Demystifying Platform Requirements for Diverse LLM Inference Use Cases
2406.01698
0
0
Abstract
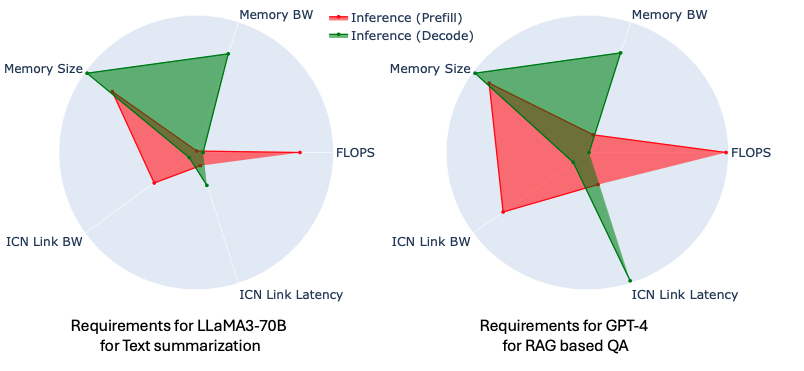
Large language models (LLMs) have shown remarkable performance across a wide range of applications, often outperforming human experts. However, deploying these parameter-heavy models efficiently for diverse inference use cases requires carefully designed hardware platforms with ample computing, memory, and network resources. With LLM deployment scenarios and models evolving at breakneck speed, the hardware requirements to meet SLOs remains an open research question. In this work, we present an analytical tool, GenZ, to study the relationship between LLM inference performance and various platform design parameters. Our analysis provides insights into configuring platforms for different LLM workloads and use cases. We quantify the platform requirements to support SOTA LLMs models like LLaMA and GPT-4 under diverse serving settings. Furthermore, we project the hardware capabilities needed to enable future LLMs potentially exceeding hundreds of trillions of parameters. The trends and insights derived from GenZ can guide AI engineers deploying LLMs as well as computer architects designing next-generation hardware accelerators and platforms. Ultimately, this work sheds light on the platform design considerations for unlocking the full potential of large language models across a spectrum of applications. The source code is available at https://github.com/abhibambhaniya/GenZ-LLM-Analyzer .
Create account to get full access
Overview
- This paper explores the diverse hardware and software requirements for deploying large language models (LLMs) in a variety of real-world use cases.
- The authors provide a comprehensive analysis of the key factors that influence the platform needs for LLM inference, including model size, task complexity, performance requirements, and energy efficiency.
- Through a series of experiments and case studies, the paper aims to demystify the often-overlooked complexities involved in scaling LLM deployment across different applications and environments.
Plain English Explanation
Large language models (LLMs) like GPT-3 and DALL-E have shown remarkable capabilities in a wide range of tasks, from text generation to image creation. However, the infrastructure required to deploy these models in real-world applications is often complex and not well understood.
This paper aims to shed light on the diverse hardware and software requirements for using LLMs in different contexts. The authors explore factors such as model size, task complexity, performance needs, and energy efficiency, and how they impact the platforms required for LLM inference. They use a variety of experiments and case studies to illustrate the challenges and trade-offs involved in scaling LLM deployment.
For example, running a large LLM on a powerful GPU-accelerated server may be suitable for a high-performance application like language translation, but it may not be the best solution for a low-power edge device like a smartphone. The paper examines these differences and provides guidance on selecting the appropriate hardware and software stack for different LLM use cases.
By demystifying the platform requirements for LLM inference, the authors hope to help researchers, developers, and deployment teams make more informed decisions when it comes to scaling these powerful models in real-world applications. This is especially important as LLMs continue to grow in size and complexity, as described in papers on LLM development and datacenter challenges.
Technical Explanation
The paper begins by highlighting the diverse range of use cases for large language models (LLMs), from language translation and summarization to task-oriented dialogue and multimodal applications like image generation. The authors argue that the hardware and software requirements for deploying LLMs in these different contexts can vary significantly, and that a one-size-fits-all approach is unlikely to be effective.
To understand these platform requirements, the researchers conducted a series of experiments and case studies. They examined factors such as model size, task complexity, performance needs (e.g., latency, throughput), and energy efficiency, and how they impact the choice of hardware (CPUs, GPUs, accelerators) and software stacks (e.g., deployment frameworks, inference optimizations).
Through their analysis, the authors identify several key insights. For example, they find that while large, high-performance models may be suitable for certain applications, smaller, more efficient models can be better suited for low-power edge devices or latency-sensitive use cases. They also highlight the importance of considering the trade-offs between model size, accuracy, and inference speed, and how these factors can influence platform requirements.
The paper also discusses the challenges of scaling LLM deployment across diverse environments, such as the need for robust model packaging, versioning, and deployment tooling. The authors touch on the emerging field of LLM tokenomics and sustainability, which considers the economic and environmental implications of large-scale LLM deployment.
Critical Analysis
The paper provides a valuable and comprehensive analysis of the platform requirements for deploying LLMs in diverse use cases. The authors have clearly put a lot of thought and effort into understanding the nuances and trade-offs involved in scaling these models across different environments and applications.
One strength of the paper is its balanced approach, acknowledging both the significant potential of LLMs as well as the challenges and limitations of current deployment strategies. The authors do not shy away from discussing the complexities and trade-offs involved, which is important for helping researchers and practitioners develop more realistic expectations and strategies for LLM deployment.
However, one potential area of improvement could be a more in-depth discussion of the energy and environmental implications of large-scale LLM deployment. While the paper touches on this topic, it could be an important area for further research, especially as concerns grow about the energy-intensive nature of training and running these models.
Overall, this paper serves as an important resource for anyone working on deploying LLMs in real-world applications. By demystifying the platform requirements and trade-offs involved, it can help guide the development of more efficient and scalable LLM deployment strategies, ultimately unlocking the full potential of these powerful models.
Conclusion
This paper provides a comprehensive analysis of the diverse hardware and software requirements for deploying large language models (LLMs) in a variety of real-world use cases. Through a series of experiments and case studies, the authors identify key factors that influence platform needs, such as model size, task complexity, performance requirements, and energy efficiency.
By demystifying these platform requirements, the paper aims to help researchers, developers, and deployment teams make more informed decisions when it comes to scaling LLMs across different applications and environments. As these models continue to grow in size and complexity, understanding the trade-offs and challenges involved in their deployment will be crucial for unlocking their full potential and ensuring their responsible and sustainable use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New Solutions on LLM Acceleration, Optimization, and Application
Yingbing Huang, Lily Jiaxin Wan, Hanchen Ye, Manvi Jha, Jinghua Wang, Yuhong Li, Xiaofan Zhang, Deming Chen
0
0
Large Language Models (LLMs) have become extremely potent instruments with exceptional capacities for comprehending and producing human-like text in a wide range of applications. However, the increasing size and complexity of LLMs present significant challenges in both training and deployment, leading to substantial computational and storage costs as well as heightened energy consumption. In this paper, we provide a review of recent advancements and research directions aimed at addressing these challenges and enhancing the efficiency of LLM-based systems. We begin by discussing algorithm-level acceleration techniques focused on optimizing LLM inference speed and resource utilization. We also explore LLM-hardware co-design strategies with a vision to improve system efficiency by tailoring hardware architectures to LLM requirements. Further, we delve into LLM-to-accelerator compilation approaches, which involve customizing hardware accelerators for efficient LLM deployment. Finally, as a case study to leverage LLMs for assisting circuit design, we examine LLM-aided design methodologies for an important task: High-Level Synthesis (HLS) functional verification, by creating a new dataset that contains a large number of buggy and bug-free codes, which can be essential for training LLMs to specialize on HLS verification and debugging. For each aspect mentioned above, we begin with a detailed background study, followed by the presentation of several novel solutions proposed to overcome specific challenges. We then outline future research directions to drive further advancements. Through these efforts, we aim to pave the way for more efficient and scalable deployment of LLMs across a diverse range of applications.
6/18/2024
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
0
0
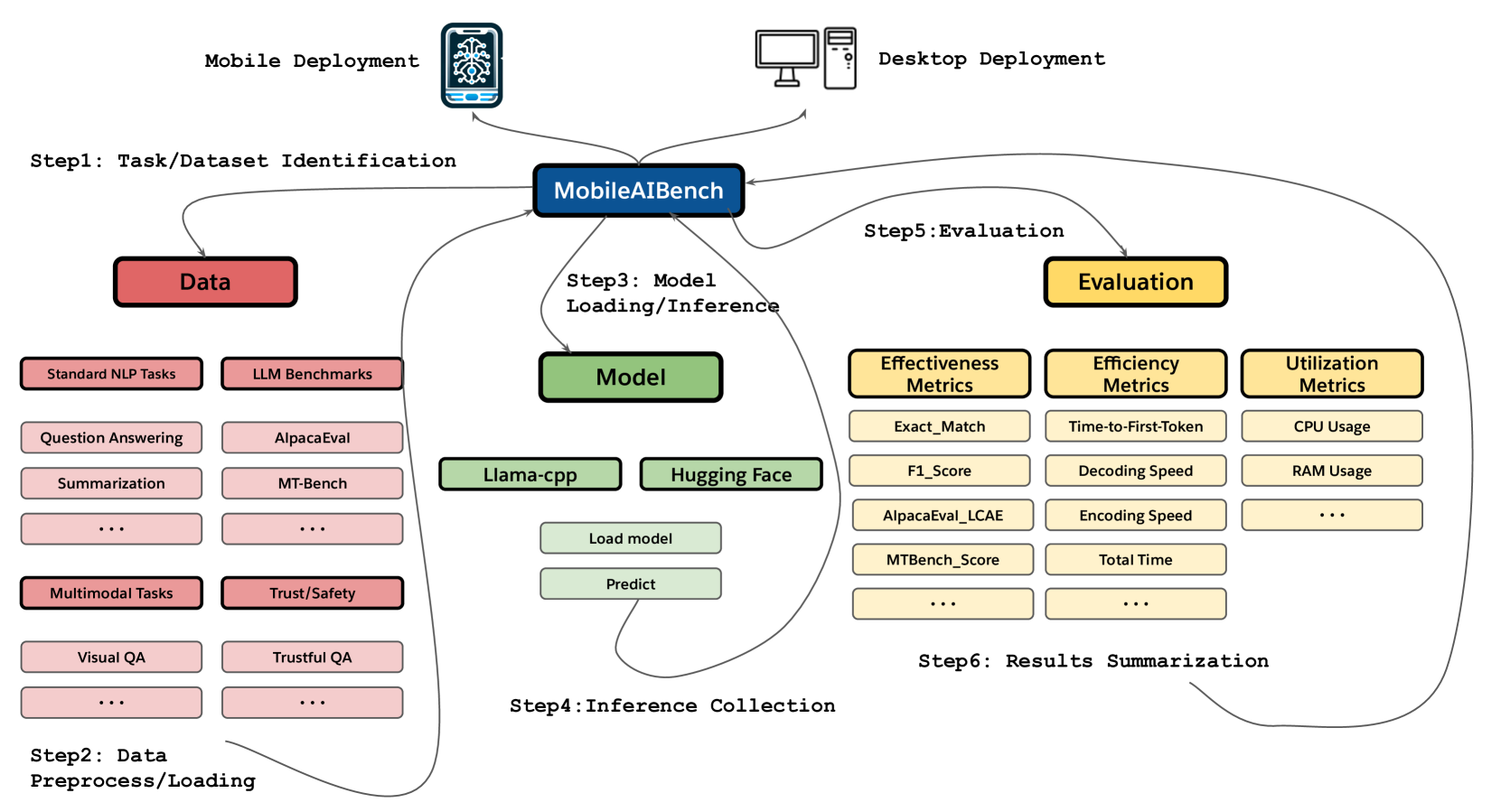
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
6/18/2024
📉
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Ruiyang Qin, Dancheng Liu, Zheyu Yan, Zhaoxuan Tan, Zixuan Pan, Zhenge Jia, Meng Jiang, Ahmed Abbasi, Jinjun Xiong, Yiyu Shi
0
0
The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
6/17/2024
🤔
Quantifying the Capabilities of LLMs across Scale and Precision
Sher Badshah, Hassan Sajjad
0
0
Scale is often attributed as one of the factors that cause an increase in the performance of LLMs, resulting in models with billion and trillion parameters. One of the limitations of such large models is the high computational requirements that limit their usage, deployment, and debugging in resource-constrained scenarios. Two commonly used alternatives to bypass these limitations are to use the smaller versions of LLMs (e.g. Llama 7B instead of Llama 70B) and lower the memory requirements by using quantization. While these approaches effectively address the limitation of resources, their impact on model performance needs thorough examination. In this study, we perform a comprehensive evaluation to investigate the effect of model scale and quantization on the performance. We experiment with two major families of open-source instruct models ranging from 7 billion to 70 billion parameters. Our extensive zero-shot experiments across various tasks including natural language understanding, reasoning, misinformation detection, and hallucination reveal that larger models generally outperform their smaller counterparts, suggesting that scale remains an important factor in enhancing performance. We found that larger models show exceptional resilience to precision reduction and can maintain high accuracy even at 4-bit quantization for numerous tasks and they serve as a better solution than using smaller models at high precision under similar memory requirements.
5/9/2024