarchical knowledge in image--text representations, constructed automatically via large language models. Our results show that foundation VLMs exhibit zero-shot hierarchical understanding, surpassing the performance of prior models explicitly designed for this purpose. Furthermore, we show that foundation models may be better aligned to hierarchical reasoning via a text-only fine-tuning phase, while retaining pretraining knowledge.
Read more7/17/2024
🔍
0
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
Read more5/24/2024
📈
0
Enhancing the vision-language foundation model with key semantic knowledge-emphasized report refinement
Weijian Huang, Cheng Li, Hao Yang, Jiarun Liu, Yong Liang, Hairong Zheng, Shanshan Wang
Recently, vision-language representation learning has made remarkable advancements in building up medical foundation models, holding immense potential for transforming the landscape of clinical research and medical care. The underlying hypothesis is that the rich knowledge embedded in radiology reports can effectively assist and guide the learning process, reducing the need for additional labels. However, these reports tend to be complex and sometimes even consist of redundant descriptions that make the representation learning too challenging to capture the key semantic information. This paper develops a novel iterative vision-language representation learning framework by proposing a key semantic knowledge-emphasized report refinement method. Particularly, raw radiology reports are refined to highlight the key information according to a constructed clinical dictionary and two model-optimized knowledge-enhancement metrics. The iterative framework is designed to progressively learn, starting from gaining a general understanding of the patient's condition based on raw reports and gradually refines and extracts critical information essential to the fine-grained analysis tasks. The effectiveness of the proposed framework is validated on various downstream medical image analysis tasks, including disease classification, region-of-interest segmentation, and phrase grounding. Our framework surpasses seven state-of-the-art methods in both fine-tuning and zero-shot settings, demonstrating its encouraging potential for different clinical applications.
Read more9/5/2024
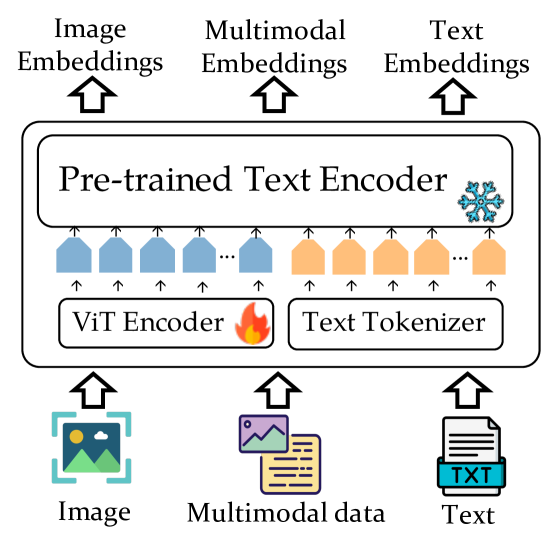
0
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Junjie Zhou, Zheng Liu, Shitao Xiao, Bo Zhao, Yongping Xiong
Multi-modal retrieval becomes increasingly popular in practice. However, the existing retrievers are mostly text-oriented, which lack the capability to process visual information. Despite the presence of vision-language models like CLIP, the current methods are severely limited in representing the text-only and image-only data. In this work, we present a new embedding model VISTA for universal multi-modal retrieval. Our work brings forth threefold technical contributions. Firstly, we introduce a flexible architecture which extends a powerful text encoder with the image understanding capability by introducing visual token embeddings. Secondly, we develop two data generation strategies, which bring high-quality composed image-text to facilitate the training of the embedding model. Thirdly, we introduce a multi-stage training algorithm, which first aligns the visual token embedding with the text encoder using massive weakly labeled data, and then develops multi-modal representation capability using the generated composed image-text data. In our experiments, VISTA achieves superior performances across a variety of multi-modal retrieval tasks in both zero-shot and supervised settings. Our model, data, and source code are available at https://github.com/FlagOpen/FlagEmbedding.
Read more6/7/2024