Emerging Platforms Meet Emerging LLMs: A Year-Long Journey of Top-Down Development
2404.09151
0
0

Abstract
Deploying machine learning (ML) on diverse computing platforms is crucial to accelerate and broaden their applications. However, it presents significant software engineering challenges due to the fast evolution of models, especially the recent Large Language Models (LLMs), and the emergence of new computing platforms. Current ML frameworks are primarily engineered for CPU and CUDA platforms, leaving a big gap in enabling emerging ones like Metal, Vulkan, and WebGPU. While a traditional bottom-up development pipeline fails to close the gap timely, we introduce TapML, a top-down approach and tooling designed to streamline the deployment of ML systems on diverse platforms, optimized for developer productivity. Unlike traditional bottom-up methods, which involve extensive manual testing and debugging, TapML automates unit testing through test carving and adopts a migration-based strategy for gradually offloading model computations from mature source platforms to emerging target platforms. By leveraging realistic inputs and remote connections for gradual target offloading, TapML accelerates the validation and minimizes debugging scopes, significantly optimizing development efforts. TapML was developed and applied through a year-long, real-world effort that successfully deployed significant emerging models and platforms. Through serious deployments of 82 emerging models in 17 distinct architectures across 5 emerging platforms, we showcase the effectiveness of TapML in enhancing developer productivity while ensuring model reliability and efficiency. Furthermore, we summarize comprehensive case studies from our real-world development, offering best practices for developing emerging ML systems.
Create account to get full access
Overview
- Discusses the challenges faced in developing emerging platforms that integrate with large language models (LLMs)
- Covers a year-long journey of top-down development, where the research team started with high-level requirements and iteratively built the system
- Highlights the importance of addressing technical constraints and user needs when integrating LLMs into real-world applications
Plain English Explanation
In this paper, the authors describe their experience of developing a system that combines emerging platforms with the latest large language models (LLMs). LLMs are powerful AI models that can understand and generate human-like text, and they are becoming increasingly integrated into various applications and platforms.
The researchers went through a year-long process of "top-down development," where they started with high-level goals and requirements, and then iteratively built the system to meet those goals. This approach allowed them to address the unique challenges that arise when integrating LLMs into real-world platforms, such as Characterization of Large Language Model Development Workflows in Datacenters, Transformer-Lite: High-Efficiency Deployment of Large Language Models, and Toward Cross-Layer Energy Optimizations for Machine Learning.
The paper highlights the importance of considering both technical constraints and user needs when developing systems that incorporate LLMs. By taking a top-down approach, the researchers were able to address these challenges and create a system that effectively integrates the latest AI advancements with emerging platforms.
Technical Explanation
The authors describe a year-long journey of developing a system that integrates emerging platforms with large language models (LLMs). They used a top-down approach, starting with high-level requirements and iteratively building the system to meet those requirements.
The key challenges they faced included Characterization of Large Language Model Development Workflows in Datacenters, Transformer-Lite: High-Efficiency Deployment of Large Language Models, and Toward Cross-Layer Energy Optimizations for Machine Learning. The authors needed to address the technical constraints of deploying LLMs, such as computational efficiency, energy consumption, and model size, while also ensuring the system met the needs of end-users.
The top-down approach allowed the researchers to iteratively refine the system design and evaluate it against both technical and user-centric criteria. This process led to insights such as Large Language Models can Automatically Engineer Features and Apprentices to Research Assistants: Advancing Research with Large Language Models, which highlight the potential of LLMs to enhance the capabilities of emerging platforms.
Critical Analysis
The paper provides a valuable case study of the challenges and insights gained from integrating LLMs into real-world platforms. The authors acknowledge the limitations of their top-down approach, noting that it may not be suitable for all development scenarios and that a more agile, bottom-up process may be more appropriate in some cases.
Additionally, the paper does not delve deeply into the specific techniques used to address the technical constraints, such as the Transformer-Lite approach for efficient LLM deployment. Further research into these optimization techniques and their broader applicability would be beneficial.
The authors also do not discuss potential ethical concerns or social implications of integrating LLMs into emerging platforms. As these models become more widely adopted, it will be crucial to consider the impact on privacy, bias, and the societal effects of AI-powered systems.
Conclusion
The paper presents a detailed account of the challenges and insights gained from a year-long journey of integrating large language models (LLMs) into emerging platforms. The top-down development approach allowed the researchers to address technical constraints while also ensuring the system met user needs.
The findings highlight the potential of LLMs to enhance the capabilities of various applications, but also underscore the importance of carefully considering both technical and user-centric factors when deploying these powerful AI models. As the integration of LLMs into real-world systems continues to evolve, this research provides valuable lessons and insights for the broader AI community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
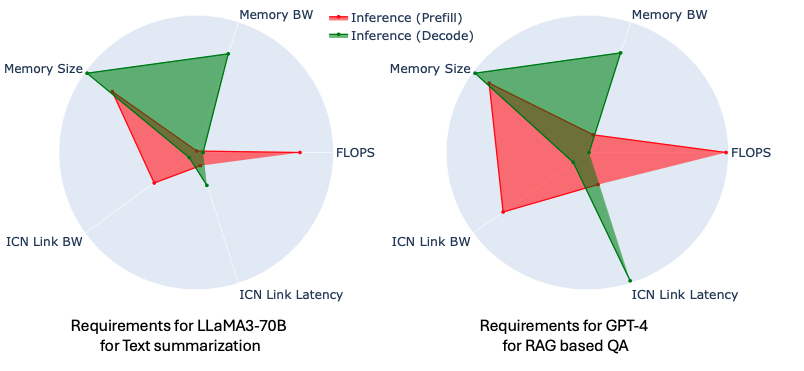
Demystifying Platform Requirements for Diverse LLM Inference Use Cases
Abhimanyu Bambhaniya, Ritik Raj, Geonhwa Jeong, Souvik Kundu, Sudarshan Srinivasan, Midhilesh Elavazhagan, Madhu Kumar, Tushar Krishna
0
0
Large language models (LLMs) have shown remarkable performance across a wide range of applications, often outperforming human experts. However, deploying these parameter-heavy models efficiently for diverse inference use cases requires carefully designed hardware platforms with ample computing, memory, and network resources. With LLM deployment scenarios and models evolving at breakneck speed, the hardware requirements to meet SLOs remains an open research question. In this work, we present an analytical tool, GenZ, to study the relationship between LLM inference performance and various platform design parameters. Our analysis provides insights into configuring platforms for different LLM workloads and use cases. We quantify the platform requirements to support SOTA LLMs models like LLaMA and GPT-4 under diverse serving settings. Furthermore, we project the hardware capabilities needed to enable future LLMs potentially exceeding hundreds of trillions of parameters. The trends and insights derived from GenZ can guide AI engineers deploying LLMs as well as computer architects designing next-generation hardware accelerators and platforms. Ultimately, this work sheds light on the platform design considerations for unlocking the full potential of large language models across a spectrum of applications. The source code is available at https://github.com/abhibambhaniya/GenZ-LLM-Analyzer .
6/5/2024

New Solutions on LLM Acceleration, Optimization, and Application
Yingbing Huang, Lily Jiaxin Wan, Hanchen Ye, Manvi Jha, Jinghua Wang, Yuhong Li, Xiaofan Zhang, Deming Chen
0
0
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
6/18/2024
🏷️
Beyond development: Challenges in deploying machine learning models for structural engineering applications
Mohsen Zaker Esteghamati, Brennan Bean, Henry V. Burton, M. Z. Naser
0
0
Machine learning (ML)-based solutions are rapidly changing the landscape of many fields, including structural engineering. Despite their promising performance, these approaches are usually only demonstrated as proof-of-concept in structural engineering, and are rarely deployed for real-world applications. This paper aims to illustrate the challenges of developing ML models suitable for deployment through two illustrative examples. Among various pitfalls, the presented discussion focuses on model overfitting and underspecification, training data representativeness, variable omission bias, and cross-validation. The results highlight the importance of implementing rigorous model validation techniques through adaptive sampling, careful physics-informed feature selection, and considerations of both model complexity and generalizability.
4/22/2024
🏋️
Automating the Training and Deployment of Models in MLOps by Integrating Systems with Machine Learning
Penghao Liang, Bo Song, Xiaoan Zhan, Zhou Chen, Jiaqiang Yuan
0
0
This article introduces the importance of machine learning in real-world applications and explores the rise of MLOps (Machine Learning Operations) and its importance for solving challenges such as model deployment and performance monitoring. By reviewing the evolution of MLOps and its relationship to traditional software development methods, the paper proposes ways to integrate the system into machine learning to solve the problems faced by existing MLOps and improve productivity. This paper focuses on the importance of automated model training, and the method to ensure the transparency and repeatability of the training process through version control system. In addition, the challenges of integrating machine learning components into traditional CI/CD pipelines are discussed, and solutions such as versioning environments and containerization are proposed. Finally, the paper emphasizes the importance of continuous monitoring and feedback loops after model deployment to maintain model performance and reliability. Using case studies and best practices from Netflix, the article presents key strategies and lessons learned for successful implementation of MLOps practices, providing valuable references for other organizations to build and optimize their own MLOps practices.
5/17/2024