Emotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
2310.19995
0
0
⚙️
Abstract
The emotional theory of mind problem requires facial expressions, body pose, contextual information and implicit commonsense knowledge to reason about the person's emotion and its causes, making it currently one of the most difficult problems in affective computing. In this work, we propose multiple methods to incorporate the emotional reasoning capabilities by constructing narrative captions relevant to emotion perception, that includes contextual and physical signal descriptors that focuses on Who, What, Where and How questions related to the image and emotions of the individual. We propose two distinct ways to construct these captions using zero-shot classifiers (CLIP) and fine-tuning visual-language models (LLaVA) over human generated descriptors. We further utilize these captions to guide the reasoning of language (GPT-4) and vision-language models (LLaVa, GPT-Vision). We evaluate the use of the resulting models in an image-to-language-to-emotion task. Our experiments showed that combining the Fast narrative descriptors and Slow reasoning of language models is a promising way to achieve emotional theory of mind.
Create account to get full access
Overview
- Emotional Theory of Mind is a complex problem in affective computing that requires understanding facial expressions, body language, context, and common sense knowledge.
- This paper proposes methods to construct narrative captions that describe the "Who, What, Where, and How" related to the emotions in an image.
- The captions are generated using zero-shot classifiers and fine-tuned vision-language models.
- These captions are then used to guide the reasoning of language and vision-language models to recognize emotions in an image-to-language-to-emotion task.
Plain English Explanation
Recognizing emotions in images is a challenging task that requires understanding not just the facial expressions and body language of the person, but also the context and common sense knowledge about the situation. This paper proposes a new approach to tackle this problem.
The key idea is to generate detailed captions that describe the "Who, What, Where, and How" of the emotional scene. These captions are created using advanced AI models that can process both the visual information in the image and the language used to describe it.
By generating these rich narrative captions, the researchers are able to provide more context and information to other AI models that are tasked with recognizing the emotions. The language and vision-language models can then use this additional context to better understand the emotional state of the person in the image.
This approach of combining fast narrative descriptions with slower, more deliberative reasoning models is a promising way to achieve a more human-like "emotional theory of mind" - the ability to infer the emotions and their causes based on the available information.
Technical Explanation
The paper proposes two main methods for constructing the narrative captions that describe the emotional scene:
-
Zero-shot Classifiers: The researchers use a large, pre-trained vision-language model called CLIP to classify the "Who, What, Where, and How" elements of the image without any additional training.
-
Fine-tuned Vision-Language Models: The researchers also fine-tune a vision-language model called LLaVA on a dataset of human-generated descriptors of emotional scenes. This allows the model to learn to generate more contextual and relevant captions.
The generated captions are then used to guide the reasoning of language models like GPT-4 and vision-language models like LLaVA and GPT-Vision. These models can use the additional context provided by the captions to better recognize the emotions depicted in the images.
The researchers evaluate the performance of this approach on an "image-to-language-to-emotion" task, where the goal is to correctly identify the emotions expressed in the image based on the generated captions and the model's reasoning.
Critical Analysis
The paper presents a promising approach to the challenging problem of Emotional Theory of Mind, but it also acknowledges several limitations and areas for further research:
- The captions generated by the models, while more contextual than traditional approaches, may still not capture the full nuance and complexity of emotional scenes.
- The evaluation is limited to a specific dataset and task, and it's unclear how well the approach would generalize to more diverse and complex emotional scenarios.
- The paper does not fully explore the potential biases and limitations of the underlying language and vision-language models, which could impact the quality and fairness of the emotion recognition.
Further research could investigate ways to enhance the caption generation, incorporate additional modalities (e.g., audio, physiological signals), and rigorously evaluate the model's performance across a wider range of emotional contexts. Additionally, exploring the explainability and interpretability of the emotion recognition process could help build trust and understanding in these systems.
Conclusion
This paper presents a novel approach to the Emotional Theory of Mind problem in affective computing, leveraging the power of large language and vision-language models to construct narrative captions that provide rich contextual information for emotion recognition.
The combination of fast narrative descriptions and slower, more deliberative reasoning models shows promise as a way to achieve more human-like emotional understanding in AI systems. While the research has limitations, it opens up exciting avenues for further exploration in this challenging yet important field.
As AI systems become more ubiquitous in our lives, the ability to accurately recognize and reason about human emotions will be crucial for building trustworthy, empathetic, and socially intelligent applications. The work described in this paper represents an important step towards that goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
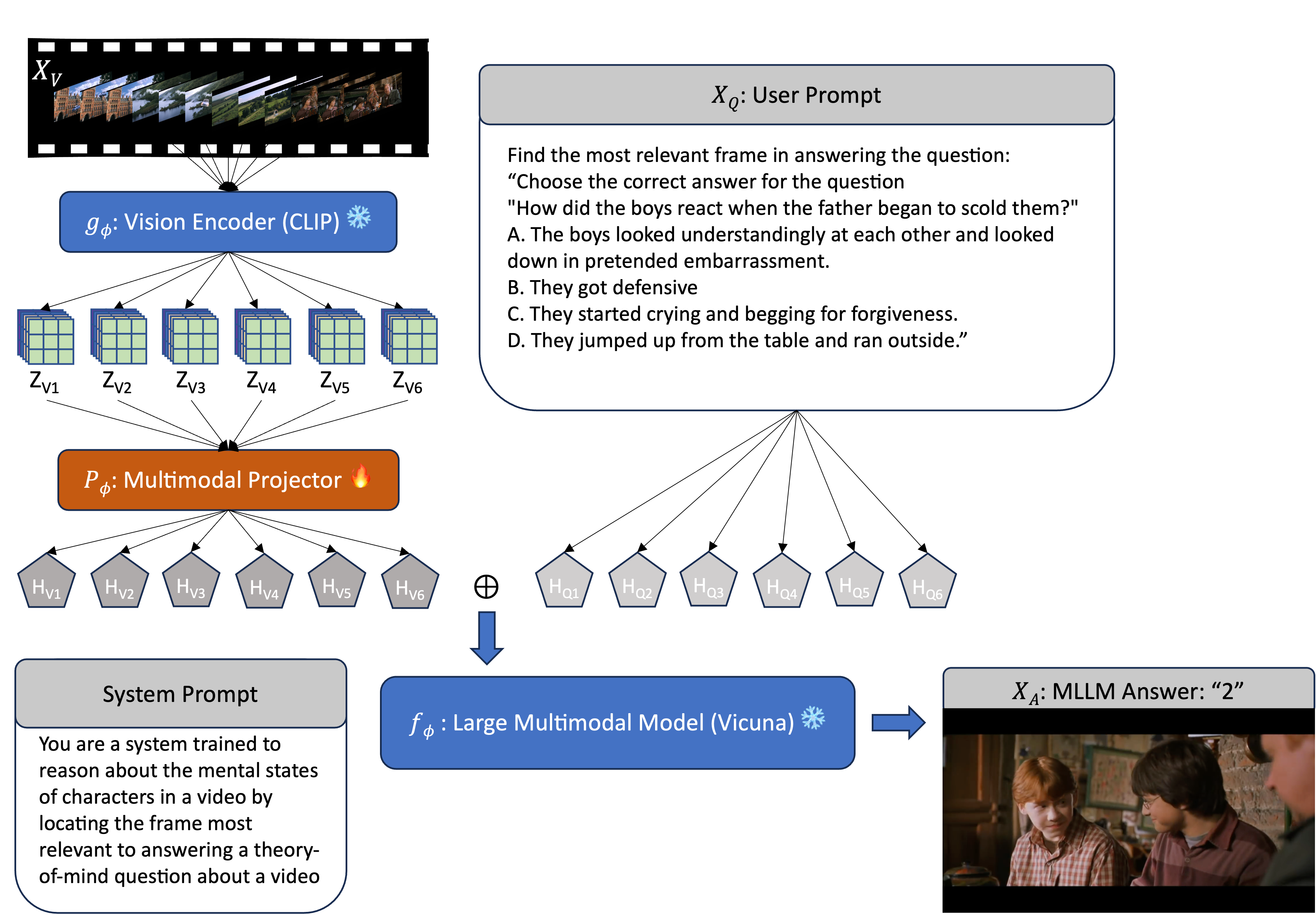
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Zhawnen Chen, Tianchun Wang, Yizhou Wang, Michal Kosinski, Xiang Zhang, Yun Fu, Sheng Li
0
0
Can large multimodal models have a human-like ability for emotional and social reasoning, and if so, how does it work? Recent research has discovered emergent theory-of-mind (ToM) reasoning capabilities in large language models (LLMs). LLMs can reason about people's mental states by solving various text-based ToM tasks that ask questions about the actors' ToM (e.g., human belief, desire, intention). However, human reasoning in the wild is often grounded in dynamic scenes across time. Thus, we consider videos a new medium for examining spatio-temporal ToM reasoning ability. Specifically, we ask explicit probing questions about videos with abundant social and emotional reasoning content. We develop a pipeline for multimodal LLM for ToM reasoning using video and text. We also enable explicit ToM reasoning by retrieving key frames for answering a ToM question, which reveals how multimodal LLMs reason about ToM.
6/21/2024
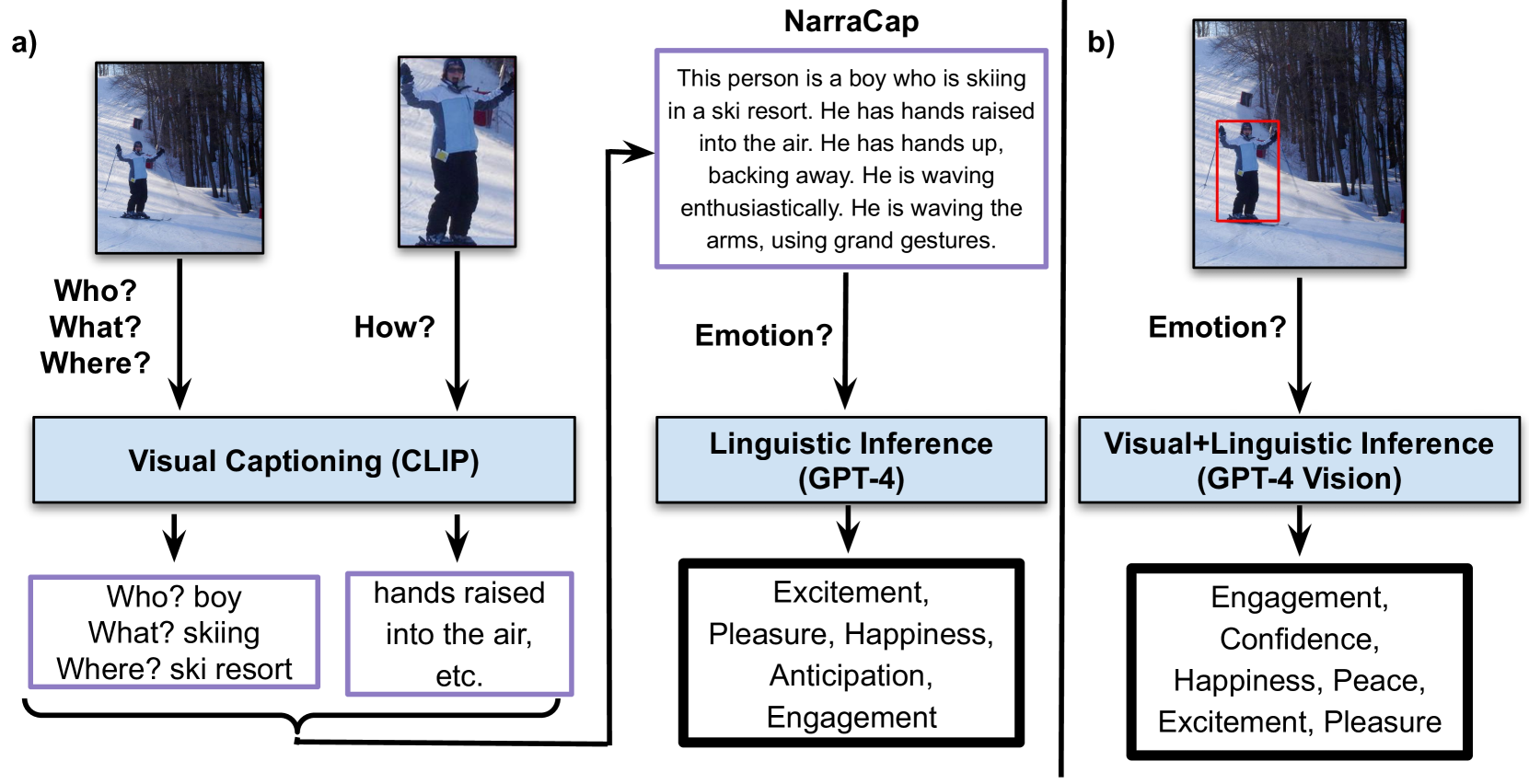
Contextual Emotion Recognition using Large Vision Language Models
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
0
0
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
5/16/2024

VLLMs Provide Better Context for Emotion Understanding Through Common Sense Reasoning
Alexandros Xenos, Niki Maria Foteinopoulou, Ioanna Ntinou, Ioannis Patras, Georgios Tzimiropoulos
0
0
Recognising emotions in context involves identifying the apparent emotions of an individual, taking into account contextual cues from the surrounding scene. Previous approaches to this task have involved the design of explicit scene-encoding architectures or the incorporation of external scene-related information, such as captions. However, these methods often utilise limited contextual information or rely on intricate training pipelines. In this work, we leverage the groundbreaking capabilities of Vision-and-Large-Language Models (VLLMs) to enhance in-context emotion classification without introducing complexity to the training process in a two-stage approach. In the first stage, we propose prompting VLLMs to generate descriptions in natural language of the subject's apparent emotion relative to the visual context. In the second stage, the descriptions are used as contextual information and, along with the image input, are used to train a transformer-based architecture that fuses text and visual features before the final classification task. Our experimental results show that the text and image features have complementary information, and our fused architecture significantly outperforms the individual modalities without any complex training methods. We evaluate our approach on three different datasets, namely, EMOTIC, CAER-S, and BoLD, and achieve state-of-the-art or comparable accuracy across all datasets and metrics compared to much more complex approaches. The code will be made publicly available on github: https://github.com/NickyFot/EmoCommonSense.git
4/11/2024

Do LLMs Exhibit Human-Like Reasoning? Evaluating Theory of Mind in LLMs for Open-Ended Responses
Maryam Amirizaniani, Elias Martin, Maryna Sivachenko, Afra Mashhadi, Chirag Shah
0
0
Theory of Mind (ToM) reasoning entails recognizing that other individuals possess their own intentions, emotions, and thoughts, which is vital for guiding one's own thought processes. Although large language models (LLMs) excel in tasks such as summarization, question answering, and translation, they still face challenges with ToM reasoning, especially in open-ended questions. Despite advancements, the extent to which LLMs truly understand ToM reasoning and how closely it aligns with human ToM reasoning remains inadequately explored in open-ended scenarios. Motivated by this gap, we assess the abilities of LLMs to perceive and integrate human intentions and emotions into their ToM reasoning processes within open-ended questions. Our study utilizes posts from Reddit's ChangeMyView platform, which demands nuanced social reasoning to craft persuasive responses. Our analysis, comparing semantic similarity and lexical overlap metrics between responses generated by humans and LLMs, reveals clear disparities in ToM reasoning capabilities in open-ended questions, with even the most advanced models showing notable limitations. To enhance LLM capabilities, we implement a prompt tuning method that incorporates human intentions and emotions, resulting in improvements in ToM reasoning performance. However, despite these improvements, the enhancement still falls short of fully achieving human-like reasoning. This research highlights the deficiencies in LLMs' social reasoning and demonstrates how integrating human intentions and emotions can boost their effectiveness.
6/11/2024